




Change Data Capture(CDC)算得上是数据库领域里一个架构设计模式,就是通过捕获数据库里的数据变化,来让这些数据为其他组件使用。例如,当在异构组件之中整合数据时,CDC是重要手段之一。在为数据库提供缓存时,数据一致性也是经常令人讨厌的地方,可以借助CDC来把数据灌入缓存。
CDC在工作时,需要能够捕获数据库的数据变化,最容易的做法是通过触发器来实现,但这样会影响数据库的性能,以及增加数据库的开销,并且不能做到实时捕获。更好的做法是导出数据库的日志,例如MySQL的Binlog,Oracle的GoldenGate,MongoDB的Oplog,CouchBase的changes feed,等。PostgreSQL在9.4版本之后提供了“logical decoding”的功能,可以用来实现实时捕获PostgreSQL的数据变化。Linkedin的Databus和Facebook的Wormhole是比较知名的的大型互联网公司在相关方面的工作,其中前者是开源实现。Wormhole在Facebook内部用来跨数据中心地串接起各种数据组件,例如TAO数据库(基于MySQL的分布式图数据库),Memcached缓存集群,Unicorn社交图谱搜索引擎等。因此,从架构上看起来,这非常类似于一个数据库日志读取组件+分布式日志系统(例如Kafka)的组合。
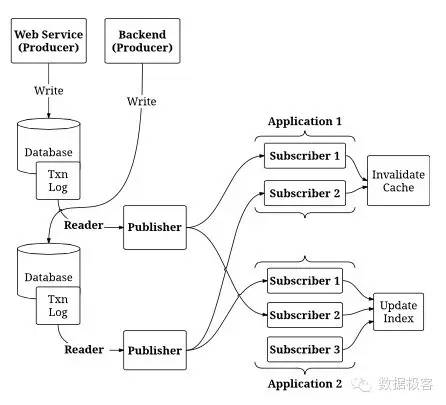
Linkedin的Databus在实现机制上针对低延迟复制考虑更多。CDC捕获数据变化后,首先输出到内存组件,如果存在其余类似数据库,甚至数据库副本,都可以通过读取该内存组件的数据来达到近实时的最终一致性。Databus还另外设计了Bootstrap组件用于实时性要求不高的数据复制,以及保存用于崩溃恢复的快照。
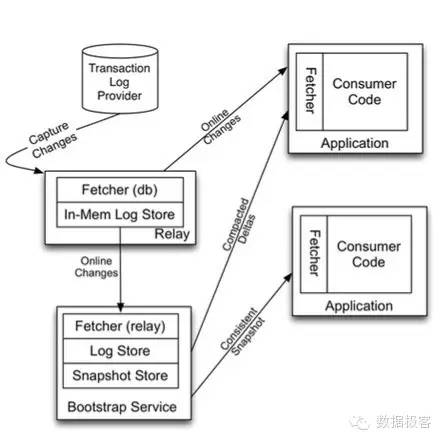
Linkedin造了Kafka和Databus两个轮子,都是用于日志传输的,那么两者到底有什么关系呢?也没搜索到相关答案,事实上,辅助以CDC数据捕获组件,再加上Kafka,那整个系统跟Databus的确非常类似,主要区别仅在于一致性的延迟。Confluent(就是那个做Kafka的团队的创业公司)基于PostgreSQL 9.4版本的特性,以及利用Kafka的消息队列的日志压缩和AVRO序列化格式,同样提供了实时CDC解决方案。
CDC系统的另一个重要用途在于,由于数据库本身的日志是单机非高可用,因此基于它做数据库集群是非常困难的,我们可以看看淘宝的MySQL高可用集群:
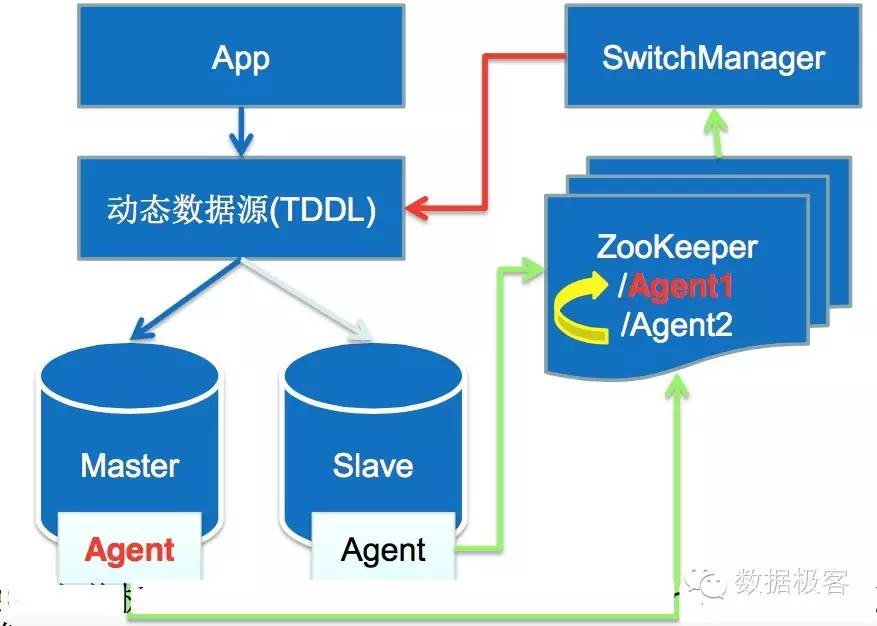
利用Zookeeper切换MySQL的主从,但由于主从的Binlog并没有统一的存放地点,导致切换逻辑复杂,需要在主从节点之间做多次relay以确保数据一致。如果有统一的分布式日志存放系统,那这样的问题处理就非常容易。从另一个角度来看,具备Linearizability的分布式日志,是多么有价值的轮子。
