




前言备注:
已经将该问题提给了spring cloud,ISSUE地址:
https://github.com/spring-cloud/spring-cloud-netflix/issues/2831,基本可以定性,某follow给出了一些解决方案。通过改造ZuulController,资源注册和回调的方式清理资源等。继续关注
移动后台自从2013年就没有升级过,是一个非常庞大的单体应用,虽然也有网站分担一部分流量,但毕竟现在是移动互联网时代,所以移动后台承载着超过90%的流量。从2015年以来,随着业务发展,产品、运营、推广都在持续发力,因此用户量到访问量,集中反映在系统的qps上一直在飙升。从业务上来讲,所有的业务都对接到了移动后台,成为了一个瓶颈。亚马逊所倡导的“2 pizza团队”其实很科学,但移动后台是一个庞大的单体,虽然人可以“2 pizza”的规模,但是仍然在一个工程上开发上线,因此冲突非常严重。而且系统的流量不断上涨,时刻影响着这个单体的稳定,进一步影响了整体的迭代速度。其实从初次接手时就觉得很被动,但是毕竟不熟悉,后来经过1年多的摸索也差不多摸清了,因此从2017年初就有心想将其拆掉,将整体的架构以及技术栈都升级一下,适应现阶段的业务发展和团队规模。
这是一个非常庞大、复杂的工作,伤筋动骨,而且还要优化系统调用的流程,减少冗余链路,归还技术债。所谓多做多错,少做少错,不做不错。做,可能免不了犯错误踩坑,但Do you know the harder thing to do and the right thing to do are usually the same thing?
在这中间遇到的第一件很棘手的事情就是将zuul作为网关上线后遇到的数次挂掉的问题。其实在过去的经历中,处理了很多类似的问题,谈不上经验丰富,这次比较特殊是因为实在太复杂,而且面对的是一个趋向于黑盒化的spring-cloud系列的框架。而且我们这个架构处于一个中间状态,链路太多。其实是不愿意用这些框架的,封装的实在是面目全非,出现问题排查的代价太高。而且最最主要的是,基础设施并不完善,很多监控的工具并没有工程化,得到服务器上自己去采集去看,而且没有权限,运维同学甚至连sudo都不愿意给你。
先说一下这个中间态的架构形态吧,或者叫过渡形态。
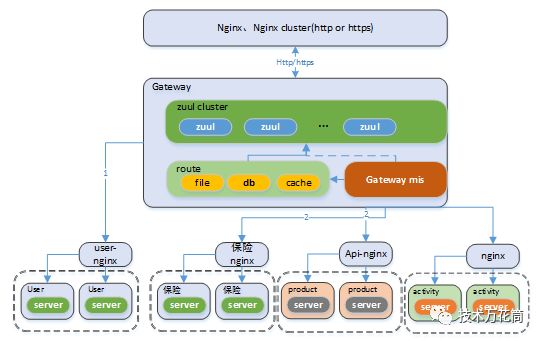
整个服务的拆分,算盘是这么打的(当然不只是拆了,只是拆的意义不大,问题并没有减少):
1、 在改造的第一阶段,我们先将某个业务从移动后台剥离出来,但是为了减少复杂性,暂时将剥离的服务挂在nginx下面,如图中的保险nginx,并没有用eureka来做服务注册和发现。然后在网关上通过url而非serviceId的方式进行路由。
2、 同样的,依次拆分其他的业务,然后依次挂在nginx下面,通过网关来路由,直至将所有的服务拆散了依次挂在网关下面,通过nginx来转发。
3、 等到所有的服务拆掉,然后把nginx干掉,分别将服务再改造注册到eureka上。然后使用其整个框架中的lb和hystrix。
为了这个算盘,我们特意将zuul的路由加载机制进行了改造,从数据库中加载路由而且是热加载,支持动态配置,还特意做了一个MIS系统来管理,因为我觉得一个优秀的网关必然得支持API配置,像nginx那种配置根本不是给人使用的:)
一切进行的非常顺利,在初始,在我们的原始架构上前面架上zuul,将流量全部由zuul接管,我们也做了测试和压测,觉得满足要求就上线了,由于措施得当,上线运行良好,跑了1个月左右。然后接下来一个个的将业务拆出来,保险业务就是第一个要拆的。
拆完保险业务后,我们紧接着就上线了,此次上线做了以下几个动作:
1、 上线eureka,同时将网关的功能继续丰富,一些业务功能前置;
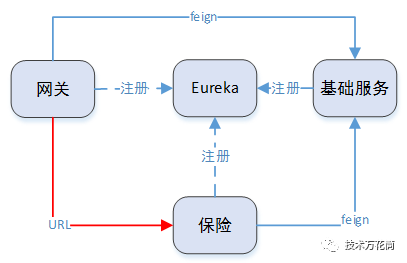
2、 此次拆分出来两个服务,一个是基础服务,一个是保险服务,但是保险服务会调用基础服务的一些用户信息、账户数据等。因为最终我们的目标是用eureka做服务注册和发现,也是为了蹚一蹚eureka的水,所以将基础服务和保险服务注册到eureka上,二者通过eureka来做服务发现和调用(feign client的方式)。而网关会尝试下发给下游系统一些基础的用户数据,所以网关和基础服务之间也是通过eureka的方式来做服务发现(feign client)
3、 但是网关路由到保险服务,仍然用url的方式而非serviceId,至于为什么,是担心初次使用怕遇到什么问题,使用了比较稳妥的url路由,也就是说网关和保险服务之间没有eureka的牵线。到这里你可能会问,为什么网关和保险服务没通过eureka,而网关和基础服务,基础服务和保险服务要通过eureka?是因为网关和保险服务分别调用基础服务的调用并非关键路径,如果调用失败的话可以服务降级。所以即使eureka挂了也无所谓。
