




Spanner,蟑螂数据库采用基于时间戳的变种二阶段提交提供分布式ACID,由于蟑螂距离成熟还有距离,那么我们有没有其他可用的支持分布式ACID的数据库了呢?
其实还有一些数据库宣称达到这些要求,比如FoundationDB,比如HyperDex Warp,MarkLogic,MemSQL,SAP HANA等等,要么因为是内存数据库,因此基于锁的2PC对性能影响不会过于严重,要么则由于是商业数据库因此我们无法获知他们如何做到分布式ACID的细节。至于FoundationDB,原来本公众号试图了解其细节,但近期发现相关文献在FoundationDB被Apple收购之后已经全面删除,只能留下一些只言片语,一并记录如下:FoundationDB的事务由3种角色构成:
代理。负责处理客户端事务请求,代理也参与事务提交过程
冲突解决器。负责跟踪Key值的修改历史,确保事务的顺序隔离性
事务日志。事务日志本身也存放在高可用存储引擎中
事务写入步骤:
客户端发送事务请求到代理
代理利用冲突解决器决定事务隔离
代理发送通过事务隔离性检查的事务到日志中
事务日志确保安全写入
事务日志通过代理告知客户端成功操作
事务日志更新存储引擎
接下来谈谈VoltDB,尽管是个内存数据库,但开源的本质使得我们可以进一步了解分布式事务是如何设计的。VoltDB主要根据时间戳来做到分布式事务,从而避免锁以及分布式日志的开销,任何一个分区同一时间只有一个事务在执行,VoltDB会事先分析好存储过程之间的关系,如果两个事务可能存在冲突,则不让这两个进程在同一个时间执行。在实现中,VoltDB会把数据划分成许多分区,每个分区指定好相应的CPU,称之为Site,每个Site都是一个单线程的应用,并拥有一个事务队列,确保单分区内事务的顺序执行。如果一次操作需要涉及到多个分区,就需要引入一个协调者,就是VoltDB集群每个节点的一个Initiator。客户端会向任意一个Initiator发送事务请求,比如图中的客户端发送到了Node 1的Initiator,在事务执行中,Initiator会根据Key值判定真实数据的副本存在的物理节点,例如图中的事务请求,Node 1的Initiator判定真实数据位于分区1,对应的副本分别存放于Node 0和Node 2(Site 1和Site 4), Site1和Site4分别有一个队列存放事务信息,这些队列十分重要,因为它们被用来确保事务的全局时序,只有在两个属性满足时,才会允许事务出队列:第一个属性是每个出队列的每个事务都有全局时序,这意味着它能够确保不会有早于当前时间的事务被系统的任何Initiator接收。第二个属性是每个出队列的事务都被确保送达分区的每个副本。
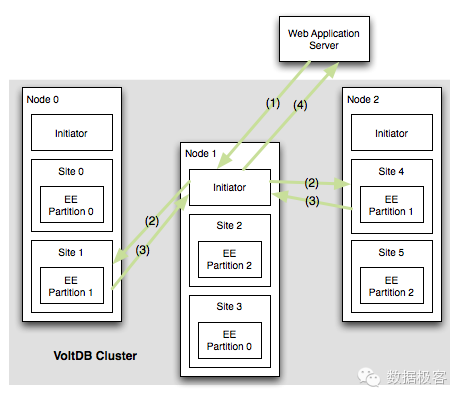
默认情况下每一个事务在执行之前都要等待一个Round Trip时间,以确保别的节点没有发起比这个事务更早的事务,保证事务执行的顺序。这个Round Trip时间是通过节点之间心跳机制来获得:每台服务器每5毫秒会向其他服务器发出心跳(负载高时事务本身可以充当心跳)。通过观察心跳,一台服务器知道其他服务器是否会有新的事务。最差情况下,也就是当集群完全处于闲置状态时,一台服务器要执行一个事务前,最多等待5毫秒以确认是否有更早的事务会从其他服务器过来,这会显得VoltDB的延时似乎总是大于5毫秒,但实际上如果负载够高的话,这个等待时间就明显缩短了。在实现中,VoltDB用了另外一种优化方法。例如A,B两个节点,分别要执行事务1和2,A节点开始执行事务1的时间是T1,如果A收到B发了事务2的执行需求,并且T2 > T1,那么A节点可以确认从B节点不会有更早的事务再发送过来,A节点就不必等Round Trip时间,可以直接执行事务1。当整个系统压力比较大时,这个优化方法效果尤其明显,事务的时延有效降低。
最后谈一下ConcourseDB,这是个鲜有人听说过的分布式数据库,开源并且支持分布式事务。ConcourseDB仍然采用基于锁的做法提供事务——只不过引入特殊设计避免锁的时间过长,称之为Just In Time锁。事务操作过程如下:
每个事务在一个隔离缓冲区内对数据操作,完成操作后需要提交时,事务将自己注册,使得能够获知来自任何其他事务的冲突,到此时并没有锁产生;
如果事务提交时被通知有一个冲突,那么该事务失败,并通知客户端;
如果事务没有被通知有任何冲突,那么允许该事务提交,此时它会试图锁住需要的资源,在这个过程中,事务仍有可能被通知冲突产生,或者没有成功获得锁,这时事务将失败,并通知客户端;
如果事务成功获得资源锁,那么事务将生成备份数据并立即提交,提交成功后备份删除,释放锁资源。
缓冲区是减少锁粒度的最主要设计,缓冲区不仅仅用来处理写入操作,在读操作时也同样提供查询服务——缓冲区有安装Bloom Filter以判定读操作的Key值是否能够命中。由于没有详细的Benchmark数据,我们无从得知这种设计的性能如何,但这的确是我们能够获得的少数支持分布式ACID的非内存型开源数据库,迫切需要分布式事务的团队们,你们敢来踩坑么?
顺便提一下阿里的OceanBase,这也是个支持ACID的分布式数据库,只不过大部分假设是每天的写入操作用单节点可以支撑,因此分布式ACID并没有提供。由于该假设对硬件要求过于苛刻(负责更新的服务器需要具有大内存),因此显然不具备在通常硬件条件下部署的可行性。听说最新版本已经实现了2PC,由于相关版本没有对外公开因此细节不得而知。
