




我们之前介绍的搜索引擎的几种玩法,都是倒排索引。另一种倒排索引的玩法,在本公众号“一种神奇的数据结构—小波树”一文中有提及,就是把倒排索引的Posting List全部连接在一起放到小波树中,这样我们可以获得Log复杂度的索引构造,点击阅读原文可以温习。 本文则继续扩展搜索引擎的其他玩法,毕竟,这个世界不是只有倒排表可以做搜索引擎。
第二种有趣的索引表示叫做Treap,又称作笛卡尔树。作者做出这种创新的仍然源于针对succinct数据结构的研究。一个笛卡尔树如下图所示,从左到右,文档ID按增序排列;从上到下,权重(这里是词频)按降序排列。
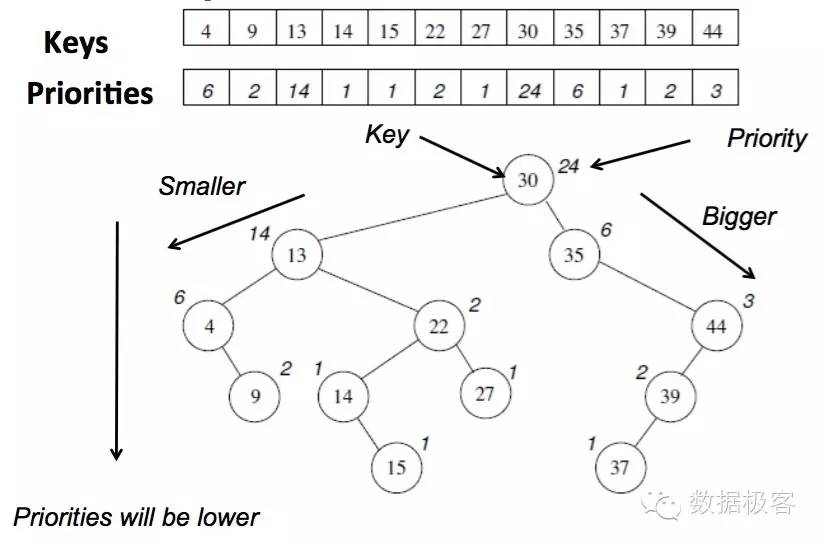
具有最高权重的文档则位于笛卡尔树的根节点,因此在进行求交或者TopK查询时,只需要从上到下按照权重降低的方式遍历树,因此,这是一个具备Log复杂度的精巧索引设计,非常适合TopK检索。对于长度为n的序列,Treap可以以O(n)的开销构建,同小波树一样,这仍然是个静态结构,对于增量索引并没有太好的手段,但是,有这2种Log复杂度的数据结构提供TopK检索,在某些非频繁更新的场景下具备更大优势,基础架构工程师手中的武器越多就越有优势,不能总是被平常的,通用的手段蒙蔽了视野。
最后我们谈论一下Self Index,兼谈论Preferred Infrastructure公司。熟悉笔者的人都知道,这家公司从12年唠叨至今,做为一个只拥有不到20名工程师的日本小公司,为何在各大山头林立的互联网丛林引起了笔者如此之大的重视?就2点原因:强悍的算法设计和创新能力;全栈开发。每一名工程师,都能够在搜索引擎,推荐引擎,分布式系统,机器学习这些最核心的基础架构领域选择多个甚至全部来进行交付,而且一旦做出成果必然是state of the art,秒败国内成千上万人团队的战斗力。最早的搜索和推荐一体化引擎Sedue,独一无二的采用了后缀数组+压缩后缀数组的解决方案,为此他们解决了快速构建(每秒钟索引5MB文本)和增量构建两大技术挑战,支撑了日本多家互联网公司(例如日本书签,博客和社交网络领先提供商Hatena)的搜索解决方案,至今已经5年过去,没有看到业界和学术界有可以匹敌的工作。后来推出的开源分布式机器学习引擎Jubatus,乃至目前成立了新的公司Preferred Networks专注于深度学习的开发和创新。这是利用利用技术创业,小公司解决大问题的最完美实践之一。
扯远了,回到Self Index和后缀数组。基于后缀数组构建索引,意味着把整个文档连接成为一个巨大的字符串,然后再构造后缀数组,这样可以提供任意子串的查询和TopK运算。然而,构建后缀数组需要巨大的工作空间,因此解决空间消耗问题就是一个大的挑战,这时就引入了压缩后缀数组。然而,压缩后缀数组只能工作于内存之中,对于海量的文档数据无能为力,因此,把压缩后缀数组和后缀数组结合起来,就构成了商用搜索引擎的解决方案,其中后缀数组部分存放在SSD上。这样的方案,我们可以看到单机索引甚至达到TB级别,依然能够提供良好的查询性能,这是其他任何索引结构都无能为力的。
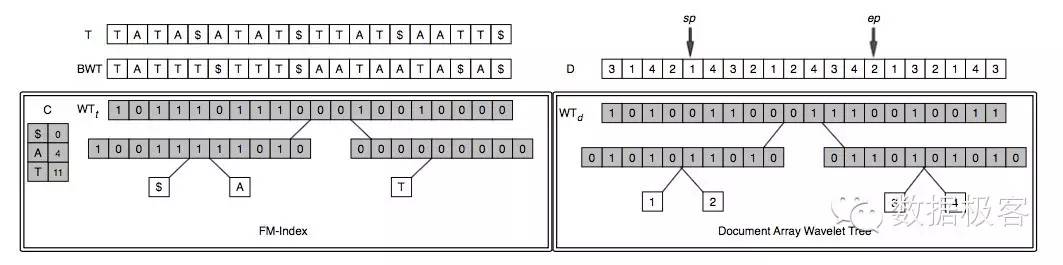
笔者团队曾经尝试过基于压缩后缀数组提供搜索引擎的解决方案,取得了比传统倒排表近一个数量级的性能提升。具体做法是:首先针对文本构建压缩后缀数组的变种FM-Index,这需要先把对文本做BWT变换。BWT变换就是常用的压缩工具BZ2中的“B”:把文本不断旋转后组成矩阵,取最后一列既BWT变换后的结果,例如文本“abracadabra”变换后成为“ard$rcaaaabb”,$为文本结束标记符。如果有很多文档t1,t2,...,tN,那么就把它们连接在一起针对T=t1$t2$...tN进行BWT变换。