好了,背景交代清楚了。几个服务分别上线,早上上线,当天晚上就开始报警,报警信息显示,网关有三台机器失去响应了,网关本质上是一个http服务,监控系统会不断的发送心跳探测8080端口,探测不到response满足一定的阈值就报警。
看了下日志,发现只有网关和eureka间的心跳检测,而没有请求日志打出来,心想坏了,有心跳检测却没有请求响应,服务没挂,应该是hang住了,这可能就比较复杂了。立刻做了一个线程的堆栈,当然是祭出jstack啦,关于jstack的用法,请参考该文档https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstack.html#BABGJDIF
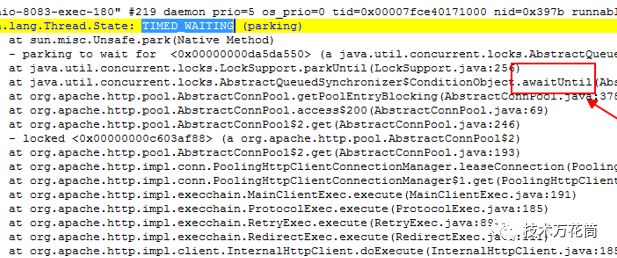
"http-nio-8080-exec-200" #263 daemon prio=5 os_prio=0 tid=0x00007f109630e800 nid=0x4e30 waiting on condition [0x00007f102003f000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000006ce533488> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at org.apache.http.pool.AbstractConnPool.getPoolEntryBlocking(AbstractConnPool.java:380) at org.apache.http.pool.AbstractConnPool.access$200(AbstractConnPool.java:69) at org.apache.http.pool.AbstractConnPool$2.get(AbstractConnPool.java:246) - locked <0x000000075d6584e0> (a org.apache.http.pool.AbstractConnPool$2) at org.apache.http.pool.AbstractConnPool$2.get(AbstractConnPool.java:193) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:282) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:269) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:191) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:185) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:111) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:118) at org.springframework.cloud.netflix.zuul.filters.route.SimpleHostRoutingFilter.forwardRequest(SimpleHostRoutingFilter.java:332) at org.springframework.cloud.netflix.zuul.filters.route.SimpleHostRoutingFilter.forward(SimpleHostRoutingFilter.java:251) at org.springframework.cloud.netflix.zuul.filters.route.SimpleHostRoutingFilter.run(SimpleHostRoutingFilter.java:202) at com.netflix.zuul.ZuulFilter.runFilter(ZuulFilter.java:112) at com.netflix.zuul.FilterProcessor.processZuulFilter(FilterProcessor.java:193) at com.netflix.zuul.FilterProcessor.runFilters(FilterProcessor.java:157) at com.netflix.zuul.FilterProcessor.route(FilterProcessor.java:118) at com.netflix.zuul.ZuulRunner.route(ZuulRunner.java:96) at com.netflix.zuul.http.ZuulServlet.route(ZuulServlet.java:116) at