




Yarn从问世开始主要服务Hadoop生态系统,但也在朝着数据中心操作系统的路上演进。本文列举一些这方面的相关工作,但并不是充分调研后的结果,因此可能会有疏漏。
在上一篇公众号文章中,我们从Malte的访谈中获悉微软研究院基于Yarn做的分布式调度器Mercury,这对于Yarn来说是个重大改进,意味着Yarn也开始向Omega类似的设计演进,通过不同调度策略的组合来提升资源的整体利用率。微软的改进已经提交给社区,因此这些工作不是单纯的学术研究。Mercury力图实现分布式调度器,因为集中式调度器在伸缩性,调度延迟方面存在问题。
先回顾一下Yarn的主要组件:
RM(ResourceManager):中央组件,负责处理集群资源请求。RM支持可插入式调度器,如目前的Hadoop容量调度器,以及Hadoop公平调度器。
NM(NodeManager):每个机器运行的后台进程,周期性把心跳信息告诉RM。
AM(ApplicationMaster):每个Job都有一个AM,可以编排自己的工作流程。
Mercury的结构如下图所示。Mercury修改了一些AM,如Hadoop AM,使得它们可以提供任务消耗时间的估计,这些信息用来对可用资源容器排队,为了更加精确,AM需要不断进行估计。Mercury Coordinator运行在RM中,负责收集这些时间,并通知NM相关信息,Mercury Coordinator负责动态地均衡整个集群负载。在NM中实现了Mercury运行时,负责处理在AM和Mercury调度器之间的容器分配请求,以及截获并处理来自AM的执行语义,例如图中的startContainer。
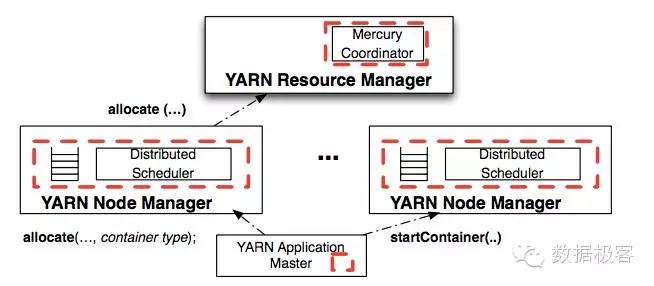
Mercury的进展在JIRA里的YARN-2877可以看到。下边谈一下Mercury的调度算法。整个Mercury的设计目标是通过引入分布式调度设计,使得不同的调度策略可以方便的嵌入到同一个集群中,从而能够扩大集群的吞吐量,提高集群使用效率。不过,Mercury 并没有过多考虑低延迟业务的调度。在调度算法上,Mercury区分两种不同的资源分配,"保证"和"配额"。前者仍然是通过旧Yarn的集中式调度器来进行,因为已有的公平或者容量调度器已经可以稳定工作。只有系统确定节点能够完全满足资源需求时,才会选择这种分配策略,被这种方式调度的任务不会被抢占。后者则是通过Mercury新增加的分布式调度器来实现,它收集来自Mercury Coordinator的负载信息来做出调度决策,然后根据最小化排队延迟的策略将任务在执行之前放入队列排队等候,每次分布式调度器会选择排队延迟最小的top-k节点,同时考虑数据的局部性原则。为最大化集群使用效率,Mercury会在多个分布式调度器的队列之间进行动态re-balance,队列任务的执行顺序调整,以及抢占,这些都是根据Mercury Coordinator不断收集各任务的执行时间估计来完成的。
Mercury并没有解决长期运行的低延迟服务类业务的调度,Slider项目则用来是解决该问题。它负责把这类服务部署到Yarn平台之上,但是这并不表明从此就可以没有问题的运行在Yarn集群之上,因为引入长期运行的服务会带来如下问题:
