




最近发现自己之前爬的某个网站更换了新的网页设计,于是重写了爬虫,在测试的时候突然被封了 IP,虽然说一般网站都不是永久封 IP,但是等不了的我还是尝试用 IP 池来突破该网站的反爬。

而就在我测试爬下来的 IP 能不能使用的时候,某提供 IP 池的网站也把我的 IP 封了!想不到现在的反爬策略已经如此激进。

开始之前
首先要清楚一些基本的网络状态号。
1XX消息 这一类型的状态码,代表请求已被接受,需要继续处理。(一般很少用)
2XX成功 这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。(但是未必能按请求返回结果)
200 OK 请求成功
201 Created 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立 202 Accepted 服务器已接受请求,但尚未处理
3XX重定向 这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,重定向目标在本次响应的 Location 域中指明。
301 Moved Permanently 被请求的资源已永久移动到新位置
302 Found 要求客户端执行临时重定向, 原始描述短语为“Moved Temporarily”
4xx客户端错误 这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理.
401 Unauthorized 该状态码表示当前请求需要用户验证
403 Forbidden 服务器已经理解请求,但是拒绝执行它(爬虫被禁的标志)
404 Not Found 请求失败,请求所希望得到的资源未被在服务器上发现
5xx服务器错误 这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理. 500 Internal Server Error 通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息。
502 Bad Gateway 作为网关或 "代理服务器" 工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 Service Unavailable 由于临时的服务器维护或者过载,服务器当前无法处理请求。
在爬虫过程中,我们最想看到的状态码是 200,最不想看到的是 403,当你看到 403,有相当大可能是你的爬虫被封了。
常见的反爬和反反爬策略
基于 Headers 和 UserAgent 的反爬
这应该是最基本的反爬,之前的文章提到过一些网站的 robots.txt 会明确指明哪些 header 名不能访问网站(比如一些国内的网站不会让国外某些搜索网站收录,因为这只会增加网站负载,但是无法带来真正有用的流量)
应对方式 随机更换 UserAgent。可以自己写一个 UserAgent 列表,然后随机挑一条作为当前爬虫请求的 UserAgent,也可以使用已经写好的库 fake_useragent 安装使用非常简单:
# 安装
pip install fake_useragent
>>> from fake_useragent import UserAgent
>>> ua = UserAgent(verify_ssl=False)
>>> ua.random
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.62 Safari/537.36'
基于用户行为的反爬
爬虫除了有英文 Spider 外,还有一个英文是 bot,也就是机器人,机器人固定的模式是比较容易识别的。爬虫这个机器人最明显的行为特征就是短期内密集多次请求网站数据。
应对方式1 减少请求数量,减少请求密度 在 Scrapy 中可以设置并发请求的数量,也可以设置下载延迟。前面提到我爬取的 IP 池网站,就是没有设置下载延迟,很快就被网站封了 IP。
应对方式2 变换 IP 通过多个 IP 代理你的请求进行爬虫,绕过同一个 IP 多次请求的反爬。
多说一句,基于用户行为能做的除了反爬,还能精准推送,精准拉黑。精准推送比如你多次搜索某些关键词,在网页中你会收到相关的广告;精准拉黑比如你使用百度云的破解插件或者修改版多次后,你会被限制下载等。
隐藏真实地址的动态网页反爬
之前笔者的文章写过 JS动态加载以及JavaScript void(0)的爬虫解决方案,实际上是动态网页中最基本的反爬。更高级的反爬,会把请求过程中的 XHR 对象的真实地址进一步隐藏,如果直接打开该XHR地址,你收到的内容可能是一样的,也可能什么内容都没收到。
应对方式1 下图中的网址就隐藏了真实网址,你可能需要去查看请求的头部信息猜测请求参数,或者直接通过发送相同的头部信息绕过反爬。
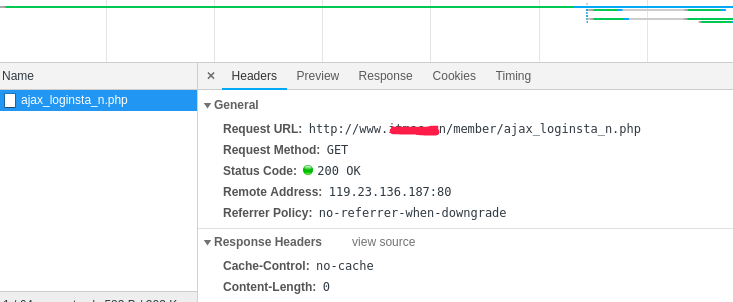
应对方式2 使用 selenium+phantomJS 框架调用浏览器内核模拟人浏览网站的行为,比如滚动鼠标,滑动验证码等来绕过反爬,这种应该是比较高级的反反爬策略了。
IP 池突破反爬策略
平时为了隐藏自己的网络行为,有些人会使用 VPN 来代理自己的流量,隐藏真实的IP地址。IP 池也是这个道理,通过不断变换请求的 IP 地址,伪装出低频访问的假象绕过反爬策略。
在 Scrapy 中你需要做的有:
爬取并存储可用 IP(当然,RMB玩家可以直接购买接口使用)
编辑并启用 IP 池中间件
提供 IP 池的网站有不少,并且大部分会提供免费易黄版和RMB玩家稳定版,我使用的是免费版,这里介绍两个
https://www.kuaidaili.com
http://www.xicidaili.com/
在爬取中务必设置合适的速度,否则还没爬到 IP 自己的先被封了。
IP 池是一个动态构建的仓库,无论是插入还是取出都必须验证该 IP 的有效性。如何验证?Python3 中有一个轻量的 requests 库(非标准库),你可以使用该IP地址请求某个网站看看返回的状态码是否是 200(有时候也可能是 3XX 这样的重定向状态码),是则证明 IP 可用,可用来爬取信息,否则直接移除,不保存。
示例
最好使用 try-except
避免因为报错退出
import requests
request_url = 'http://wwwbaidu.com'
proxy = {'http':'218.28.58.150:53281'}
try:
requests.get(url=request_url, proxies=proxy, timeout=5)
except Exception as e:
print(e)
整体的流程大概是
- 爬取 IP 网站
验证 IP
>status == 200 ? 入库:下一条
- 爬取数据
取出 IP
验证 IP
>status == 200 ? 出库, 执行爬虫:下一条
未找到可用 IP, 数据库为空 -> 爬取 IP 网站
按照下面的步骤,就大功告成啦。
建立
ipProxy.py
的文件(需要新建数据库表)在
middlewares.py
中创建中间件settings.py
中启用中间件
ipProxy.py