com.netflix.zuul.http.ZuulServlet.service(ZuulServlet.java:81) at org.springframework.web.servlet.mvc.ServletWrappingController.handleRequestInternal(ServletWrappingController.java:165) at org.springframework.cloud.netflix.zuul.web.ZuulController.handleRequest(ZuulController.java:44) at org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.java:52) at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:991) at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:925) at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:978) at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:881) Locked ownable synchronizers: - <0x000000075df83448> (a java.util.concurrent.ThreadPoolExecutor$Worker) |
除了jvm的一些守护线程外,总共有217个线程处于以上的状态,WAITING状态,而且根据堆栈来看,都是http请求且路由的线程被阻塞了(wait),看了下堆栈,有这么一行:
at java.util.concurrent.locks.AbstractQueuedSynchronizer
$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
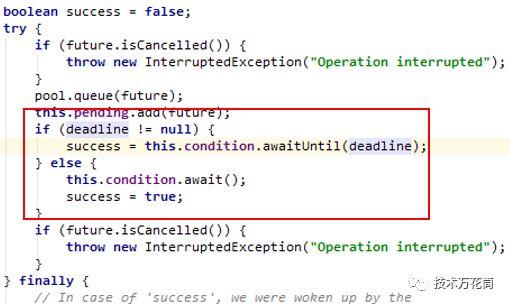
在AbstractConnPool类中的getPoolEntryBlocking方法为从当前的连接池中获取一个http链接,在第377行判断deadline是否为空,这个deadline是一个Date类型:

timeOut代表超时时间,如果超过了超时时间就不再wait抛出异常,如果没有超时时间就一直等待,直到有可用连接为止。而追查了一下,这个timeOut其实是RequestConfig类中的connectionRequestTimeout,单位是毫秒,而默认zuul就是0。
由于做了线程dump后就急于恢复服务立刻重启了,所以没有保存更多的现场数据。分析到这里,可以得到如下结论:
1、未设置HttpClient的connectionRequestTimeout值,导致从连接池中获取连接时未有可用连接,导致线程阻塞;
2、未有可用连接应该是连接泄露导致。
同时存在以下疑问:
1、 网关早就上线了很久,路由以及路由加载这块都没改过,原来也没设置connectionRequestTimeout都没挂,为啥此次上线这么块就挂了?
2、连接为什么泄露?由于此次上线改动比较大,网关增加新的功能模块,上线基础服务、保险服务和eureka,动作比较多,不好确定是什么原因。决定实际压测一下。
于是还原了线上的环境,在预发布环境搭建了一抹一样的环境开始压测。压测使用的是高性能且轻量的http压测工具wrk,它是个开源的东东,参考:https://github.com/wg/wrk
使用很简单,而且扩展性非常强,典型的参数如下:
可以通过lua扩展,可以自定义回调等,我们此次压测是这样的,body的数据在lua中:
wrk.method = "POST"wrk.body= "clientType=1&channelId=E66C5A44DE9841CC70C3DBD51560EC2B&wrk.headers["Content-Type"] = "application/x-www-form-urlencoded"wrk.headers["clientType"] = "1"wrk.headers["clientVersion"] = "490" |
调用如下:wrk -c50-t40-d10s-s post.lua http://xxxxx/cfg.action
网关中httpClient的连接配置如下(这个配置当时没注意,其实是有问题的,但是不是主因,后面再说):
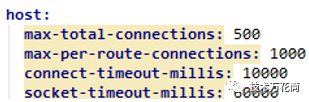
后来增加到500个tcp,100个线程,压了几个小时也没发现问题,一会就压了几百GB的日志出来。如果连接有泄露的话应该是可以压出来的,由于没有复现,当时也没有查看netstat,所以不确定线上当时是什么状态,但是压测机的netstat是正常的。
