




一周前,监控系统不间断的报警,提升有大规模访问超时的情况,自从上次架构升级后,我们将部分公共业务剥离至网关,所有的流量都过网关,所以在网关层面做了一层无死角的监控,对任何业务的业务、系统异常都能全部覆盖到。结合可伸缩的监控报警策略,可以实时的报警,从而快速介入。以下是报警:
查看一下报警的详情,都是一类访问接口导致的,点开看下报警详情:网关转发时报502错误,这个错误是nginx爆出来的,因为后面的服务是rest访问,除了40x和200,不会报50x,而且nginx报50x,猜测应该是nginx upstream时超时了。

最近运营活动很多,带来的量很大,表现就是平台的日活突然提升,而且在产品的上线发售时间前后有一个很明显的尖峰,从系统的负载上来看:

11点后有个明显的负载瞬间提升,然后慢慢降下来,从nginx访问来看:
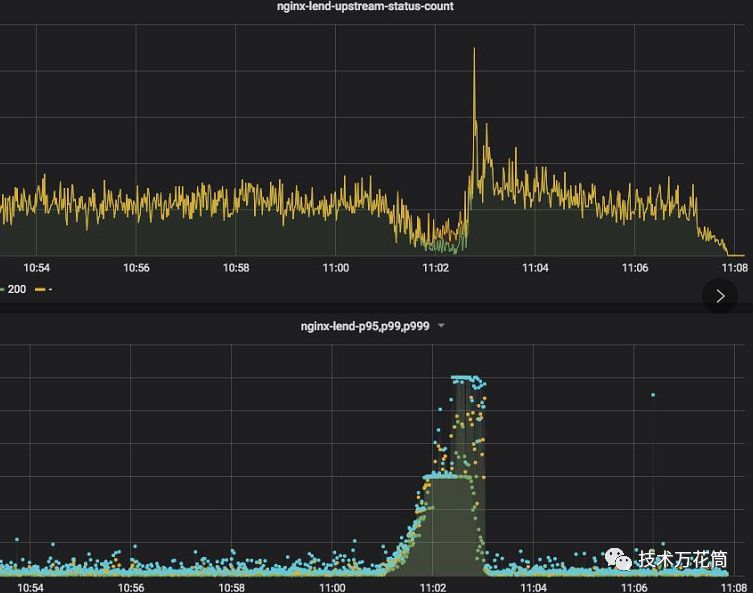
访问飙升为平时的十几倍,而5xx的状态码也是瞬间增加了十几倍(这也是报警中状态码502的来源),nginx的这个图下面的部分就是超时请求的一个表现,和负载有个很明显的关联,结合网络流量等,都可以印证(图省略掉了),就是qps的飙升导致某个服务的吞吐量跟不上。
看了下请求日志:找到超时的这个请求,通过logid trace一下,发现了这个请求的一些现象:
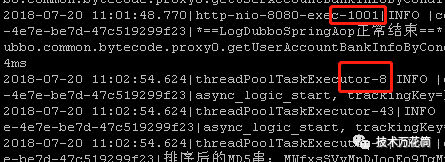
在11:01:48.770这个时刻,线程http-nio-8080-exec-1001执行,这个是tomcat处理http的socket请求的线程,也是一个线程池,这个采用的是默认的200个(坦白讲有点小,请求尖峰的时候明显不够,造成一些请求积压),下一步执行居然切换到了另外一个叫threadPoolTaskExecutor-8的异步线程执行,这个线程隔了1分钟才启动并执行,觉得挺奇怪的,看了下代码,原来这个info接口是查看用户我的财富页,显示用户所有金融产品的持仓信息,,需要去不同的底层系统获取数据,为了提高性能采用一个线程池并行去取,用一个Latch去收集数据返回:
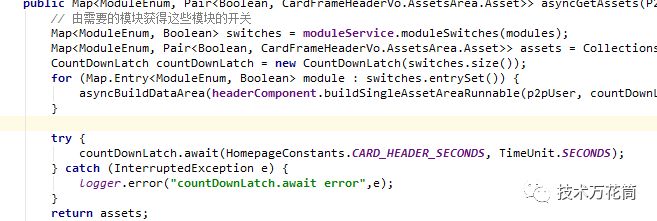
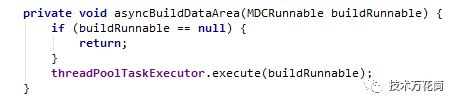
代码貌似没什么问题,但是从threadPool提交线程,到线程调度执行居然等了1分钟之多,因为线程迟迟不执行,因为nginx那边迟迟获取不到response,超过了nginx的超时时间然后就直接超时报错了。问题应该是发生在这。那线程为什么迟迟不执行呢?看了下线程池的配置:
