




一、问题现象
客户环境Linux Oracle 11.2.0.4 两节点RAC主库,2节点备库;需要对这个客户的数据库使用dg切换进行迁移;
第一轮搭建ADG完成后,fail over DG备库 变成测试库给开发应用人员进行测试;
第二轮正式切换之前,搭建重建ADG环境, restore database正常,recover database报错
Thu Oct 28 21:35:11 2021
Warning: Recovery target destination is in a sibling branch of the controlfile checkpoint.
Recovery will only recover changes to datafiles.
Datafile 1 (ckpscn 20575410237) is orphaned on incarnation#=2
MRP0: Detected orphaned datafiles! Recovery will possibly be retried after flashback...
Errors in file /u01/app/oracle/diag/rdbms/oxxx/oxxxx/trace/oxxxx1\_pr00\_5100.trc:
ORA-19909: datafile 1 belongs to an orphan incarnation
ORA-01110: data file 1: '+DATA/oxxx/datafile/system.265.1087143661'
Managed Standby Recovery not using Real Time Apply
Recovery Slave PR00 previously exited with exception 19909
Thu Oct 28 21:35:32 2021 MRP0: Background Media Recovery process shutdown (oxxx1)
二、问题排查
2.1 检索相关文档
检索MOS有没有相关的文章,找到了一篇几乎类似的!
ORA-19906 and ORA-19909 at standby site (Doc ID 1509932.1)
Datafile 1 (ckpscn 7502822792898) is orphaned on incarnation#=1
MRP0: Background Media Recovery terminated with error 19909
Thu Nov 22 14:45:00 MET 2012
Errors in file < directory >/SGSDGB/admin/bdump/sgsdgb\_mrp0\_20506.trc:
ORA-19909: datafile 1 belongs to an orphan incarnation \[5\]
ORA-01110: data file 1: '< directory >/SGSDGB/data02/system01.dbf'
Thu Nov 22 14:45:00 MET 2012
Errors in file < directory >/SGSDGB/admin/bdump/sgsdgb\_mrp0\_20506.trc:
ORA-19909: datafile 1 belongs to an orphan incarnation
ORA-01110: data file 1: '< directory >/SGSDGB/data02/system01.dbf'
2.2 检查问题是否匹配
遇到有mos差不多的文档故障处理,啥也别说了,看看是不是匹配这个问题!
Redo apply at standby site suddenly failed as shown in the alert.log:
CAUSE
This occurs because the standby database, for various reasons, is opened with resetlogs and information on that resides in the FRA. RMAN will implicitly catalog the FRA thus causing information on this “test” incarnation to be inserted into the mounted standby controlfile. Therefore information on a new incarnation exists.
报错的场景是说DG recover的时候报错,控制文件"化生"(翻译过来不一定准确incarnation )的问题;
场景往往发生在resetlogs后,产生新的版本的化生,但是RMAN的 FRA自动记录了化生并且将这个化生写入了新的控制文件当中,导致你的DG控制文件存在多个不同scn演进化生的版本;
那么这种情况和我们本次遇到的问题非常的匹配,因为这个新环境DG之前做过一次resetlogs,只要操作一次resetlogs,那么控制文件就会产生一次新的化生(incarnation);
由于我们没有百分百的清理干净,导致Oracle rman fra自动将上一次的resetlogs后的化生写入到了控制文件当中,恢复的时候化生版本不对!
最终导致报错!接下来就是进入DB查询对比了!
2.3 查询对比
This is the primary database's incarnation:
RMAN> list incarnation of database;
using target database control file instead of recovery catalog
DB Key Inc Key DB Name DB ID STATUS Reset SCN Reset Time
------- ------- -------- ---------------- --- ---------- ----------
1 1 SGSOPA 791150137 CURRENT 121289826 09-OCT-09
This is the standby database's incarnation:
RMAN> list incarnation of database;
using target database control file instead of recovery catalog
DB Key Inc Key DB Name DB ID STATUS Reset SCN Reset Time
------- ------- -------- ---------------- --- ---------- ----------
1 1 SGSOPA 791150137 PARENT 121289826 09-OCT-09
2 2 SGSOPA 791150137 CURRENT 7502821558550 22-NOV-12
In standby, execute:
RMAN> reset database to incarnation 1;
实际操作与MOS一致,只是实际环境inc2的时间是上一次resetlogs open第一次搭建dg fail over的时间点!