由于代码审查看出是没有设置connectionRequestTimeout的,于是设置了一下,自定义了CloseableHttpClient:
@Value("${zuul.host.connect-request-timeout-millis}")
|
期望在连接不够时不要一直阻塞,而是报错,心想报错也比阻塞强啊,于是灰度上了下线,上线没多久,网关又挂了,不同的是日志里面报了大量异常后挂掉的:
 后来仔细排查了一下,发现了网关的httpClient连接的配置存在问题,即:
后来仔细排查了一下,发现了网关的httpClient连接的配置存在问题,即:
max-total-connections的值不应当小于max-per-route-conns,max-total是所有通道占用的所有连接,而下面那个是每个通道占用的连接。比如分别往IP1和IP2路由,IP1和IP2分别是一个通道,这俩通道占用的所有连接总数为max-total-connections,而max-per-route-conns一个就是1000,远远大于max-total-connections,这肯定不行,于是将max-total-connections改为2000(其实没必要这么大)重新又灰度了一下,监测了一天后发现总体服务正常,但是新上线的保险服务却打不开了,前端的页面和接口请求都报错了。
此时没有着急重启,立刻dump了一下线程堆栈,发现堆栈没有问题,线程状态都正常,而日志里大量的报出来这个异常:
线程堆栈里存在以下状态说明设置的超时时间已经生效(这个状态不太容易
被抓住,因为超时时间只有100ms)
因为设置了connectionRequestTimeout所以线程条件等待后不再阻塞,
报出异常后中止了。立刻查看了一下连接状况,这一看不要紧,发现了大
量的CLOSE_WAIT: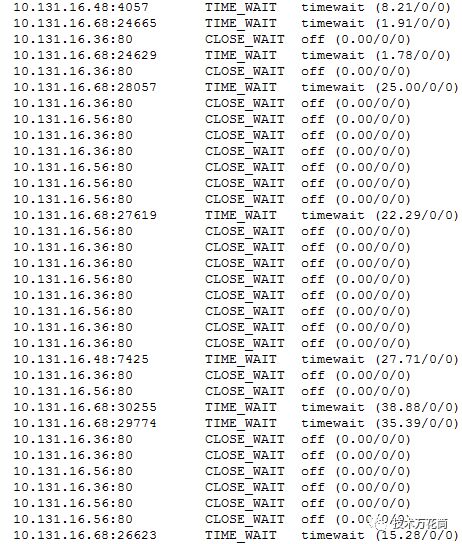
统计了一下,恰好1000个,而巧合的是max-per-route-conns我们设置的就是1000,这也太巧合了吧?而且更为奇怪的是,只有16.36和16.56两个IP的TCP为CLOSE_WAIT,其他的均没有,而这两个IP恰恰是保险服务前面的nginx。也就是说,网关路由到保险服务的链接被被动关闭了,而到其他nginx的都正常,nginx维持长连接设置的是300s,300s后会自动断开链接,而网关这边如果连接一直是socketRead的话就会进入CLOSE_WAIT状态。看了下保险的服务,一直是正常的,这个就太匪夷所思了吧??
我们把整个过程又重新梳理了一遍,仔细回顾了这几天来做的工作,做了如下动作:
1、彻底排查最近修改的代码部分,是否有使用了链接未释放的。没发现值得注意的。
2、排查从网关到基础服务到保险的各层链路,检查nginx配置和转发日志,在排查nginx转发日志时,发现调用保险服务的某些接口报了4xx以及5xx错误。但是这个细节没在意。因为接口调用失败是常有的事。(其实rest服务应当只返回两种状态,要么2xx要么4xx,只要接口地址无误,就只能返回2xx,内容为json,要么就是4xx,其他的如5xx等都必须包装成接口契约所约定的错误数据和错误码的形式封装在json里返回)
可以得出一个结论:
1、网关到保险服务的路由过程中,http连接没有及时释放,导致连接耗尽,从而导致到保险nginx通道的连接被耗尽再也无法路由,所有尝试获取到保险域名的http连接的线程都以报异常而告终,因此保险服务对前端来说不可用了。之前整个网关hang住的原因是max-per-route-conns远远大于max-total-conns,保险一个通道的连接就把所有通道的配额占满,所以到其他通道的路由无可用连接而阻塞。现在由于max-per-route-conns只有max-total-conns的一半,因此其他通道仍然有1000个链接可以用,只是到保险的转发失败,此处做了隔离,不得不说在这点上,http client这个设计很棒,即便你链接泄露,也只是影响一个通道而已,化整为零的思想。
2、不确定也不知道为何只有保险的服务的http链接遭到泄露,我们一度怀疑eureka,甚至基础服务,但是这种怀疑没有任何事实上的依据。
于是我们将PoolingHttpClientConnectionManager日志的DEBUG打开,准备从日志层面来分析连接leased和released的状况:
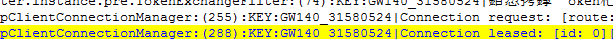
连接被released: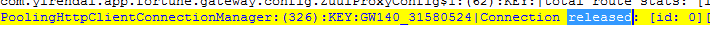
同时打印出线程池中的连接状况: [leased: 0; pending: 0; available: 0; max: 500].同时打印出线程池中的连接状况:
[leased: 0;pending: 0; available: 0; max: 500].