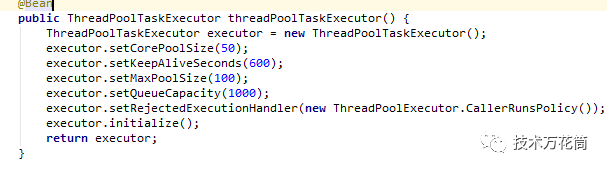
发现了问题,这个线程池的Queue的size为1000,corePoolSize为50,结合当时的qps的峰值来看是远远不够的。问题就出在这个queue上,这里线程池处理的逻辑是这样的:
1、线程池启动时会维持一个CorePoolSize数量的线程池;
2、当活动任务超过CorePoolSize时,任务会进入Queue;
3、当Queue满了后,然后发起新的线程,线程的数量不超过MaxPoolSize;
因此,Queue设置了1000,绝大多数任务都在队列里得不到调度,吞吐量上不去。于是,结合峰值的qps的值,估算了下容量,将配置改了一下:
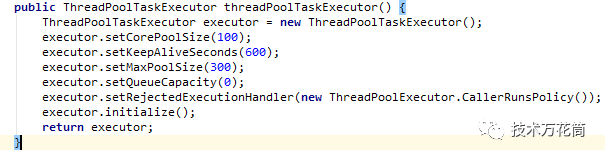
就是线程来了后不进入队列,如果不够直接产生新的线程,并将线程的超时实际调大一倍。期望线程立即被调度执行。
上线后,两天之内再也没出现过超时的报警,问题貌似解决了。
-----------------------------------------------------------------------------------------------------
事情还没完,结果下周一又出现了,而且基本上每小时都会发生一次,具有一定的周期性,真是匪夷所思。又分析了下日志,结果头都大了,出现了很多新问题,总结来看:
1、异步线程的调度执行还是延时严重,最高超过了10分钟;
2、请求底层的一些接口时快时慢,毫无规律可言。。。
这个日志看起来是毫无章法,往前分析了一下正常时间段的日志,问题2也有提现,也有时不时超时的问题,只是在这个时间段内稍微有点突出而已,应该不是问题主因(在这里也发现了一个问题,请求底层的接口超时时间太长,居然超过了60s,这带来很大的问题,作为业务接入层,要求是短事务,请求要短平快,所以超时时间不能太长,太长的话请求会hang在那里,严重影响吞吐量,在我之前的经历中,一般的话超时时间不超过1s,有的极端情况,一些超高qps请求的接口甚至超过100ms就超时放弃了,否则会严重影响吞吐量,具体要结合请求的量、业务的复杂度来综合考虑,这里后面给改为了3s)
既然通过日志已经看不出什么,而且异步线程被阻塞,肯定有另外的原因,所以需要看一下线程的dump,就抓到了当时的现场(间隔多抓几个):
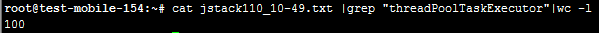
异步线程池目前是100个,说明线程数是够的,而且还稍微有点大。而且绝大部分都在空闲状态。但是看了下tomcat的工作线程,吃惊不小:
线程数也是200个,不知道够不够,但是看了下状态,全部被阻塞住了:
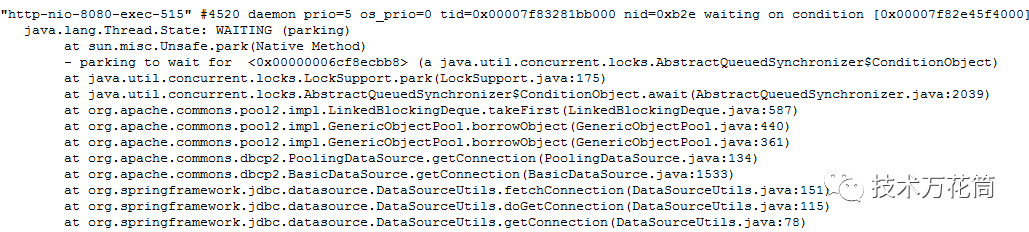
统计了一下,200个工作线程,有192个在wait,8个在running
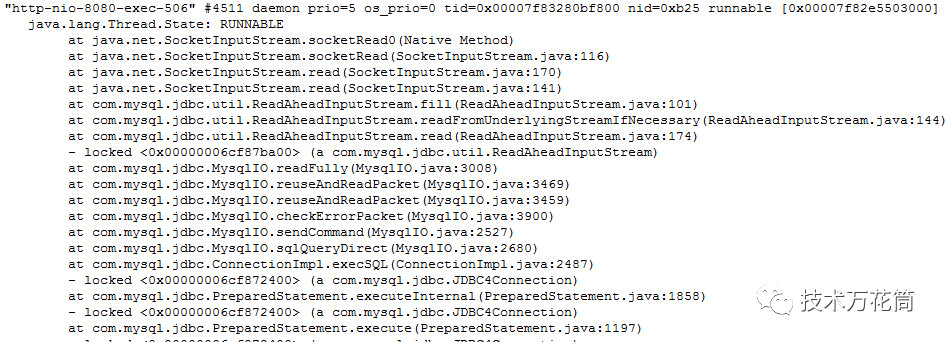
这下问题很明确了,立刻检查连接池配置:
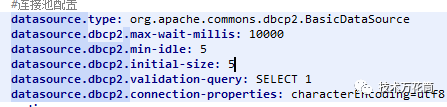
默认居然是5个,最多不超过8个...这个服务的查询都是短查询,信息极少,其实5个链接也能应付不小的并发了,为什么最大到达8个链接的时候全阻塞住了呢?带着这个问题又继续排查,结合一些其他的信息,发现原来周一上线了一个活动,要定时的跑一个批处理任务计算排名,有一个慢sql1小时跑一次,把整个库拖慢了。。。因此这个服务的查询被慢sql拖住了,而连接全被占满,所以所有的线程都阻塞在读取数据和获取连接上,导致nginx的upstream请求超时。
所以措施:
1、解决慢sql,拿到从库上跑;
2、调整db的连接池,并适当缓存。
另外,我们常见的一些动态缓存策略其实在某些场景下有隐患,如以下的动态缓存策略:
List data=CACHE.getData();
if(data is empty){//缓存不存在或者失效
List data=DB.loadData;//去数据库读取数据
CACHE.putData(data);
}
如果在DB.loadData这个地方如果阻塞住了,那么这里如果没有线程同步策略,那么所有的线程都会涌向去执行DB.loadData,会给数据库带来雪崩。而且即便做了线程同步,也会存在问题。同步了之后,最先去load数据的线程如果hang住了,那么其他线程都会等待这个线程load完,也会被阻塞住。这里先行让缓存失效或者由当前线程去加载数据更新缓存其实在某些场景下有风险,一般的做法都是:
1、缓存过期,数据被清理掉;
2、线程判断数据清理掉,加载数据更新缓存,然后继续;
可以改一下:
先从外部加载数据,加载成功后,再更新缓存。
这样即便在加载的时候阻塞住了,但是这时候缓存还有数据,其他线程可以先用着,不至于没阻塞。而异步线程在更新缓存时只是个瞬间的动作,保证线程安全即可,不会给其他线程带来阻塞的问题。
当然这样的处理方式得结合具体的场景,如果对缓存变脏0容忍就不合适,否则的话就适用,如我们有些配置信息缓存10分钟过期,如果没有及时过期,哪怕到第15分钟我仍然可以使用,毕竟配置不经常修改,也无所谓。所以在设计的时候要综合考虑一下风险。
另外多看了一下这个服务的一些指标,发现了一个有趣的现象,它的网络情况如下,居然是请求大于响应的。
觉得有收获吗?欢迎点赞转发,点右下角好看!
