




Python 两行代码设置 Scrapy UA
摘要:代理 UserAgent 设置方法汇总。
许多网站设有反爬措施,要想顺利爬取,就需要反反爬措施,其中,设置随机 User-Agent 伪装请求头是一项基本措施,能够避免网站直接识别出你是一个爬虫而封掉你。随机 UA 设置方法有很多种,有的复杂,有的简单到只需一行代码,下面来一一介绍。
▌常规设置 UA
先说不使用 Scrapy 的用法。比较方便的方法是使用 fake_useragent
包,这个包内置大量的 UA 可以随机替换,比自己去搜集要方便很多,来看一下如何操作。
先通过下面一行命令安装好fake_useragent
包:
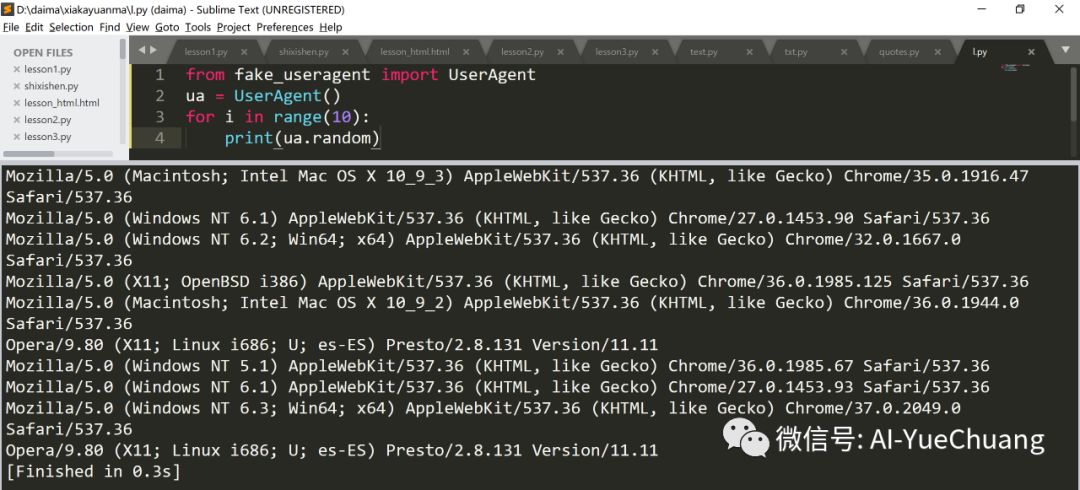
pip install fake-useragent使用 ua.random 方法,可以随机生成各种浏览器的 UA:
from fake_useragent import UserAgent
ua = UserAgent()
for i in range(10):
print(ua.random
AI悦创温馨提示:
在 sublime text3 里面 input 需在控制台运行;
for循环一般在循环次数有限时使用,无限则使用 while ;
以下就用导入 math 库为示例:
