




MDCC(Multi-Data Center Consistency)多数据中心一致性协议是Berkeley大学AMPLab(就是做Spark的那个)专门针对跨数据中心处理发明的分布式事务协议。
为数据库提供分布式事务,尤其是跨数据中心的分布式事务,2PC两阶段提交是绝大多数类似系统所采用的机制,但这会引起问题,尤其是在跨数据中心的环境下。因为2PC依赖于独立的协调者节点,一旦该节点出现问题,就会阻塞整个系统的事务运行。还有一些做法是采用Paxos做为全局日志来提供状态机复制,例如Google的Megastore,它的做法是针对不同分区的每次提交都采用Paxos选举来决定日志中存放的位置从而确保每个分区的全局时序,因此系统每个分区同时只能执行一次事务,导致性能不佳。Megastore的下一代Spanner引入了时间戳提供跨机房分布式事务(快照隔离级别),但在单分区内仍然需要Paxos来操作日志,因此分区内事务性能仍然存在瓶颈(当然比Megastore要好很多因为机房内的延迟要远远低于跨机房);此外,Spanner的跨分区部分仍然依赖于2PC两阶段提交,因此2PC的缺陷依然保留—协调者的单点问题,以及两轮消息传送导致的过长延迟。
MDCC是一种乐观协议,可以用接近最终一致性的代价提供事务能力。MDCC协议可以支持各种事务隔离级别,默认情况下是RC(ReadCommitted),这是一种相对较弱的隔离,但MDCC的默认比RC级别要强一些:它可以保证事务内的所有更新请求的原子性,并且针对单个记录的并发更新可能会失败退出(至多只有一个事务能够成功),所有未成功提交的事务都是不可见的。MDCC的延迟低于2PC,并且并不需要独立的协调者节点,也没有对系统设计的限制。MDCC采用跟Megastore和Spanner类似的架构,状态层作为分布式存储,上面加一个无状态应用层负责事务处理,因此它可以用在任何KV引擎上。
在架构上,MDCC可以利用Multi-Paxos协议用来支持RC级别的事务隔离,具体做法是,每个记录都利用Paxos来接受一个选项,而不是直接写入值,在应用层获悉事务所有记录的选项之后,提交事务并异步通知存储层执行选项操作。Multi-Paxos协议是针对经典Paxos协议的一个优化,后者需要2条消息才能达成一致,而Multi-Paxos协议通过指定多个Master节点的存在可以省略一条消息。应用层获悉事务所有记录更新的操作选项集合,每条记录的更新都会创建版本号,因此操作选项集合以<Read版本号,Write版本号>的Pair形式写入,前者是事务写入前读取的记录的版本号,后者是该事务此次生成的版本号,有了这些Pair集合,MDCC就可以根据Read版本号来判定出写-写冲突。
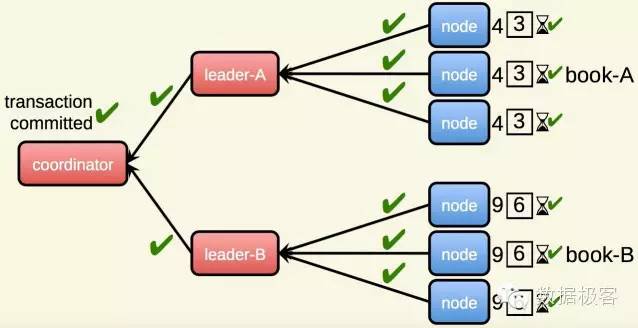
由图所示,不同的分区都有自己的应用层服务器负责事务管理。每个存储层节点都向应用层服务器告知事务更新操作选项是否被接受,当获悉所有的选项都已经被接受之后,事务提交成功,有任何选项被拒绝,事务提交失败。跟2PC不同,MDCC的决策由所有的存储层节点依据Read版本号作出,而2PC则是独立的协调节点,因此MDCC不会陷入单点导致的阻塞整个集群的问题。在使用经典的Paxos算法(包含Multi-Paxos)时,上述消息传递需要2轮,第一轮进行Leader的选举,第二轮则进行值的更新操作;而MDCC引入了Fast Paxos,可以绕过Leader节点,在冲突很少的情况下这会提升吞吐量
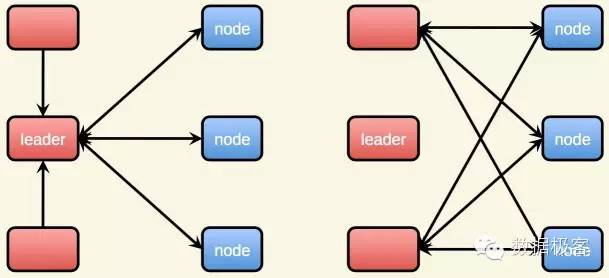
参见上图,左边是经典的Paxos,在进行写入操作时,首先从节点中选举出Leader,而右边的Fast Paxos则直接跟节点交互,当存在并发冲突时,这时才引入Leader节点来解决冲突。因此,MDCC是乐观协议,在针对同一条记录的并发更新很少的场景下工作会更加良好。
目前,不论是Paxos,还是时间戳,实现分布式事务,都通过某种机制来做到全局时序,在吞吐量上会有限制。而且2PC在绝大多数协议上都会依赖,存在单点问题。MDCC提供了分布式事务处理的另一种选择,不仅没有2PC的单点依赖,而且还可以通过Fast Paxos减少消息传递降低延迟,因此是一种跨机房强一致协议,在Github上可以找到MDCC的实现,属于原型阶段,值得实现分布式事务的基础架构研发者们参考。
