




CAP理论对于分布式系统的设计者是常识,但是这个常识常常导致误用,许多系统设计者在没有达到系统边界时就喜欢以CAP为借口为自己的应付差事买单。Abadi曾经建议修改CAP理论为PACEL,意思就是在网络分区存在的情况下P,系统设计需要考虑A和C,否则(E),则需要考虑延迟Latency跟事务的关系(L)。
那么,ACID跟高可用到底有什么关系呢?Bailis在其文章中证明,事务隔离级别,从高到低的顺序一致Serialibility,快照隔离SI(Snapshot Isolation),重复读RR(Repeated Read),如果事务达到这些隔离级别,那么是没有办法达到高可用设计的。然而,更低的隔离级别RC(Read Commited),RU(Read UnCommited),等,在达到这些事务级别的前提下是可以同时做到高可用设计的。
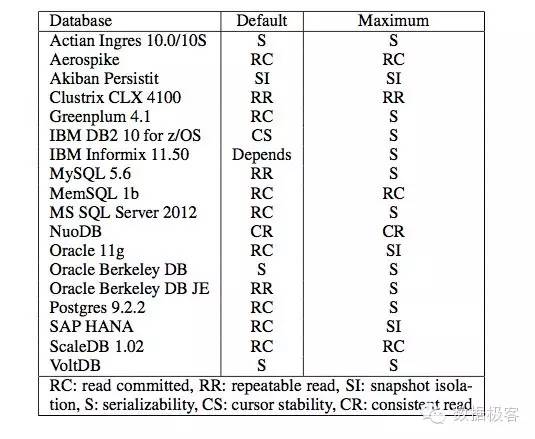
高级别的事务隔离无法做到高可用,因为这些事务隔离级别需要进行并发更新的冲突检测,需要进行锁的操作,而锁的操作在多副本情况下是不可能实现只有个别副本的失败的。因此,分布式数据库必须在可用性和强一致语义之间做出选择。然而,即便是非分布式的数据库,因为协调而带来的性能损失也可能很严重,会导致并发下降,因此,为了增加并发能力,这些数据库系统也提供了较弱的ACID级别,例如图中的各种数据库,不论是RDMS,还是NoSQL,亦或是NewSQL,只有3个提供了最强的ACID事务隔离级别。
RU(Read Uncommitted)是最低的隔离级别,含义为在每个对象的写入都是有序的,但可能读到他人未Commit 、可能被Rollback的脏数据,即脏读。在分布式数据库里,不同副本可能在不同时间接收到写入本地拷贝的请求,但需要按照全局顺序处理并发更新的请求。RU的语义阻止了"脏写"的发生。例如下面的例子:
T1:w(x=1)w(y=1)
T2:w(x=2)w(y=2)
在RU隔离级别,不可能出现T1的w(x=1)在T2的w(x=2)之前,同时T2的w(y=2)却在T1的w(y=1)之前的顺序。RU可以通过在每个副本上用时间戳标记每个事务的写入请求,并且利用"最后写入者获胜"的冲突检测机制来实现,因此实现RU级别的高可用事务很容易做到。
RC(Read Committed)是大多数数据库的默认事务隔离级别,含义为只能访问到提交的数据,任何中间状态的数据都无法读取和写入,因此,RC禁止“脏读”和“脏写”的发生。但事务内重复读一条数据,可能得到不同的结果,即Non-Repeatable Read。如下事务执行例子中,在RC隔离级别下,T3将永远不可能读到a=1的情况,如果T2中途退出,那么T3也不应当读取到a=3。
T1:w(a=1)w(a=2)
T2:w(a=3)
T3:r(a)
对于高可用事务来说,很容易通过RC的语义阻止"脏读":如果每个客户端不会写入未提交的数据到共享区,那么事务也就不会读取任何客户端的脏数据。在具体实现上,可以很容易通过客户端缓存写入请求直到提交来实现。
一些高级别的事务隔离机制如RR(Repeated Read),快照隔离SI,需要对一些出错场景做出处理,例如Lost Update和Write Skew,分别说明如下:
Lost Update定义为当事务T1读取记录的同时,事务T2也在更新该记录,那么T1根据它所最开始读取到的结果来进行相关的更新操作,这样T2的修改就会丢失。在高可用事务中,无法避免这种情况的发生。例如两个客户端均对记录x进行如下事务操作:
T1:r(100)w(100+20=120)
T2:r(100)w(100+30=130)
不管副本选择的是x=120还是130,数据库的状态都无法做到串行执行的语义。为了避免这种情况的发生,T1和T2之一不能提交。
Write Skew是Lost Update针对多条记录的扩展。当事务T1读取记录x,事务T2读取不同的记录y,那么T1对y的写入和提交时,以及T2对x写入和提交时,就会发生这种情况。
高可用事务无法处理这两种错误处理场景,因此RC就是做到高可用事务的处理边界。针对数据库事务的描写,至今在Wikipedia上也只能看到如下4种:RU,RC,RR和Serializable,这其实与当下的数据库技术已经不符合了,因为这4种隔离级别都是基于锁的并发控制场景描述的,而当下数据库主流已基本选用MVCC多版本控制,因此才会有了快照隔离,顺序快照隔离等等新的隔离级别术语。
MySQL中最低的隔离级别是Read Committed,但并不会出现Phantom Read;Repeatable Read其实是快照隔离;只有Serializable是完全基于锁的;PostgresSQL实质上只有两种隔离级别:RC和Serializable;而Serializable是基于MVCC的无锁实现,即Serializable Snapshot,相比快照隔离只牺牲一点性能,但彻底杜绝了出错的可能性;实现机制可点击原文阅读本公众号之前的文章。
基于MVCC的快照隔离级别看起来很美,在开始事务的一刻拍下快照,不会出现Non-repeatable read和Phantom Read;但是它也有它的 “症状” 而导致Write Skew:对一张表的多行数据的并发修改满足隔离性,一旦存在冲突的写入,会触发回滚;如果涉及以多张表返回的结果计算出新结果,写入另一张表,则容易出现Write Skew,所以不能期望加了一个事务就万事大吉,而要了解每种隔离级别的语义。涉及单行数据事务的话,只要RC+乐观锁就足够保证不丢写;涉及多行数据的事务的话,Serializable隔离环境的话不会出错,但是你不会开(因为锁会降低性能);如果开快照隔离级别,那么可能会因为 Write Skew 而丢掉写。更糟糕的是,Write Skew 如果存在写冲突,不会触发Rollback,而只是默默地把数据弄坏。这时,就要求我们在读取来自两张表的数据时,手工上锁。PostgreSQL意识到快照隔离级别反而更容易出错,但是针对快照隔离级别的特定几个错误场景做检查的话,即可以较低的开销保证正确性。它以略高于快照隔离的开销做到Serializable,可以放心使用。在互联网业务中,对一致性的要求往往没有太高,一般不需要特别高的隔离级别;与其在意隔离级别,可能会更多在意主从不同步造成的脏数据和缓存的不一致。如果是金融业务,尽量不要用MySQL,可以考虑PostgreSQL的Serializable Snapshot。