Ⅰ. import 模块名称(math):导入整个模块;>>> 使用这个函数时形式是:模块.函数名称 >>> math.sqrt()
Ⅱ. from 模块名称(math) import 函数名称(sqrt); >>> 使用这个函数时的形式是:sqrt()
区别:Ⅰ 是导入整个模块包含该模块的函数,Ⅱ 是我只需要这个模块当中的这么一个函数,其他的不需要。
如果只想要某一个浏览器的,比如 Chrome ,那可以改成 ua.chrome
:
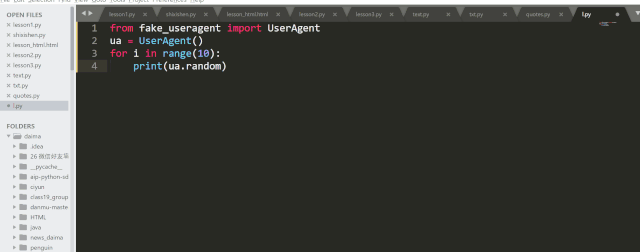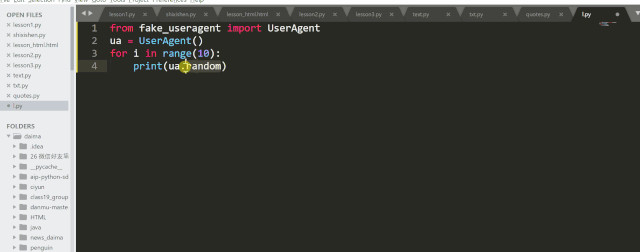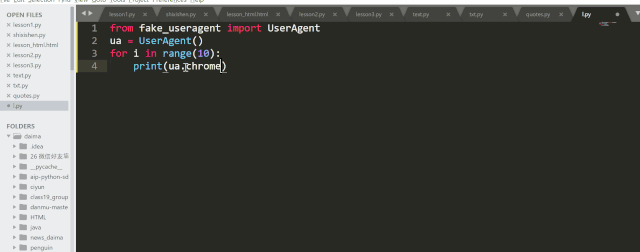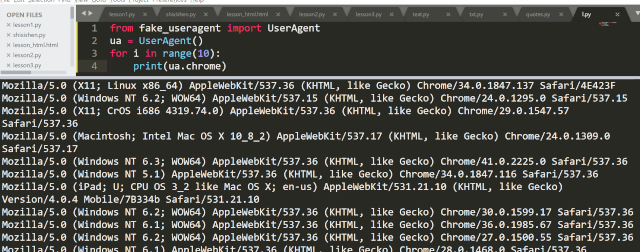
下面,我们来介绍在 Scrap
下面,我们来介绍在 Scrapy 中设置随机 UA 的几种方法。
先新建一个 Project,命名为 wanojia
,测试网站选择:http://httpbin.org/get
。
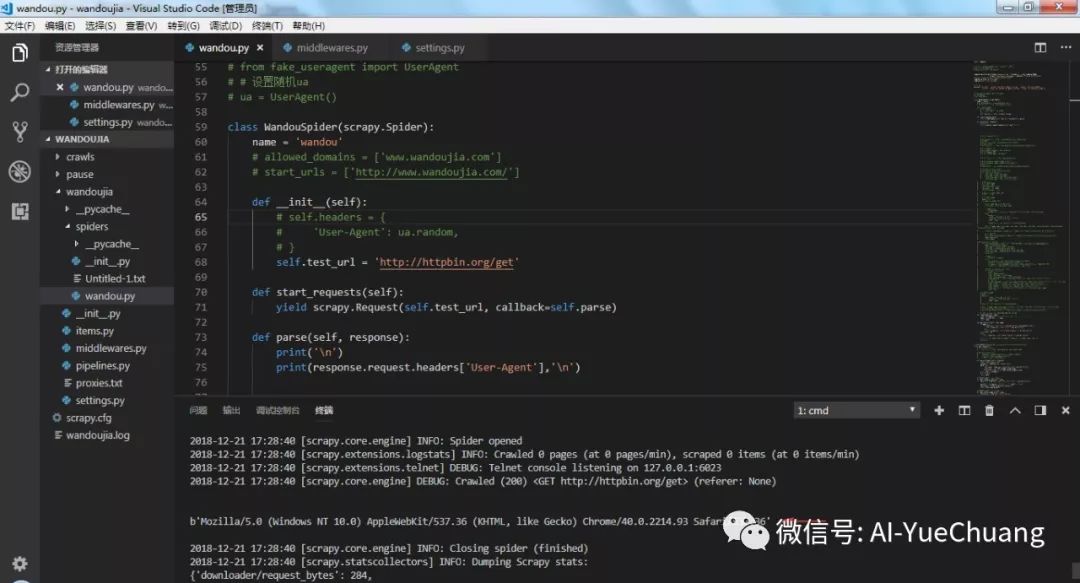
先来看看不添加 UA 会得到什么结果,可以看到 UA 显示scrapy
,爬虫就暴露出来了,很容易被封。
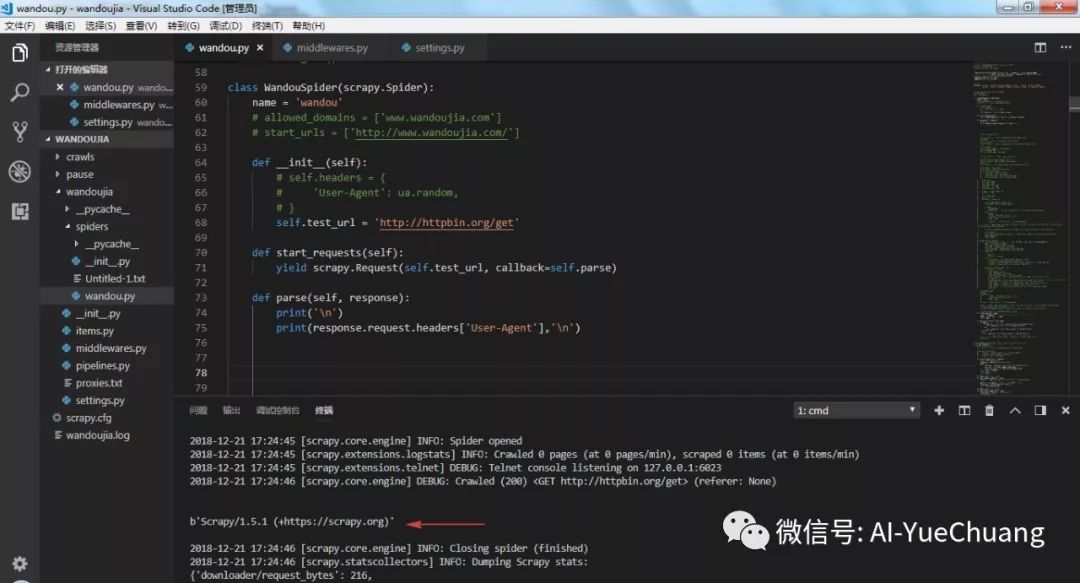
