




在公有云部署应用从来就是一种挑战,因为你不知道你的应用会受到其他虚机的什么影响,因此常常后果是把所有资源当作池子胡乱部署一气,Qos服务质量能否保证全凭运气,或者成了只能在轻负载下使用。下图展现了两类应用(批处理和低延迟)的代表Hadoop和Memcached在AWS和GCE上的性能评测,可以看到,越是顶配的节点,受到混排干扰的可能性就越小,其性能就越具备可预测性,反之,由于混排导致不论是吞吐量,还是延迟性能,都很难具有可预测性。

在公有云上成功部署大访问量的成功先例并不多,这里边Netflix是最值得借鉴和学习的一个——当然,尽管AWS对于他们来说就是黑盒子,但还是进行了架构和系统上双重的努力,例如在早期,他们尽可能租用顶配的EC2确保自己的节点跟别人不会出现干扰,除了高度伸缩,高度自愈,以及自动部署的基础架构之外,在13年还从Joyent挖来了Brendan Gregg作为Performance Architect去不断解决遇到的各类性能瓶颈。提起Brendan Gregg可能很多人并不知晓,但提起下面的著作,不少资深的后端工程师就知晓了。除此之外,Brendan Gregg曾经是超级操作系统Solaris的资深性能调优专家,非常建议每个基础架构的从业人员深入阅读Gregg的著作。

