数据抓取中的密集任务处理,往往会涉及到性能瓶颈,这时候如果能有多进程的工具来进行支持,那么往往效率会提升很多。
今天这一篇分享在R语言、Python中使用调用多进程功能进行二进制文件下载。
导入待下载的文件:
library("dplyr") mydata<-read.csv("D:/Python/File/toutiaoreport.csv",stringsAsFactors = FALSE,check.names = FALSE) 抽取报告的url和报告名称: mydata1<-mydata[1:10,] %>% .[,c("title","path")] mydata1$path <- paste0("https://mlab.toutiao.com/report/download/",mydata1$path) mydata1$title<-sub("\\?","",mydata1$title)

在R语言中,文件下载的思路一般有三种可选方案:
方案1——构建显示循环:
#构造下载程序:myworks<-function(data){ setwd("D:/R") dir.create("folder1",showWarnings=FALSE) for(i in 1:nrow(data)){ download.file(data$path[i],paste0("./folder1/",data$title[i],".pdf"),quiet=TRUE, mode = "wb") cat(sprintf("正在下载第【%d】页",i),'\n') } cat("所有下载任务全部完成!","\n") } system.time(myworks(mydata1))

一共10个PDF文件,下载过程未设置等待时间,平均4.5m,一共44.5m,总耗时100m。
方案2——使用plyr包中的向量化函数
###使用向量化函数
library("plyr")
library("dplyr")
library("foreach") mylist<-foreach(x=1:nrow(mydata1),.combine='c') %do% list(mydata1[x,]) 这一句将报告的链接和标题构造成列表模式(l_ply支持输入的参数是列表) setwd("D:/R") dir.create("folder2",showWarnings=FALSE) downloadCSV <- function(filelinks) { download.file(filelinks$path,destfile=paste0("D:/R/folder2/",filelinks$title,".pdf"),quiet=TRUE, mode = "wb") } url <- "https://mlab.toutiao.com/report/download/"system.time( l_ply(mylist,downloadCSV,.progress = "text") )

有点惨,同样的10个pdf文档,耗时机会没啥变化,这一次是99.89,比上一次99.91只节省了0.02m,不过我使用的校园网(网速特别烂的那种,感兴趣可以在宽带性能比较高的条件下再测试一下)
方案3——使用多进程包进行并发处理:
library("parallel")
library("foreach")
library("iterators")
这里使用的多进程包是foreach包,你也可以尝试使用Parallel包来处理。
downloadCSV <- function(filelinks) {
tryCatch({ download.file(filelinks$path,destfile=paste0("D:/R/folder3/",filelinks$title,".pdf"),quiet=TRUE, mode = "wb")
"OK" },error=function(e){
"Trouble" }) } system.time({
library("doParallel") setwd("D:/R") dir.create("folder3",showWarnings=FALSE) cl<-makeCluster(4) registerDoParallel(cl) foreach(d=mylist, .combine=c) %dopar% downloadCSV(d) stopCluster(cl) })

这次一共使用了……99.46,好吧,我可能用的假的多进程,不过总之总耗时少了不是嘛,从99.91到98.72,还是节省了将近1.19秒。
而且代码看起来又优雅了不少(好吧我编不下去了~_~)
对于R语言的多进程目前我还了解的不多,如果以后有新的理解会从新梳理这一块,感兴趣的也可以自行探索foreach这个包的内部多进程执行机制。
Python:
import time,os
from urllib import request
import threading
from multiprocessing import Pool
import pandas as pd
###数据提取 os.chdir("D:/Python/File") mydata = pd.read_csv("toutiaoreport.csv",encoding='gbk') mydata1 = mydata.loc[:9,["title","path"]] mydata1['path'] = ["https://mlab.toutiao.com/report/download/" + path for path in mydata1['path']] mydata1['title'] = [text.replace("?","") for text in mydata1.title]
方案1——使用显式声明的循环进行下载:
def getPDF(mydata1): os.makedirs("folder1") os.chdir("D:/Python/File/folder1") i = 0 while i < len(mydata1): print("正在下载第【{}】个文件!".format(i+1)) request.urlretrieve(mydata1['path'][i],mydata1['title'][i]+".pdf") i += 1if __name__ == '__main__': t0 = time.time() getPDF(mydata1) t1 = time.time() total = t1 - t0 print("消耗时间:{}".format(total))