下面,使用几种方法添加上 UA 。
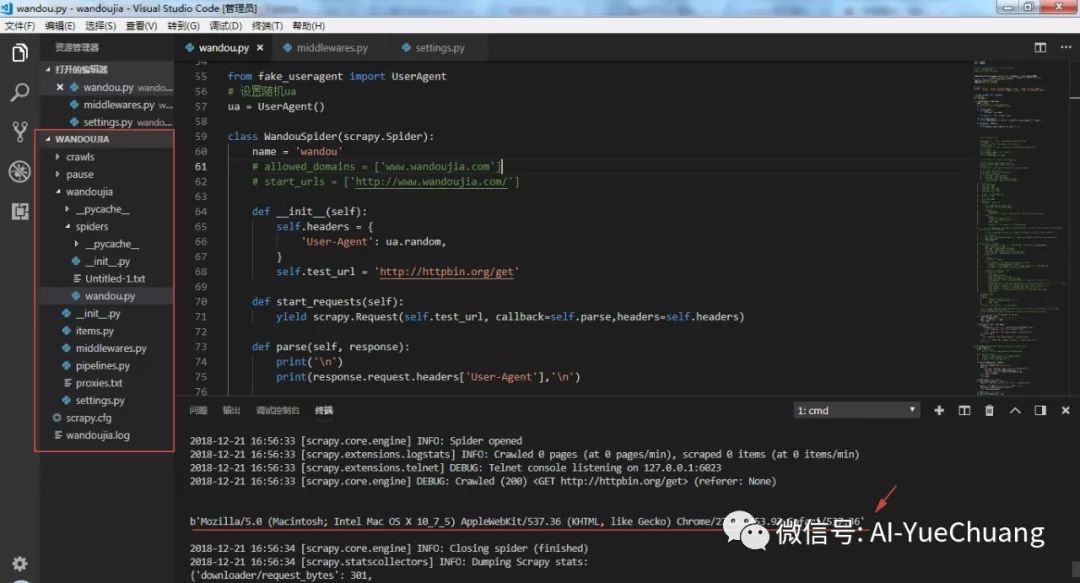
▌直接设置 UA
第一种方法是和上面程序一样,直接在主程序中设置 UA,然后运行程序,通过下面这句命令可以输出该网站的 UA,见上图箭头处所示,每次请求都会随机生成 UA,这种方法比较简单,但是每个 requests 下的请求都需要设置,不是很方便。
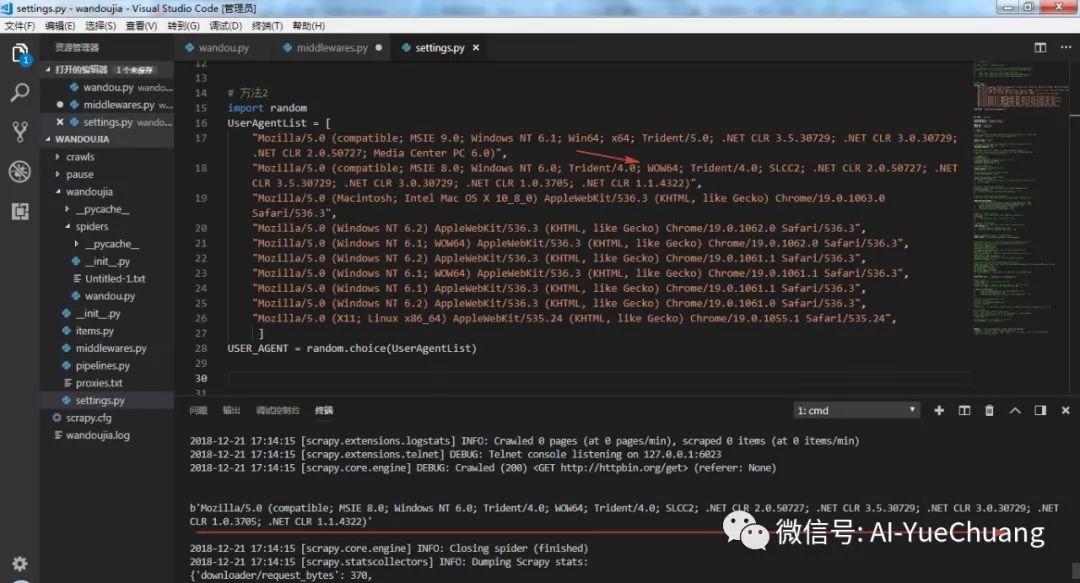
第二种方法是手动在 settings.py 文件中手动添加一些 UA,然后通过 random.choise
方法随机调用,这种方法需要自己去找 UA,且代码不够精简。
▌middlewares.py 中设置 UA
第三种方法,是使用 fake-useragent 包,在 middlewares.py 中间件中改写 process_request() 方法,添加以下几行代码即可。
from fake_useragent import UserAgent
class RandomUserAgent(object):
def process_request(self, request, spider):
ua = UserAgent()
request.headers['User-Agent'] = ua.random