资源竞争与饿死问题:当一个集群中只存在批处理作业时,资源调度是很容易做的,因为资源释放和申请是不断在进行中的,任何资源的申请都可以得到满足。但存在长服务后则不同,比如一个作业需要10G内存,目前没有任何节点存在10GB内存,为了避免永远拿不到资源,调度器会找一个存在部分资源的节点,比如node1存在6GB内存,则会为该作业预留着,一直等到再次释放出4GB,则将node1上的10GB内存分配给该作业,整个过程在批处理场景中能自然的发生,一旦加入长服务后,则可能产生饿死现象,也就是说node1上的4GB内存可能永远等不到,因为可能被长服务占着。在这方面,Borg/Omega做得很好,但Mesos和YARN目前无法解决。
服务高可用问题:资源管理系统一旦支持长服务后,应保证系统服务出现故障时,上层的长服务不会受到应用,比如在YARN中,RM或者NM出现故障后,其上运行的长服务不应受到影响,到恢复后,重新接管这些服务。这一点,目前Yarn已经可以支持。
服务发现:长服务部署到资源管系统中后,可能被调度运行到任意一个节点上,为了让外界的访问者(客户端)发现自己的位置,需要有一个服务注册组件登记这些长服务,Borg/Mesos/YARN均对服务注册有支持,Mesos可通过上层框架,比如Aurora,YARN内核内置了对服务注册的支持。这个特性在Yarn中可以从YARN-913(Add a way to register long-lived services in a YARN cluster)的进展来获悉。
资源伸缩:长服务运行一段时间后,由于访问量的增加或减少,可能需要动态调整所使用的资源量。资源伸缩有两个维度:一个是横向的,即增加实例数目;另一方面是纵向的,即原地增加正在运行实例的资源量。其中横向支持是通过上层框架实现的,而纵向支持是通过资源管理系统内核支持的(YARN-1197)。
日志收集和滚动长服务永不停止:为了方面排错和监控,长服务的日志收集也是需要解决的,比如Mesos中的Aurora和Marathon都可以解决,Slider解决了日志收集的问题,滚动长服务的进展在YARN-896这个issue中。
我们知道腾讯基于Yarn实现了自己的集群资源调度系统Gaia并应用于万台物理机的大型集群,如下图中间部分就是Yarn。
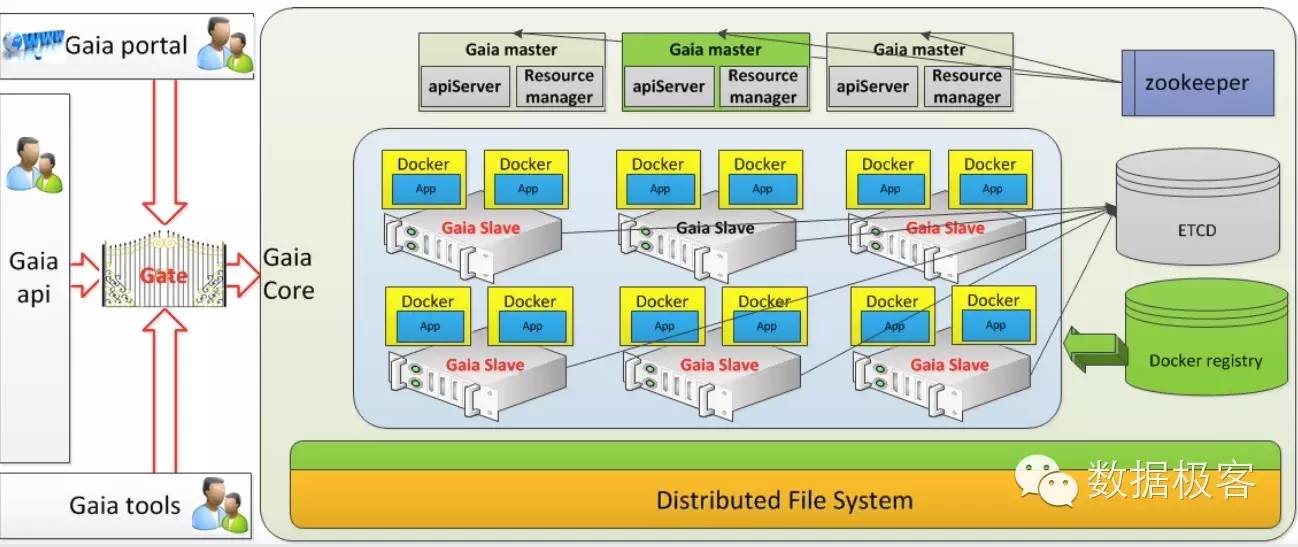
Gaia的调度算法sfair是腾讯自己实现的,目的是资源分配公平,并且支持低延迟型任务的抢占,目前,我们尚不得知sfair的调度实现细节。
Mesos/Yarn/Kubernetes,三个项目都在向着数据中心操作系统的方向演进,但距离理想的程度都还有距离。从数据中心操作提供这个角度来看待它们的成熟度,Mesos最高,但也不代表未来它就是终极解决之道,对于基础架构的演进来说,恐怕唯一不变的,就是变化了,所以基础架构设计人员,不得不对每个系统的内部设计保持足够的理解,能够持续跟进项目最新的进展,并且对任何发展都保持着开放的心态。
