




Calvin是一个满足ACID分布式事务的数据库实现,可以做到系统事务吞吐随着集群的扩展达到了接近线性的增长。我们注意到阿里中间件团队博客也有Calvin的介绍,想必大家对于如何实现分布式ACID事务都非常感兴趣(点击阅读原文可以看阿里团队的文章)。本公众号从Spanner和蟑螂数据库开始,也先后介绍了VoltDB,ConcourseDB,顺带提及了FoundationDB,那么为什么当时没有提及Calvin呢?因为Calvin只是一个学术界的产物,只有原型设计,对于绝大多数数据库使用者或者DBA来说,确实缺乏吸引力。还有一个原因是,Calvin的论文近期才读,写公众号的一个好处是可以强迫读一些眼下无用但未来总有价值的东东。
首先,Calvin跟VoltDB类似,分布式事务都是基于时间戳来设计从而避免2PC的锁。从数据库术语上来说,这叫做确定性数据库,意思是数据库给定相同的事务输入,那么就一定会在事务完成之后停留在确定的状态,这是一个比传统数据库ACID更强的保证——后者则需要数据库最终的状态是按照某一个顺序执行事务,不同的数据库可能会选择不同的顺序。确定性数据库的副本之间不需要频繁交互以确保相互状态的一致,所以每个副本状态总是一致。因此,传统数据库事务使用时,需要由客户端决定事务的时序,比如在begin和commit之间定义好逻辑顺序,而确定性数据库则在数据库内部确定顺序,客户端无需介入。相比之下,传统数据库对客户端提供了更多的灵活性,而确定性数据库会因为在某些情况下缺乏灵活性而让客户端等待更长时间。除此之外,确定性数据库可以避免死锁(因为本来就无锁),节点失败时也不会导致事务退出(因为可以有副本执行事务),并且系统吞吐量可以接近线性增长(因为完全的share-nothing结构可以容易的线性扩充)。因此,对于延迟敏感的应用来说,传统数据库依然是更佳方案,然而对于需要支撑大量的事务吞吐量的系统来说,确定性数据库会更适合。