# 此类用于爬取和存储IP
import requests
from scrapy.selector import Selector
import pymysql
import time
# 链接数据库
conn = pymysql.connect(host="127.0.0.1", user="feson", passwd="feson", db="Spider", charset="utf8")
cursor = conn.cursor()
# UserAgent,这里也可以使用随机的
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
class GetRandomIp(object):
# 用于解析网页
def parse(self, next_url='/inha/1'):
"""
Parse Ip List From Site, Transfer to parse_detail
:param next_url:
:return: None
"""
print("Begin Parsing...")
response = requests.get(url='https://www.kuaidaili.com/free/intr'.format(next_url), headers=headers)
response = Selector(text=response.text)
tr_list = response.xpath('//*[@id="list"]/table/tbody/tr/td')
if tr_list:
self.parse_detail(tr_list)
for i in range(20):
time.sleep(5)
next_url = 'https://www.kuaidaili.com/free/intr/%d' % i
if next_url:
self.parse(next_url)
def parse_detail(self, tr_list):
"""
Parse Ip detail from list, transfer to insert into database
:param tr_list:
:return: None
"""
ip = tr_list.xpath('//td[@data-title="IP"]/text()').extract()
port = tr_list.xpath('//td[@data-title="PORT"]/text()').extract()
type = tr_list.xpath('//td[@data-title="类型"]/text()').extract()
speed = tr_list.xpath('//td[@data-title="响应速度"]/text()').extract()
for i in range(len(ip)):
self.insert_sql(ip[i], port[i], type[i])
def insert_sql(self, ip, port, type):
type = type.lower()
proxy_url = '{0}://{1}:{2}'.format(type, ip, port)
res = self.check_ip(type, proxy_url)
print(proxy_url)
if res:
cursor.execute(
"insert proxy_ip(ip, port, type) VALUES('{0}', '{1}', '{2}')".format(
ip, port, type
)
)
conn.commit()
def get_ip(self):
# 获取和检查IP
sql = "select * from proxy_ip ORDER BY RAND() LIMIT 1"
cursor.execute(sql)
ip, port, type = cursor.fetchone()
conn.commit()
type = type.lower()
proxy_url = '{0}://{1}:{2}'.format(type, ip, port)
res = self.check_ip(type, proxy_url)
if res:
return proxy_url
else:
self.delete_ip(ip)
return self.get_ip()
def check_ip(self, type, proxy_url):
request_url = 'http://hf.58.com/ershoufang/0'
try:
proxy = {type: proxy_url}
response = requests.get(url=request_url, proxies=proxy, timeout=5)
except Exception as e:
print(e)
return False
else:
code = response.status_code
if code == 200 or code == 302:
return True
else:
print('invalid ip and port')
return False
def delete_ip(self, ip):
sql = """delete from proxy_ip where ip='%s'""" % ip
cursor.execute(sql)
conn.commit()
ip = GetRandomIp()
if __name__ == '__main__':
ip = GetRandomIp()
ip.parse()
middlewares.py
import ipProxy
class RandomIpMiddleware(object):
def process_request(self, request, spider):
ip_proxy = ipProxy.ip.get_ip()
request.meta['proxy'] = ip_proxy
settings.py
# 添加以下参数, 没有就新建条目
...
# Retry many times since proxies often fail
RETRY_TIMES = 3
# Retry on most error codes since proxies fail for different reasons
RETRY_HTTP_CODES = [500, 503, 504, 400, 403, 404, 408]
# Enable or disable downloader middlewares
DOWNLOADER_MIDDLEWARES = {
'middleware.customUserAgent.RandomUserAgent': 543,
'finvest.middlewares.RandomIpMiddleware': 520,
}
https://github.com/FesonX/finvest-spider
(点击 查看原文 可直达)
欢迎 star , 有好的新闻源欢迎 pull request, 有问题欢迎 issue

不求赞赏/ 来个喜欢