BWT变换后的文本更加有利于压缩,因此以该文本构建后缀数组之后,再放入小波树中可以提供类似于后缀数组的查询能力。可以看看BWT变换前后文本的对比:
变换前:

变换后:

此时FM-Index构建完成,索引已经可以提供任意子串的查询,但并不能够提供文档ID的提取,以及求交,求并等TopK检索,这时需要再次引入小波树,把FM-Index对应的文档ID序列放入其中。因此,一次检索过程需要针对两个小波树做操作,如图所示,左边的小波树是FM-Index,用于查询到不同子串的位置,后边的小波树则用于在多个关键词之间获得最后的文档ID。
在整个索引构建过程中,succinct数据结构小波树起到了核心作用。采用succinct数据结构构建搜索引擎的玩法还有许多,主要目的都是获得更高的压缩率和更快速的检索性能,然而,由于它们并没完全解决工作空间的临时内存消耗问题,以及搜索过程中的TopK查询问题,因此大都停留在学术阶段,而真正付诸于商业应用的,也只有屈指可数的几个团队了,或者说,就2个团队。
真正把算法用于系统设计,带来的是更快,更有效。在本公众号系列文章中,我们已经先后看到存储引擎,搜索引擎,等等复杂结构如何受益于算法,我们希望看到,在基础架构设计中,更多的引入算法到项目中,而不仅仅停留在面试,考试中的无意义烧脑题。
本公众号开办一个多月以来,以较高的更新频率先后涉及到了存储引擎,分布式系统,推荐系统,广告系统,以及搜索引擎众多话题,这基本上涵盖了大数据从架构到典型应用的场景。在后续的文章更新中,将会更随机,更偶然的涉及到零散的技术话题,本人也期望在积聚到一定规模之后,把所有知识以更体系的方式进行阐述,让更多的基础架构开发人员从中获益,对如何构建大规模系统进行另类的解读。