居然比R语言的循环慢了三秒钟,接下来尝试使用多进程/多线程来尝试下载这些PDF文档。
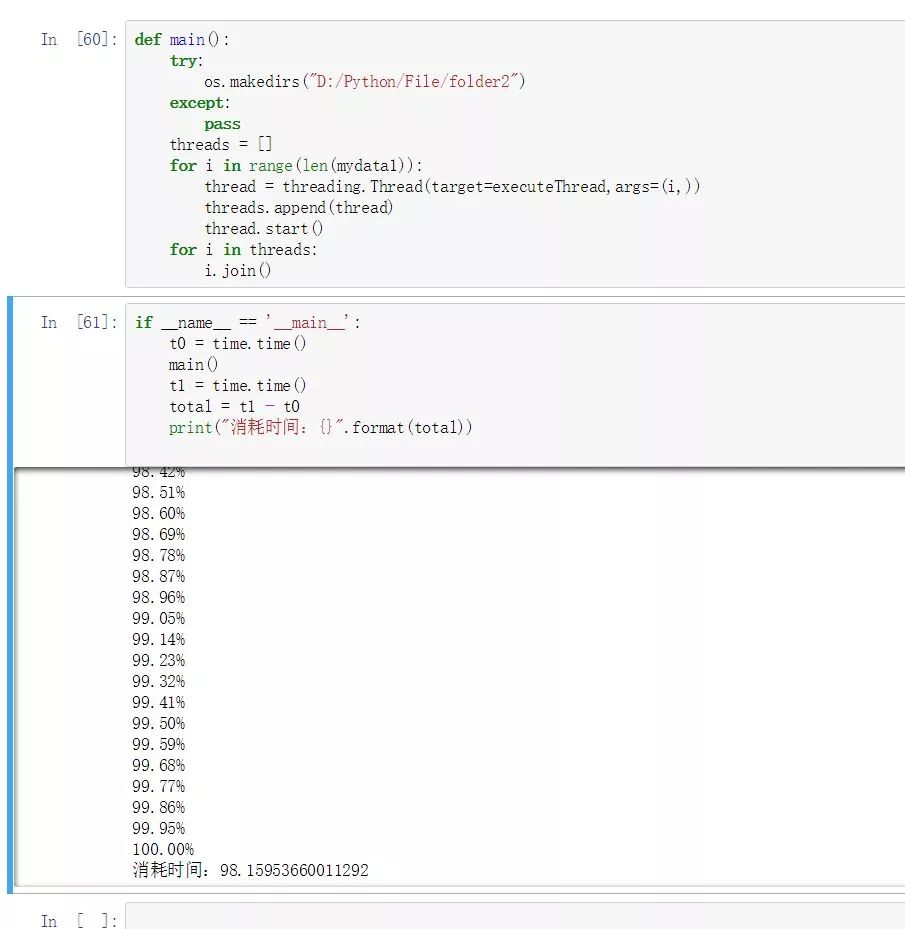
方案2——使用threading包提供的多线程方式进行下载:
def executeThread(i): request.urlretrieve(mydata1['path'][i],"D:/Python/File/folder2/"+mydata1['title'][i]+".pdf")
def main():
try: os.makedirs("D:/Python/File/folder2")
except:
pass
threads = []
for i in range(len(mydata1)): thread = threading.Thread(target=executeThread,args=(i,)) threads.append(thread) thread.start() for i in threads: i.join()
if __name__ == '__main__': t0 = time.time() main() t1 = time.time() total = t1 - t0 print("消耗时间:{}".format(total))
总耗时98.15953660011292,仅仅比显式循环节省了四秒,看起来优势并不是很大!
方案3——使用multiprocessing包提供的多进程功能
links = mydata1['path'].tolist()
def downloadPDF(i): request.urlretrieve(i,os.path.basename(i))
def shell():
#指定路径 if not os.path.exists("D:/Python/File/folder3"): os.makedirs("D:/Python/File/folder3") os.chdir("D:/Python/File/folder3")
else: os.chdir("D:/Python/File/folder3")
#计时开始: t0 = time.time()
#开启多进程: # Multi-process pool=Pool(processes=4) pool.map(downloadPDF,links) pool.close() t1 = time.time() total = t1 - t0 print("消耗时间:{}".format(total))
if __name__ == "__main__": shell()
当使用multiprocessing包的进程池功能时,我的代码运行出现锁死挂起的状态,就是没有输出也不退出,甚至不能强制中断,查了一下是Windows平台对于forks机制的特殊问题,算是个坑吧。
我自己对于多进程理解的极其肤浅,这里先占个坑,等我理解深入了,找到好的解决方案来回来填~-~
在线课程请点击文末原文链接:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File

欢迎关注数据小魔方qq交流群