




1 执行流程
执行器整体执行流程如图所示:
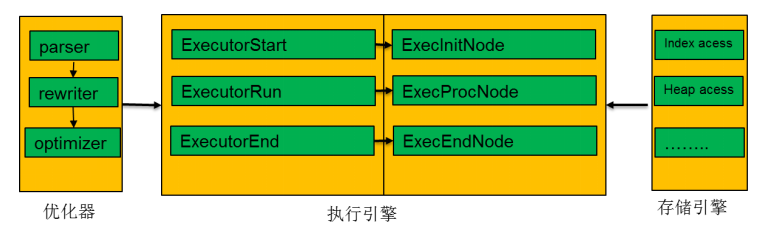
执行器整体执行流程图
本节描述了执行器在整体数据库架构中所处的位置,执行引擎的执行流程非常清晰,分成3段。
(1) 初始化:
在这个阶段执行器会完成一些初始化工作,通常的做法是遍历整个执行树,根据每个算子的不同特征进行初始化执行。比如HashJoin这个算子,在这个阶段会进行hash表的初始化,主要是内存的分配。
(2) 执行阶段:
这个阶段是执行器最重要的部分,在这个阶段完成对于执行树的迭代(Pipeline)遍历,通过从磁盘读取数据,根据执行树的具体逻辑完成查询语义。
(3) 清理阶段:
因为在执行器的初始化阶段向系统申请了资源,在这个阶段要完成对于资源的清理。比如在HashJoin初始化的时候对于Hash表内存申请的释放。
2 执行算子
上节提到表达一个SQL语句需要很多不同的代数运算符的组合。openGauss为了完成这些代数运算符的功能,引入了很多算子(Operator),算子是执行树的最基本的运算单元,这些算子按照不同的功能划分,有如下几种:
1. 控制算子
这些算子并不映射代数运算符,是为了执行器完成一些特殊的流程引入的算子,主要有以下几种算子。如下表所示:
控制算子
算子类型 | 描述 |
Result | 处理仅需要一次计算的条件表达式或insert中的value子句 |
Append | 处理大于或者等于2的子树流程 |
BitmapAnd | 需要对两个或以上位图进行并操作的流程 |
BitmapOr | 需要对两个或以上位图进行或操作的流程 |
RecursiveUnion | 用于处理with recursive递归查询 |
Limit | 用于处理下层数据的limit操作 |
VecToRow | 用于普通执行器和向量化执行器之间数据传输的转换 |
2. 扫描算子
扫描算子负责从底层数据来源抽取数据,数据来源可能是来自文件系统,也可能来自网络(分布式查询)。扫描节点都位于执行树的叶子节点,作为执行数的数据输入来源。如下表所示:
扫描算子
算子类型 | 描述 |
Seqscan | 顺序扫描行存 |
CstoreScan | 顺序扫描列存 |
DfsScan | 顺序扫描HDFS类文件系统 |
Stream | 顺序扫描来自网络的数据流,数据流一般来自其他子树执行分发到网络中的数据 |
BitmapHeapScan | 通过bitmap结构获取元组 |
BitmapIndexScan | 利用索引获取满足条件的bitmap结构 |
TidScan | 通过事先得到的Tid来扫描heap上的数据 |
SubQueryScan | 从子查询的输出来扫描数据 |
ValueScan | 扫描Values子句产生的数据源 |
CteScan | 扫描cte表达式 |
WorkTableScan | 扫描RecursiveUnion产生的迭代数据 |
FunctionScan | 扫描Function产生的批量数据 |
IndexScan | 扫描索引得到Tid,然后从heap上扫描数据 |
IndexOnlyScan | 在某些情况下,可以只用扫描索引就能得到查询想要的数据,因此不需要扫描heap |
ForgeinScan | 从用户定义的外表数据源扫描数据 |
3. 物化算子
这类节点因为算法要求,在做算子逻辑处理的时候,要求把下层的数据进行缓存处理,因为对于下层算子返回的数据量不可提前预知,因此需要在算法上考虑数据无法全部放置到内存的情况,如下表所示。
物化算子
算子类型 | 描述 |
Sort | 对下层数据进行排序,例如快速排序 |
Group | 对下层已经排序的数据进行分组 |
Agg | 对下层数据进行分组(无序) |
Unique | 对下层数据进行去重操作 |
Hash | 对下层数据进行缓存,存储到一个hash表里 |
