




cloneable接口的作用
cloneable其实就是一个标记接口,只有实现这个接口后,然后在类中重写Object中的clone方法,然后通过类调用clone方法才能克隆成功,如果不实现这个接口,则会抛出CloneNotSupportedException(克隆不被支持)异常。Object中clone方法:

这里有一个疑问,Object中的clone方法是一个空的方法,那么他是如何判断类是否实现了cloneable接口呢?
原因在于这个方法中有一个native关键字修饰。
native修饰的方法都是空的方法,但是这些方法都是有实现体的(这里也就间接说明了native关键字不能与abstract同时使用。因为abstract修饰的方法与java的接口中的方法类似,他显式的说明了修饰的方法,在当前是没有实现体的,abstract的方法的实现体都由子类重写),只不过native方法调用的实现体,都是非java代码编写的(例如:调用的是在jvm中编写的C的接口),每一个native方法在jvm中都有一个同名的实现体,native方法在逻辑上的判断都是由实现体实现的,另外这种native修饰的方法对返回类型,异常控制等都没有约束。
由此可见,这里判断是否实现cloneable接口,是在调用jvm中的实现体时进行判断的。
深入理解深度克隆与浅度克隆
首先,在java中创建对象的方式有四种:
一种是new,通过new关键字在堆中为对象开辟空间,在执行new时,首先会看所要创建的对象的类型,知道了类型,才能知道需 要给这个对象分配多大的内存区域,分配内存后,调用对象的构造函数,填充对象中各个变量的值,将对象初始化,然后通过构造方法返回对象的地址;
另一种是clone,clone也是首先分配内存,这里分配的内存与调用clone方法对象的内存相同,然后将源对象中各个变量的值,填充到新的对象中,填充完成后,clone方法返回一个新的地址,这个新地址的对象与源对象相同,只是地址不同。
另外还有输入输出流,反射构造对象等
下面通过几个例子来解析下浅度克隆与深度克隆的区别:
浅度克隆测试:
首先定义一个学生类
public class Student{private String name; //姓名private int age; //年龄private StringBuffer sex; //性别public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public StringBuffer getSex() {return sex;}public void setSex(StringBuffer sex) {this.sex = sex;}@Overridepublic String toString() {return "Student [name=" + name + ", age=" + age + ", sex=" + sex + "]";}}
其次定义一个学校类,类中重写clone方法
public class School implements Cloneable{private String schoolName; //学校名称private int stuNums; //学校人数private Student stu; //一个学生public String getSchoolName() {return schoolName;}public void setSchoolName(String schoolName) {this.schoolName = schoolName;}public int getStuNums() {return stuNums;}public void setStuNums(int stuNums) {this.stuNums = stuNums;}public Student getStu() {return stu;}public void setStu(Student stu) {this.stu = stu;}@Overrideprotected School clone() throws CloneNotSupportedException {// TODO Auto-generated method stubreturn (School)super.clone();;}@Overridepublic String toString() {return "School [schoolName=" + schoolName + ", stuNums=" + stuNums + ", stu=" + stu + "]";}}
最后定义一个main类来测试一下:
public static void main(String[] args) throws CloneNotSupportedException {School s1 = new School();s1.setSchoolName("实验小学");s1.setStuNums(100);Student stu1 = new Student();stu1.setAge(20);stu1.setName("zhangsan");stu1.setSex(new StringBuffer("男"));s1.setStu(stu1);System.out.println("s1: "+s1+" s1的hashcode:"+s1.hashCode()+" s1中stu1的hashcode:"+s1.getStu().hashCode());School s2 = s1.clone(); //调用重写的clone方法,clone出一个新的school---s2System.out.println("s2: "+s2+" s2的hashcode:"+s2.hashCode()+" s2中stu1的hashcode:"+s2.getStu().hashCode());}
测试结果:

可以看出s1与s2的hashcode不同,也就是说clone方法并不是把s1的引用赋予s2,而是在堆中重新开辟了一块空间,将s1复制过去,将新的地址返回给s2。
但是s1中stu的hashcode与s2中stu的hashcode相同,也就是这两个指向了同一个对象,修改s2中的stu会造成s1中stu数据的改变。但是修改s2中的基本数据类型与Stirng类型时,不会造成s1中数据的改变,基本数据类型例如int,在clone的时候会重新开辟一个四个字节的大小的空间,将其赋值。而String则由于String变量的唯一性,如果在s2中改变了String类型的值,则会生成一个新的String对象,对之前的没有影响。 这就是浅度克隆。
如何实现深度clone?(下面时第一种方法,另外使用序列化将student变成流,输入再输出也可以)
首先需要让student重写clone方法,实现cloneable接口
public class Student implements Cloneable{private String name;private int age;private StringBuffer sex;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public StringBuffer getSex() {return sex;}public void setSex(StringBuffer sex) {this.sex = sex;}@Overridepublic String toString() {return "Student [name=" + name + ", age=" + age + ", sex=" + sex + "]";}@Overrideprotected Student clone() throws CloneNotSupportedException {// TODO Auto-generated method stubreturn (Student)super.clone();}}
然后,在school的clone方法中将school中的stu对象手动clone一下。
@Overrideprotected School clone() throws CloneNotSupportedException {// TODO Auto-generated method stubSchool s = null;s = (School)super.clone();s.stu = stu.clone();return s;}
再次执行main方法查看结果:
public class Main {public static void main(String[] args) throws CloneNotSupportedException {School s1 = new School();s1.setSchoolName("实验小学");s1.setStuNums(100);Student stu1 = new Student();stu1.setAge(20);stu1.setName("zhangsan");stu1.setSex(new StringBuffer("男"));s1.setStu(stu1);System.out.println("s1: "+s1+" s1的hashcode:"+s1.hashCode()+" s1中stu1的hashcode:"+s1.getStu().hashCode());School s2 = s1.clone(); //调用重写的clone方法,clone出一个新的school---s2System.out.println("s2: "+s2+" s2的hashcode:"+s2.hashCode()+" s2中stu1的hashcode:"+s2.getStu().hashCode());//修改s2中的值,看看是否会对s1中的值造成影响s2.setSchoolName("希望小学");s2.setStuNums(200);Student stu2 = s2.getStu();stu2.setAge(30);stu2.setName("lisi");stu2.setSex(stu2.getSex().append("6666666"));s2.setStu(stu2);//再次打印两个school,查看结果System.out.println("-------------------------------------------------------------------------");System.out.println("s1: "+s1+" hashcode:"+s1.hashCode()+" s1中stu1的hashcode:"+s1.getStu().hashCode());System.out.println("s2: "+s2+" hashcode:"+s2.hashCode()+" s2中stu1的hashcode:"+s2.getStu().hashCode());}}
打印结果:
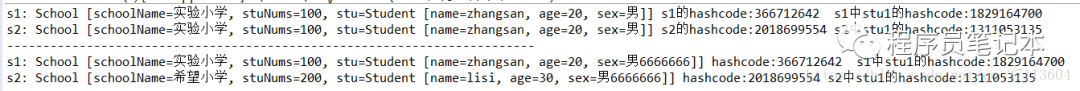
这里可以看到两个stu的hashcode已经不同了,说明这已经是两个对象了,但是在s2中修改sex的值,为什么还会影响到s1呢?
原因在于sex的类型是Stringbuffer,在clone的时候将StringBuffer对象的地址传递了过去,而StringBuffer类型没有实现cloneable接口,也没有重写clone方法。
这种情况应该怎么解决呢?
1.只实现浅度clone
2.stu2.setSex(new StringBuffer("newString")); 在设置stu2的sex时创建一个新的StringBuffer对象。