这里补充一句,其实任何时候,日志才是追查问题的终极方法,这就好比现在公安部搞的天网工程一样,四处遍布各种摄像头,记录事发现场的各种蛛丝马迹,供事后分析,现在很多大案、要案都是通过这种视频监控日志来破案的。在很多事情无法找到头绪时,在日志的各种层面进行埋点记录,然后重复事件,通过日志分析各种动作,还原当时的情况,从而重放整个过程,最终一般都可以解决问题。
在打开日志时,意外的发现一个重要的现象:
1、当网关路由到某个请求成功时,PoolingHttpClientConnectionManager会正常的leased一个连接然后再released掉;
2、当路由到某个请求不成功时,PoolingHttpClientConnectionManager只有leased连接,而后面就没有再released掉了。
这个发现太重要了,后来仔细的又重放了整个过程,发现的确如此,每当路由不成功时,lease的连接就不再被release了,这个连接一直处于active的状态不能被重用。而当nginx将该连接关闭时,虽然协议层返回一个FIN包,但是由于高层协议未能返回释放资源的反馈,因此被迫进入CLOSE_WAIT状态,这个连接也无法被清理的Timer expire掉,就成了一个死链接了,这个我后面会详细分析为什么会如此。
恰好这个时候保险服务上线了一次,上线过程中未截流,导致网关转发时打到无效的节点,请求都404了,结果瞬间网关又报出大量异常:
这个意外发现和意外上线更加印证了这个结论:
如果路由转发失败,则当前的这个http连接不会被释放掉。
分析了一下zuul的源码,发现的确如此,如果正常路由,那么最终SendResponseFilter的writeResponse方法中
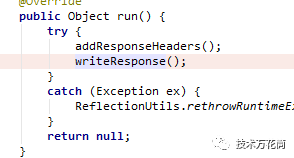
最终交由EofSendWatcher中的ResponseEntityProxy持有的ConnectionHolder关闭该连接:

而我们自定义了一个PostErrorHandlerFilter,这个类对所有的路由结果进行检查,如果非2xx状态,则抛出异常:
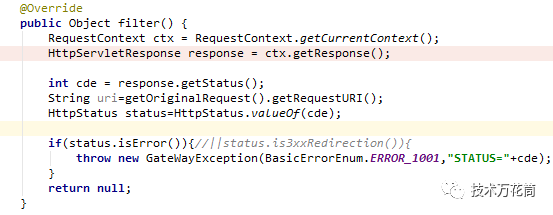
该异常最终到达UnifyErrorAttributes(继承自DefaultErrorAttributes),重写response值,包装成json返回给客户端,保证有返回且是json:

不过我们这里处理有些麻烦,后来改造了一下,最终都是交由SendResponseFilter来处理,从而关闭连接。
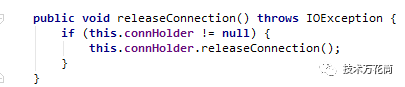
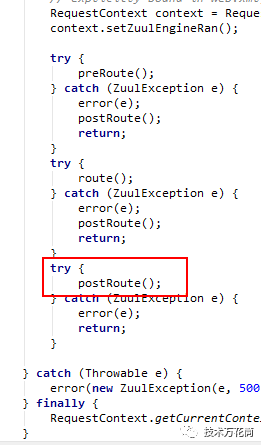
post filter有异常抛出都会直接进入error异常的处理,而SendErrorFilter并不会release连接,这应该是个bug。
此次问题导致的原因总结为:
1、在路由的过程中报异常,此次路由的连接不会被释放;
2、保险服务的某个接口处理不当,导致频繁的报502错误,被路由的filter截获从而进一步抛出异常,每路由报错一次,就意味着一个连接死掉了。所以为什么我们压测也没压出来,而也只有保险服务会挂掉了。
下面是展开的内容,会详细分析一下CLOSE WAIT.