SetOp | 对下层数据进行缓存,用于处理intersect等集合操作 |
4. 连接算子
这类算子是为了应对数据库中最常见的join操作,根据处理算法和数据输入源的不同分成以下几种,如下表所示。
连接算子
算子类型 | 描述 |
Nestloop | 对下层两股数据流实现循环嵌套连接操作 |
MergeJoin | 对下层两股排序数据流实现归并连接操作 |
HashJoin | 对下层两股数据流实现哈希连接操作 |
同时为了应对不同的连接操作,openGauss定义了如下的连接类型。定义两股数据流,一股为S1(左),一股为S2(右),Join算子连接类型如下表所示:
Join算子连接类型
Join算子连接类型 | 描述 |
Inner Join | 内连接,对于S1和S2上满足条件的数据进行连接操作。 |
Left Join | 左连接,对于S1没有匹配S2的数据,进行补空输出。 |
Right Join | 右连接,对于S2没有匹配S1的数据,进行补空输出。 |
Full Join | 全连接,除了Inner Join的输出部分,对于S1,S2没有匹配的部分,进行各自补空输出 |
Semi Join | 半连接,当S1能够在S2中找到一个匹配的,单独输出S1 |
Anti Join | 反连接,当S1能够在S2中找不到一个匹配的,单独输出S1 |
上述三个Join算子都已经支持上述6个不同的连接类型。
NestLoop算子:对于左表中的每一行,扫描一次右表。算法简单,但非常耗时(计算笛卡尔乘积),如果可以用索引扫描右表则这可能是一个不错的策略。可以将左表的当前行中的值用作右索引扫描的键。
MergeJoin:在join开始前,先对每个表按照连接属性(join attributes)进行排序。然后并行扫描两个表,组合匹配的行形成join行。MergeJoin只需扫描一次表。排序可以通过排序算法或使用连接键上的索引来实现。
HashJoin:先扫描内表,并根据其连接属性计算hash值作为散列键(hash key)存入散列表(hash table)中。然后扫描外表,计算hash key,在hash table中找到匹配的行。
对于Join的表无序的情况,MergeJoin需要两个表扫描并进行排序,复杂度会达到O(nlogn),而NestLoop是一种嵌套循环的查询方式,复杂度到O(n^2)。而Hashjoin借助hash表来加速查询,复杂度基本在O(n)。
不过HashJoin只适用于等值连接,对于>、<、<=、>=这样的连接还需要NestLoop这种通用的连接方式来处理。如果连接键是索引列本来就有序,或者SQL本身需要排序,那么用MergeJoin的代价会比Hashjoin更小。
下面我们简单介绍下HashJoin执行流程。
HashJoin顾名思义就是利用Hash表来进行Join查询,Hash表的数据结构组织形式如下图示。
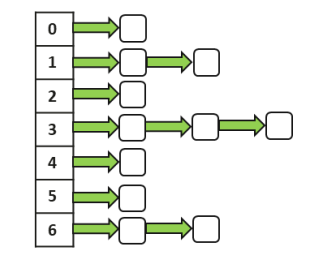
Hash表
可以看到Hash表根据Hash值分成多个桶,相同的Hash键值的元组用链表的方式串联在一起,因为hash算法的高效和hash表的唯一指向性,hashjoin的匹配效率非常高,但是hashjoin只能支持等值查询。
Hashjoin节点有两颗子树,一颗我们称之为外表,另外一颗我们称之为内表,内表输出的数据用于生成hash表,而外表生成的数据则在hash表上进行探查并返回join结果。
在内外表的选择上,优化器一般根据这两个子树的代价进行分析选择。因为Hash表需要申请内存进行存放,因此优化器倾向于输出行数少的子树作为内表,这样数据能够被内存存放的概率比较大,如果存放不下,则需要进行下盘操作。
HashJoin主要执行流程如下面描述:
(1) 扫描内表元组,根据连接键计算hash值,并插入到hash表中的根据hash值计算出来的槽位上。这个步骤中,会反复读取内表元组直到把内表读取完全,并将hash表构建出来。