回到Calvin本来的结构,可以参见下图,Calvin没有任何2PC相关的设计,这是通过把更新操作而不是更新结果做同步来达到,也就是用全局的队列来同步操作日志。客户端会将写入请求,发送至sequencer,它会收集发至本机的事务请求,每隔10ms将事务进行batch并为每一个batch事务进行编号,Calvin采用Paxos同步或异步来复制batch后的事务,异步复制中,副本之间存在主从结构关系,主副本上的事务操作不必等待从副本之上的复制完成之后才开始派发,因此延迟更低,但异步复制在主副本出错时会产生问题,因为需要在所有副本之间确保状态一致后才能选举出新的主副本,这跟MySQL主从结构中主节点DOWN机是同样道理;因此Calvin还提供基于Paxos的同步复制操作,复制完成后,事务递交给scheduler,后者用于确保sequencer决定的事务编号顺序依次执行——但仍然是在线程池中并发执行,因此需要引入确定性锁设计,Calvin严格保证当一个事务和另一个事务,有冲突的时候,事务编号靠前的先获取锁。storage层非常简单,Calvin可以嵌入任何单机存储引擎。此外,Calvin在设计上并不强迫使用事务,对隔离性和一致性要求较低时可以走图上左边的通道以提供更好的访问性能,右边的通道是分布式事务。
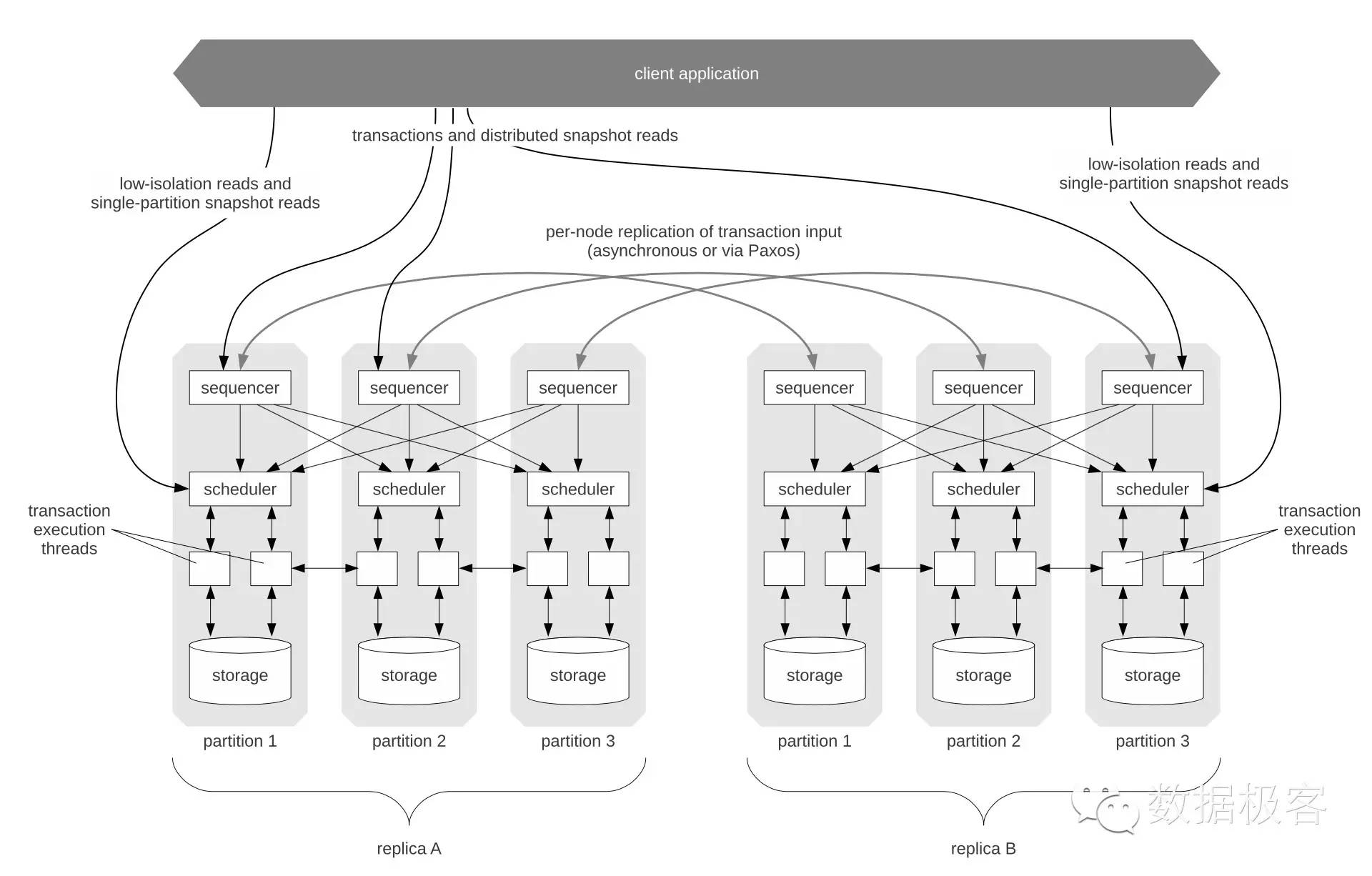
说句题外话,在上面这段文字中,我们再次看到了基于Paxos的同步复制这样的字眼,在分布式系统构建里,我们几乎随处可以看到这样的设计,因此,如果存在这样一个公共组件,倒是很方便我们构建自己的分布式系统,笔者恰好就看到这样一个东东——Replicant,各位可以自行品玩。
另外提一点,Spanner/蟑螂的事务跟时间戳也同样有着密切的关系,但它们跟Calvin是有区别的,前者的设计是为了做到外部一致性:如果一个事务 T2 在事务 T1 提交以后开始执行, 那么,事务 T2 的时间戳一定比事务 T1 的时间戳大。而Calvin无法做到这一点,提供的是顺序一致性保证,因为Calvin会针对事务时间戳重新分配。
Calvin数据库整体实现并不复杂,嵌入恰当的单机存储引擎,封装好合适的客户端,你就可以在此基础之上自己攒一个支持分布式事务的数据库,然而,正如前边所述,你必须清晰的了解确定性数据库看的优劣,才便于在各种场景里做出适合自己的决策。