执行上述操作,recover database;不在报错!
问题到这里就算是解决问题了,进入下一环节,问题学习。
三、问题学习
参考文章
https://www.cnblogs.com/askscuti/p/10939593.html
https://www.cnblogs.com/cqubityj/p/3492569.html
3.1 Oracle incarnation是什么?
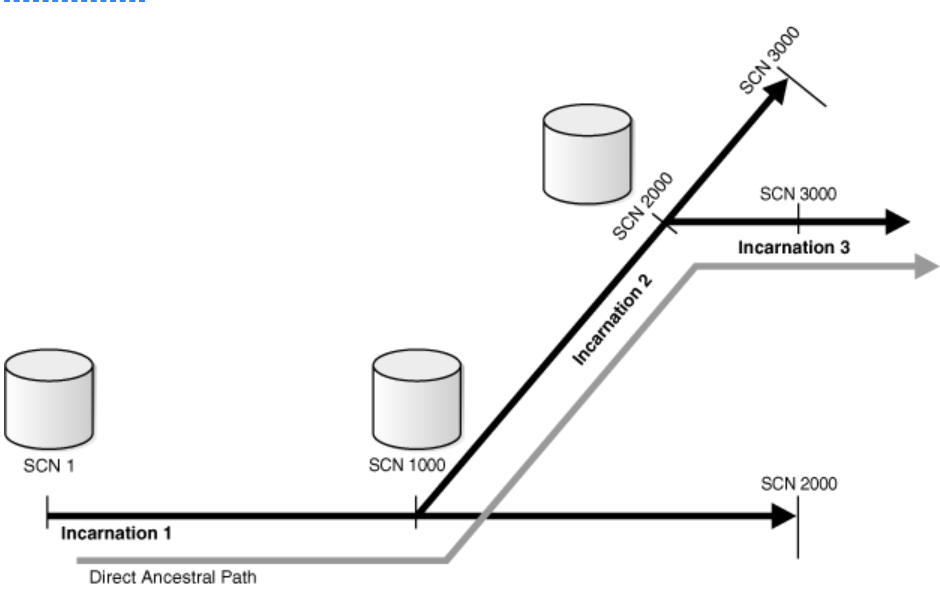
其实一张图就能解释问题,如果正常情况数据库一直正常运行,那么就只有一个化生,SCN一直往一个方向走;
但是在某些场景下,DB使用了resetlogs 不完成的恢复时,那么就会产生一个新的化生,因为你的SCN方向以及和完全恢复的方向不同了。
如何查询当前数据库的化生
SQL> select INCARNATION#,RESETLOGS_CHANGE#,RESETLOGS_TIME,STATUS from v$database_incarnation;
3.2 如何避免出现这个问题呢?
那么如何避免可能出现的控制文件化生导致恢复的干扰的情况呢?MOS有方法二,还是上面的同一篇文章。
Option #2:
Clear the FRA information associated with the resetlogs executed against the standby.
1) remove archivelog files and/or controlfile autobackups which were generated by the
standby when it was activated (opened with resetlogs).
Leave only the archivelog files received from the primary.
2) consider refreshing standby controlfile from primary to remove unnecessary
incarnation information from standby controlfile's v$database_incarnation.
3) start manual recovery, applying the next archivelog from the primary
site to confirm that recovery will now continue
4) restart automatic recovery at the standby site
1.将上一次resetlogs库open之后产生的archive log ,log进行删除清理;
2.将上一次resetlogs库open之后产生的控制文件自动备份的文件进行清理;
3.使用主库最新的控制文件对DG库的控制文件进行覆盖;
4.再次进行recover之后,开启MRP进程自动恢复。
前三步骤才是重点!