(2) 扫描外表元组,根据连接键计算hash值,直接查找hash表进行连接操作,并将结果输出,在这个步骤中,会反复读取外表直到外表读取完毕,这个时候join的结果也将全部输出。
上面说了,如果当前内表的元组无法全部放在内存里,会进行下盘操作,hashjoin对于下盘支持的设计思想非常精妙,采用了典型的分而治之算法。其主要的流程如下描述。
(3) 根据内表和外表的键值的hash值,对内表和外表进行分区,经过分区之后,内表和外表划分成很多小的内外表,这里的划分原则是相同的hash值分区之后数据要划分到相同下标的内外表中,同时内表的数据要能够存放在内存里。
(4) 取相同下标的内外表,重复(1)、(2)里面的算法进行元组输出。
(5) 重复第(4)步的操作只到处理完所有的经过分区后的内外表。
3 表达式计算
除了算子,为了代数运算符的完备性,我们还需要表达式计算。根据SQL语句的不同,表达式计算可能产生在每个算子上,用于进一步处理算子上的数据流,主要有以下两个功能:
- 过滤:根据表达式的逻辑,过滤掉不符合规则的数据。
- 投影:根据表达式的逻辑,对数据流进行表达式变换,产生新的数据。
表达式计算的核心是对于表达式树的遍历和计算,前面说到算子也是用树来表达执行计划。树这个基础的数据结构在执行器的流程中扮演了非常重要的位置。
我们看下面这个SQL:
SQL2:select w_id from warehouse where 2*w_tax + 0.9 > 1 and w_city != ‘Beijing’;
SQL语句where条件后面的就是SQL表达式,如果以树的形式表达展现成如图所示。
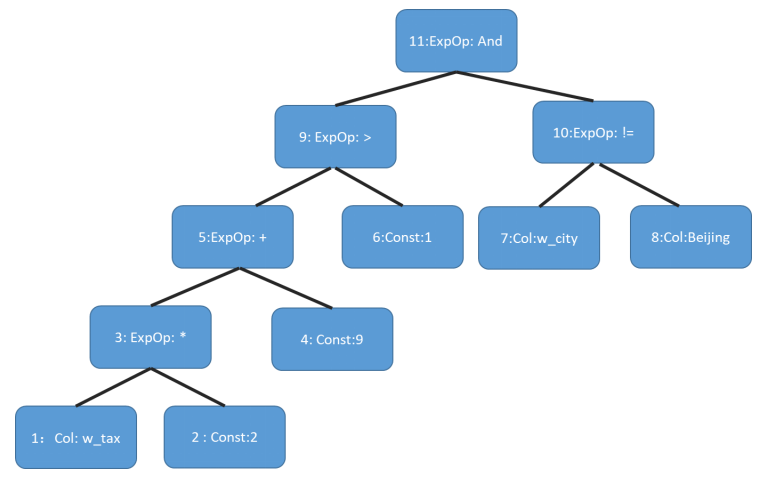
SQL语句树的表达形式
表达式计算对算子上的数据流进行计算,通过遍历表达式计算树完成整体的表达式计算对算子上的数据流进行计算,通过遍历表达式计算树完成整体的表达式计算,(为了便于说明,我们对上述表达式树每个节点进行了编号,见节点前的数字),可以看到上面的图里有些树节点中标注的是 Const,这代表这个节点是一个定值节点,存储了一个定值,有些节点中标注的是ExpOp,这代表这个节点是一个计算节点,根据表达式的不同有不同的计算方法,有些节点标注的是Col, 代表从表中的某个列中读取数据。上述的表达式计算的详细的流程如下:
(1) 根节点11代表一个AND操作符,AND逻辑是只要有一个子树的结果为false,则提前终止运算,否则进行下一个子树运算,下面有两个子表达式,我们先处理节点9, 首先递归遍历到其子节点3。
(2) 节点3代表了一个乘法,其有两个子节点1,2,从节点1列中取得w_tax的值,从节点2中取得定值2,然后进行乘法运算,计算数据存储到节点3引擎的一处暂存空间
(3) 节点5代表一个加法运算,其有两个子节点3,4,因此从表达式树节点4上取定值9,表达式3的结果刚才在第二步已经计算了,我们只需要读取出来,运算结果集存储到节点5暂存空间里。
(4) 节点9代表一个比较运算,其有两个子节点5, 6,因此将表达式树节点5存储的数据和树节点6上的数据定值1进行大于比较,如果结果为false,则提前终止当前的表达式运算,跳入下一行,重新从(1)开始计算,如果为true,则进行下一个子表达式的计算。
(5) 节点9已经处理完毕,我们接着处理节点10。
(6) 节点10代表字符串不等于比较运算,其有两个子节点7,8,从节点7中进行取得w_city值,同时从节点8中取得定值字符串“Beijing”, 然后进行不等于字符串比较运算,如果为true,输出tuple, 否则重新从(1)开始计算。
由此可见,通过遍历整个表达式树,根据表达式树不同节点的类型做出相应的动作,有些是对于数据的读取,有些是进行函数计算。表达式计算树叶子节点都来自数据流中的数据或者定值,而非叶子节点都是计算函数。