随着Borg为世人所知,混排一词变得热门起来,你可以用colocation以及interference寻找到很多研究成果。一时间,以Borg为参考,以提高数据中心利用率为目标的工作,也在一些有进取心的开源项目及其相应生态系统中热火朝天地展开。翻遍本号,你可以找到Firmament,Fenzo,Aurora等这样的字眼,你甚至可以找到Heracles这样把数据中心平均CPU利用率从Borg的30%提升到90%的神器(点击原文可以阅读)。
不论是Borg还是Heracles,尽管它们在提高利用率上的工作非常出色,但是它们取得成果的关键都在于整个数据中心,低优先级的批处理任务所占的比例有多少。在数据中心经常会把任务分为两类:高优先级的低延迟任务和低优先级的批处理任务,前者针对延迟敏感,后者则是以吞吐量为评价标准。对于前者来说,绝大多数的在线业务,比如web应用,中间件,缓存,数据存储,乃至搜索引擎都属于该类,对于后者来说,大数据,以及一些分析型任务,background job等等属于这类范畴。Borg/Heracles成功的关键,在于让这两类任务混排——尽管它们之间天然存在互斥,延迟敏感型的任务常常会受到批处理的干扰而产生众多尾延迟(Tail Latency)。尤其的,Heracles建议在单台物理机上只部署1个延迟敏感型任务,其余均为批处理任务,并提供多种机制确保前者的服务质量。换句话,它们主要针对如下图中的静态划分来解决资源浪费的问题:
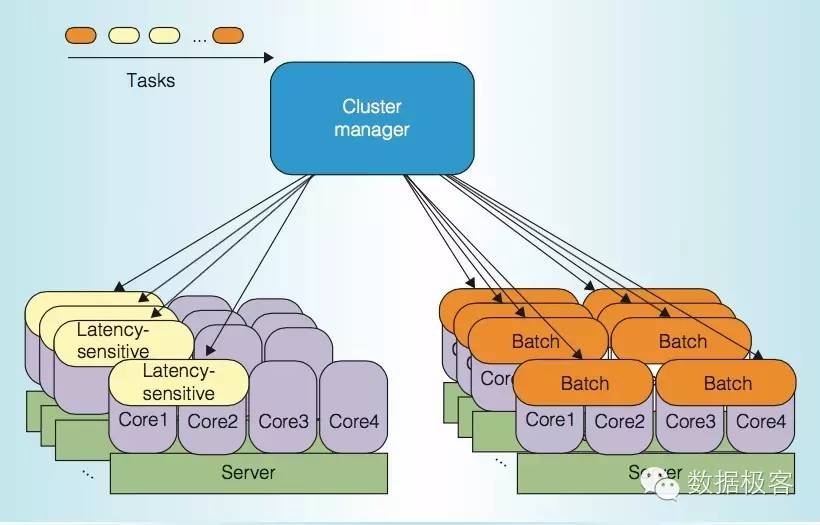
那么,我们能否把多个低延迟任务混排乃至填满?为什么Borg没有这样选择?这是因为不同的资源管理需求会有差别,对于Google来说,应对突发峰值是重要的设计需求,这种调度策略下批处理任务只能分配到很小的资源缝隙,遇到突发流量,不仅批处理本身会有问题,也会影响同机的其他业务。因此,是否低延迟和批处理混排,一定要针对自己的需求来考虑——当然,这种混排目前也只有Google能够大规模运用而已。
单就混排本身来说,不论是两类任务之间,还是低延迟业务之间,都会需要考虑干扰的来源对业务的影响,这在公有云,或者Netflix的场景下经常会遇到。在[1]的工作中,混排干扰的来源SOI(Source Of Interference)总结共包含如下种类:内存容量,内存带宽,存储容量,存储带宽,网络带宽,LLC(末级缓存)容量,LLC带宽,L2缓存容量,L2缓存带宽,L1 i-cache(指令缓存),L1 d-cache(数据缓存),TLB,整数处理单元,浮点处理单元,指令预取器,多核连接通道,向量处理单元(SIMD)等15种。根据试验表明,这些混排干扰源之间的影响几乎是独立的。这个结论非常重要,这意味着不同bound的应用可以在一台物理机上相互干扰不受大的影响。这个结论跟我们印象相反:通常当我们的主机遭受IO瓶颈时,连登陆都很难操作,更不要说跑一些纯耗CPU之类的应用了。这种情况有很多原因,例如可能网络带宽已经被跑满,可能操作系统内核调度器导致很大延迟,如果利用cgroups做好隔离,确实是可以混跑的。
在这么多干扰源头SOI独立的前提下,应当如何来编排应用呢?如果应用本身的资源消耗可以分治,那么问题很容易简化称为装箱算法,SOI独立的结论证实了以装箱算法(BinPacking)针对不同维度混部资源的合理性,例如Netflix的Fenzo,就是在Mesos下针对装箱算法的封装库。然而实际情况中,应用的资源消耗常常是复杂和未知的,那么有没有办法处理呢?Paragon[2]引入了类似推荐引擎的做法,不同于协同过滤中用户和的偏好学习,Paragon通过之前调度的参数学习应用程序的偏好。Quasar[5]也采用了类似的思路,并且声称将会合并到OpenStack以及Mesos中用于资源调度,[6]则是Quasar系统在Mesos中的一个参考试验。
此外,[3]的做法是把服务器资源按照两类任务混合编排:一部分是资源预定,就是预先分配好用于长期运行的虚机或者容器,另一部分则按需求分配,主要用于短时任务。这种做法跟Borg很类似,但在具体的资源调度上,并没给出切实可行的建议。[4]的做法是通过简化的试验验证低延迟任务和批处理任务混排的效果并进行打分,便于给出两类任务混排的量化指标。
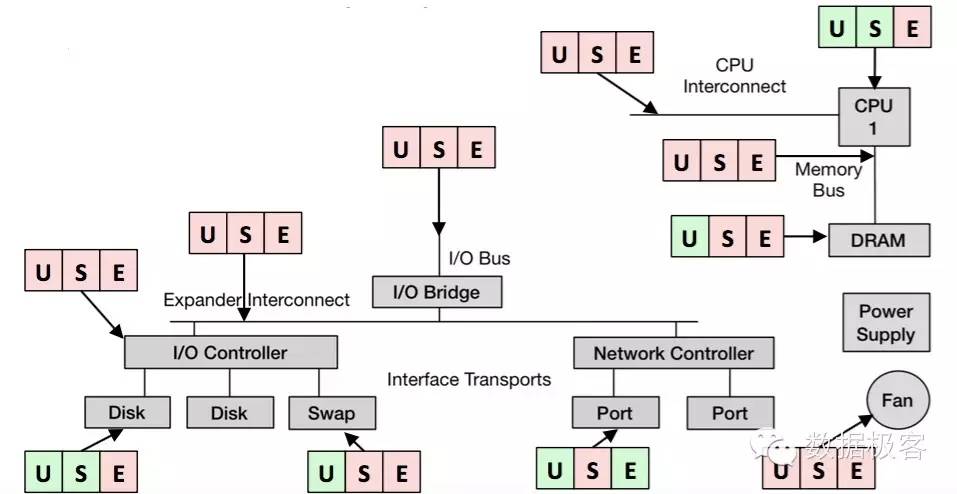
这些基本上是近些年来除Borg之外解决混排的主要成果了,可以看出对实际中的问题仍然缺乏直接意义的指导。因此,我们还是没有办法来做到拥有一个工具就一劳永逸的解决问题,还需要具体情况具体分析。Brendan Gregg曾经在优化的经验中总结了一套USE方法,供性能分析人员在实际情况中使用,具体就是:在所有SOI出现的地方,尽可能的评测获得3种数据:
U:Utilization,代表资源的平均使用时间
S:Saturation,表示资源的等待时间,通常用排队长度情况表示
E:Errors,表示发生错误事件的次数
Gregg还在给出了评测常见USE指标的工具[7]。在实际使用中,性能分析人员需要针对每个环节获得USE数据以决定当前系统的数据从而给资源预留提供依据。
[8]的工作对于混排的理解是总结性文献,在其中,混排给任务造成的延迟被归结为三种:
排队延迟:排队延迟在任何一个计算资源都可能遇到,CPU,内存,网络,存储,以及它们之间相互连接和内部连接的控制器。排队延迟天然就存在,即使没有混排任务的存在,排队延迟也同样具有。排队延迟是吞吐量和负载的函数。
调度延迟:通常当有很多任务竞争CPU资源时,操作系统内核需要针对任务进行调度,这会引来两种延迟,一种是调度器等待时延,另一种是上下文切换时间。
负载不均衡:在多线程程序中,线程池的线程负载会有差别,这是导致尾延迟(Tail Latency)的重要原因。混排时,这种不均衡会加剧,例如拥有硬件资源的线程被阻塞更长时间。
文献[8]对于混排的工作有一个直接的参考:它阐述了为什么Linux内核默认的CFS调度器在云计算中并不适合,因为CFS是引发调度延迟的重要原因之一,只有在低负载情况下,CFS才不会引发长延迟。作为对比,经过试验后推荐了BVT调度器(Borrowed Virtual Time)[9],对于长期运行的低延迟任务,可以提供更低的调度延迟保证,这些工作是值得去实验的。
[1]iBench: Quantifying Interference for Datacenter Applications
[2]QoS-Aware Scheduling in Heterogeneous Datacenters with Paragon
[3]Optimizing Resource Provisioning in Shared Cloud Systems
[4]Increasing Utilization In Modern Warehouse-Scale Computers Using Bubble-Up
[5]Quasar: Resource-Efficient and QoS-Aware Cluster Management
[6]https://github.com/att-innovate/charmander
[7]http://www.brendangregg.com/USEmethod/use-linux.html
[8]Reconciling High Server Utilization and Sub-millisecond Quality-of-Service
[9]https://gist.github.com/leverich/5913713
