




我们谈过不少次的数据中心资源调度,现在回到单台机器,浅浅地看下内核的资源管理。Linux内核话题很多,但跟基础架构相关的话题范围其实有限,比如开发程序时,最关心的就是内存管理,而在数据中心架构时,最核心的就是IO调度。为什么这么说呢?因为CPU,内存都比较容易隔离,网络是个复杂的问题,需要单独看待,剩下就是IO了。许多云计算提供商在IO上解决的都并不好,传言阿里云这方面就不咋样? 本文这方面不做八卦,但IO难是公认的,难点就在于如何确保多租户环境下的隔离和公平。
IO调度器的任务主要包含两点:避免挨饿,以及确保不同进程间的公平分配。常见的IO调度器有NOOP,Deadline,以及CFQ等,当然也有一些另类的设计如BFQ(Brain Fuck Queuing)等。在本号之前曾经介绍的CFS调度器,当时在那篇文章里的概念出现了错误,因为CFS是进程调度器的范畴,而CFQ则是IO调度器,尽管它们的名字都是Complete Fair,算法也类似。在各种IO调度器中,只有CFQ是可以做cgroup隔离的,因此想尽量公平,默认只有CFQ可选。Cgroup是资源隔离的主要手段,不论是容器,还是虚拟机,都是借助于cgroup实现的隔离:
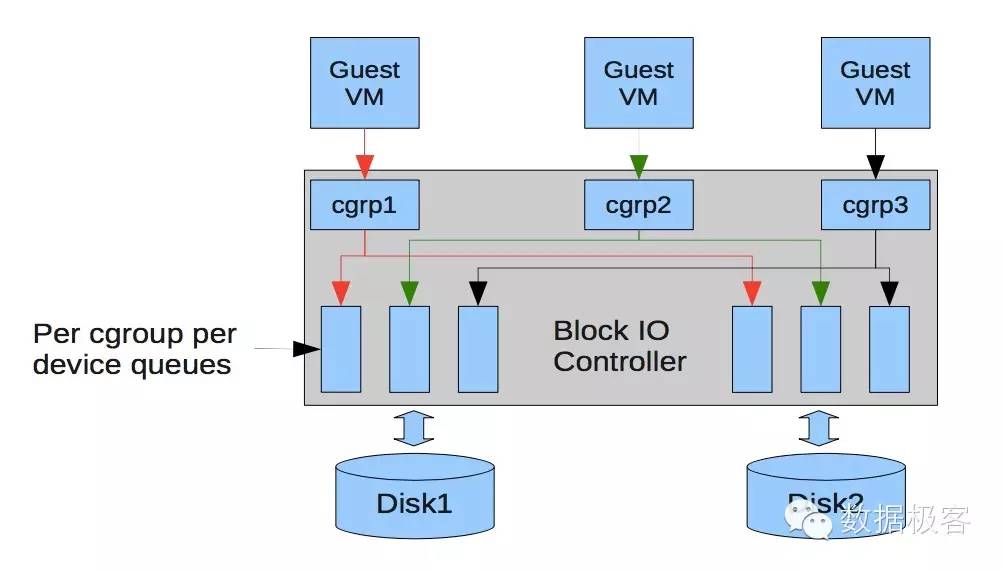
因此,说Docker,或者容器并不适合数据库云服务的原因是因为IO隔离没做好的说法并不准确——真实的原因其实是安全。
Cgroup的IO控制子系统叫做blkio,目前blkio实现了2种控制策略,一种是按照磁盘访问比例的权重,这是通过CFQ调度器实现的,另一种是throtting,既节流阀策略,主要用于指定IO速度的上限来限流。对于Buffer IO,throttings暂时是不支持的,CFQ也是无能为力的。因此顺道提一下Buffer IO是怎么回事:
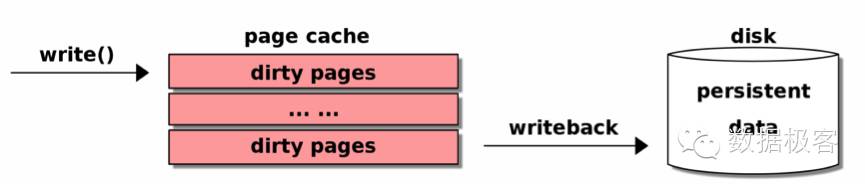
调用write函数后,Buffer IO首先把数据拷贝到page cache,然后由后台内核线程定期刷到磁盘,这个过程称为writeback。在3.2之前的内核,后台线程会检查脏页,超过比例后会出发同步刷盘,这种方式在HDD磁盘上会产生很多的随机seek,3.2之后的内核,如果进程产生脏页的速度超过限制,就让进程主动sleep,因此进程不会再出发同步IO。
CFQ根据配置,可以实现每用户,每组(cgroup)的IO隔离,不同的隔离对象分别有相应的队列,CFQ的公平就是在这些队列里进行分配请求来体现。
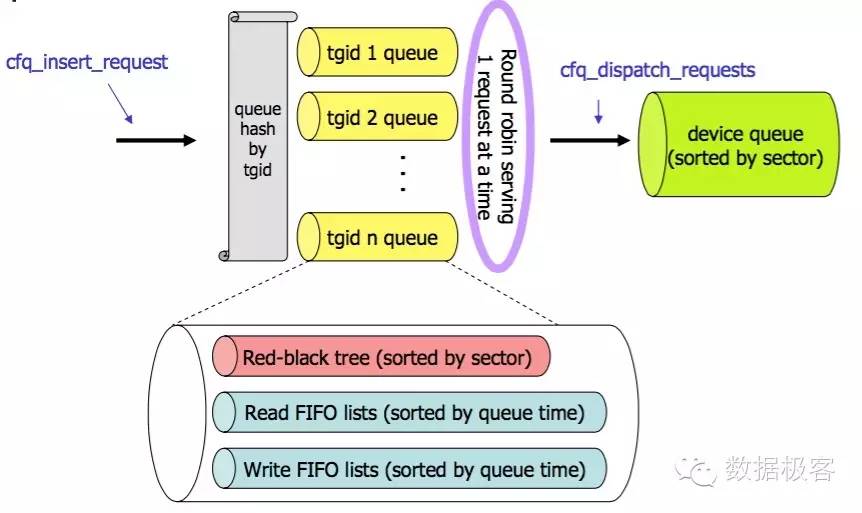
基本的CFQ设计是基于时隙的优先权调度。高优先权进程可以获得更大的时隙。使用高速存储时,时间度量变得不那么容易,因此最好合并多个请求,此时针对单个队列的时间度量就不那么精确。CFQ队列有一个要注意的地方在于它会保持一个空闲时间用来等待同一个队列的下一个请求。在空闲时间内,CFQ不会派发任何请求,即使其他队列处于等待状态。这是为了降低在HDD磁盘下的寻道时间,例如,如果一个进程正在进行顺序读取,那么不从其他等待队列派发请求过来就避免了磁头的变化。因此,CFQ是为HDD磁盘优化的设计,然而这对于SSD来说就是另一回事了,因为磁盘Seek操作对SSD不存在,因此预测未来的IO在附近产生对于SSD没任何意义,所以CFQ空闲时间会导致SSD上的吞吐量降低。空闲时间长度在CFQ中用"slice_idle"来配置。