说连接之前,先说一下什么是socket。
Socket的完整权威定义其实在itef的RFC文档中,不过不太好找,若干年前看过,不过有一本很经典的书里说的也很详细,那就是计算机网络第五版,谢希仁著。这本书通常是计算机本科生的教材,说的非常详细也很权威,在这本书的5.3.2节中对socket有明确的定义
谢希仁将socket定义为一个四元组,很多人称之为5元组,我觉得五元组很有
道理,因为TCP的socket和UDP的socket是不一样的,同样的80端口,
其实可以同时被TCP和UDP占用。

一个TCP通信过程连接的建立大概是这样的:
1、客户端通过IP和端口号连接服务器,服务器监听到之后,就以4元组生成一个socket,如果在java里面的话,通常是这么做的:
While(){
Soccket sk=serverSocket.accept();
//发起一个线程处理该socket
}
可见如果系统资源足够的话,其实while是没有终止条件的。
2、socket一旦生成,其实和80端口就没什么关系了,80端口只是个入口而已,一旦进来,数据流由socket处理,或者是由socket的线程来处理。
这其实也可以回答一个问题:一台普通的x86机器,能支持的tcp连接的上限是多少?恐怕30%的人都会回答65536。
理论上socket有上限,其实实际上应该是没有上限,可以计算一下,源IP:端口-目的IP:端口,各自的取值范围相乘一下试试这个值有多大?所以,再巨大的并发量,只要你有足够的内存,CPU其实还是次要,几乎可以支持海量的TCP连接,但是实际上受限于操作系统内核的限制以及机器配置,总有上限存在,像一些中高端的F5硬负载,支持千万的并行TCP连接都无压力。
知道了什么是socket,那么什么是连接?
恐怕没有哪个搞IT的不知道TCP是三次握手,基于连接的可靠传输协议。但是连接究竟是个什么东西?我们所说的连接,是一条虚拟的连接,又叫虚电路。打个比方,A和B要送一堆物品,A怕B不在家收不到,于是A就派一个人C先去B家里敲敲门,告诉B接下来他是否在家,B说我在家,你来送吧,然后B把门打开在家里坐着等着,C回去告诉A说可以了,B在家里等着呢,于是A发货,C再送给B。回顾这个过程,A派C去B家里询问并反馈给A的过程其实就是TCP的三次握手,当B准备好接收物品时,这时候就是我们常说的连接已经建立了,所谓的连接建立,我觉得可以认为是A/B通信双方要为接下来进行的信息交换所约定好的一个契约,这个契约会让双方时刻耗费一些资源去处理接下来的交互。在这个例子中,A到B家的路一直是畅通的,物理上一直是联系起来的。所以这个所谓的连接只是一个二者的一个契约而已,当二者不再共同维持这个约定,B把自己服务于A的资源一释放,这个连接就关闭了。至于为什么需要三次握手,那个经典的拜占庭将军问题就是答案。
那么TCP和IP是什么关系?
TCP属于传输层协议,Ip属于网络层协议,网络层的作用就是投递、寻址,这一层就存在一个非常重要的概念IP地址。IP协议其实就像快递一样,他只负责根据地址投递给对方,但是考虑到互联网的环境是个丛林,非常险恶,快递不一定能送到,那怎么办?TCP就是通过一系列的手段能保证自己的数据能准备送达,它有非常复杂的手段,如序列号、超时重传、拥塞控制、滑动窗口等等一系列的措施。举个简单的例子,TCP要求IP投递给某人一个数据包,TCP会在包里记录下序列号,然后封装好告诉IP,对方收到了的话让对方给我个反馈,IP送达后把对方的反馈带回来,TCP收到后继续发送,如果IP没带来反馈,那么TCP就会让IP再投递一个…直到收到对方的反馈或者放弃,TCP就是通过这样的额外的控制来保障无差错的通信。当然TCP的报文是封装在IP报文里面的。我们知道TFTP是基于UDP的,UDP不面向连接,所以不可靠,那通过TFTP为什么可以实现文件的无差错传输?就是因为TFTP在UDP之上自己实现了发送-确认,超时重传等机制,自己将TCP的可靠交付手段在应用层实现了,可以变相的认为TFTP将UDP当做了IP来使用。所以考虑一下为什么lvs只能是4层转发?
写了socket以及连接后,就可以说下关于CLOSE WAIT了。三次握手不说了,看看TCP连接关闭是怎么回事
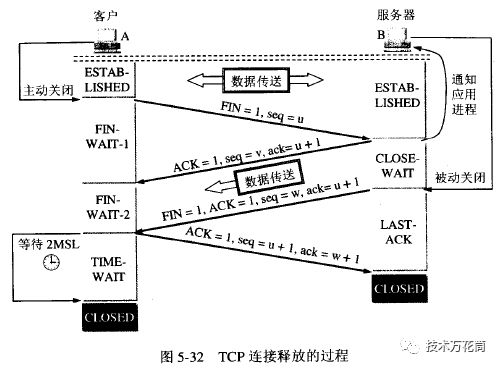
通信双方连接处于established时(简单起见,省去了2MSL的过程):
1、客户端A主动发起关闭成为主动关闭,它会发一个FIN包给B,然后自己进入FIN-WAIT-1阶段等待B回复;
2、B收到后,首先是协议层先回复A一个ACK,然后通知应用程序,连接要关闭了,抓紧释放资源,没传完的抓紧传了。然后B进入CLOSE WAIT状态,就是被动关闭,等待真正关闭(此时A->B的连接已经释放,但是B如果要发给A数据,A还得接收,这就是传说中的half-close状态),等待谁真正关闭呢?
3、就是高层应用,高层应用(如http client)告诉协议层我的屁股擦完了,可以关闭了,这个时候协议层也就是TCP会再发一个ACK和FIN等回复给A,A进入FIN-WAIT-2状态,再回复给B一个ACK后,自身进入TIME WAIT(这个状态很常见,出现这个了,说明这个连接已经快释放了),B收到后直接CLOSE掉,资源释放掉。
4、如果高层应用一直不反馈屁股是否擦完,那协议层无法反馈给A是否关闭,那么B就一直处于CLOSE WAIT状态,该连接无法释放也无法复用,此时连接就出现了泄露。
所以,在此次连接泄露中,http client的连接池中的连接一直处于可用状态(注意不是正在使用状态,此时并无数据真正的在传输),被连接池标记为active不能被复用,但是由于该连接并非一直被nginx所保持,所以超过了keepalive-timeoout后被断开就出现了CLOSE WAIT的问题。Nginx的协议层主动关闭,网关协议层确认后进入CLOSE WAIT并通知http client关闭连接(socket.close()),但是此时并没有线程在使用该连接,而且该连接并未release,一直是active的,所以网关协议层迟迟得不到反馈,连接就一直处于CLOSE WAIT状态了。因此无法释放,也得不到复用,最终连接到达上限,最终hang住了。
另外补充一个socket在active(或者是读阻塞时候)的时候的线程状态:
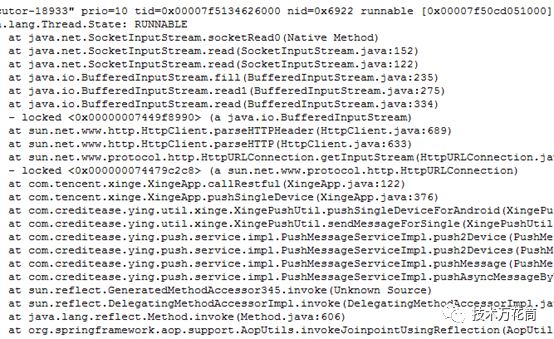
如果堆栈中出现了大量的或者全部的线程都处于该状态,大概说明没有设置socket的socket timeout,读的时候超时所有线程hang住了。我们遇到过很多案例,都是在发起socket连接时未设置timeout或者设置太长,导致所有的线程RUNNABLE,从而阻塞掉了然后整个应用hang住。注意socket读阻塞时并非是wait,而且runnable,写一个socket就知道了,socket通信的双方在读取对方的流的时候,并不知道对方是否有流过来,只能一直监听,因此只能是runnable状态,在java中的socketRead是个native方法,具体怎么实现没有了解过。