在4.2以后的内核中,CFQ设计引入了自动的IOPS模式,如果存储支持NCQ(Native Command Queue,SSD都支持),并且设置slice_idle为0,那么CFQ内部会切换到IOPS模式,公平性以派送的IO请求数为基础衡量。这种模式仅针对组调度(CGroup)有效,对于非CGroup用户没有影响。把空闲关掉,切换到IOPS模式后,在SSD上的就可以提升吞吐量。
那么在4.2之前的内核,如何处理SSD上的多租户IO隔离与公平调度呢?阿里的做法是实现了一个简易的tpps,在Deadline调度器的基础之上增加了Cgroup IO隔离:通过类似CFQ的xxx_queue队列结构来记录各group的信息,针对每个group都创建一个list,存放从该group到来的IO,然后在dispatch IO时,用该设备的IO request容量减去已经发出但还没有处理完成的IO数,得出的就是该设备还可处理的IO数(就是Quota),然后根据这个Quota和各group的权重,算出各group的list上可以dispatch的IO数,最后,就是按照这些数去list上取IO,把它们发出去了。这样,就是按Cgroup的权重比例来发出IO了,而且,不像CFQ一个队列一个队列的处理,这个新调度器是拿到Quota后从每个group list里都取一定量的IO,所以也还保证了一定的“公平性”,同时,Quota是按照设备的处理能力算出来的,所以也能保证尽可能把设备打满。简单、按比例并发处理(准确的说,是公平处理),是tpps的设计初衷,然而tpps没有对发出IO 数和请求的总大小做统计,在策略上确实过于简单了,公平性事实上并不有效,在超高速的SSD设备上表现还好,但对于云服务来说,公平不能保障的调度确实是有问题的。当然,tpps是否真的用到了RDS服务还无法知晓,有说法是真实的RDS其实还是基于CFQ进行了修改,当然这些我们无从得知,tpps是从公开的信息上能够获悉的唯一针对多租户的隔离和公平进行的工作。
CFQ根据进程IO请求数来进行权重分配的策略在高并发IO负载(尤其是异步IO)下表现还好,因为不同虚机的IO基本上是公平的。但如果部分虚机没有高并发IO负载,例如采用同步IO的数据库,那么同步IO请求会跟大量异步IO阻塞很长时间造成延迟加大。采用throtting节流阀能够缓解这个问题,但这会导致整体资源利用率不高(原因很显然,想下就可以知道了)。Google近期公开的vFair调度器,根据延迟反馈和请求的情况来调整IO调度,是个高级的设计,然而我们没有办法得到具体的Kernel实现,因此对idea感兴趣的可以自行去看论文[1]。类似的设计其实在SmartOS的ZFS调度就已经出现,所以IO性能是Joyent的IaaS优于其他提供商的最主要原因。
[1] vFair: Latency-Aware Fair Storage Scheduling via Per-IO Cost-Based Differentiation. SoCC 2015