然后,我们回到 settings.py
文件中调用自定义的 UserAgent,注意这里要先关闭默认的 UA 设置方法才行。
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'wandoujia.middlewares.RandomUserAgent': 543,
}
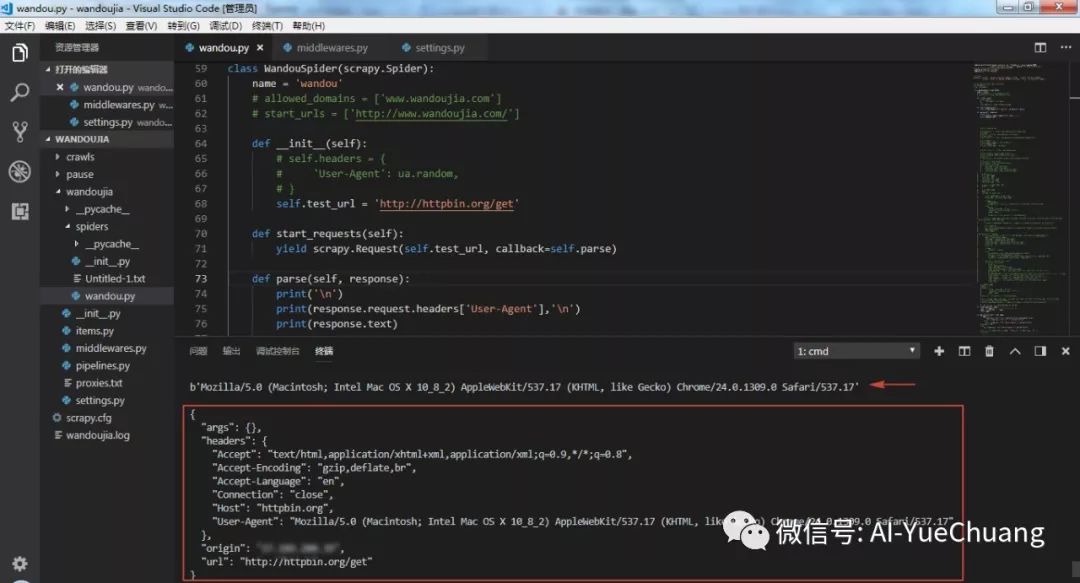
可以看到,随机 UA设置成功。
▌一行代码设置 UA
上面几种方法其实都不太方便,代码量也比较多,还有更简单的方法,一行代码就可以设置好。就是使用一款名为scrapy-fake-useragent
的包。
先安装好该包,接着在 settings.py 中启用随机 UA 设置命令就可以了,非常简单省事。
pip install scrapy-fake-useragentDOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # 关闭默认方法
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400, # 开启
}
输出一下 UA 和网页 Response,可以看到随机 UA 设置成功。
以上就是 Scrapy 中设置随机 UA 的几种方法,推荐最后一种方法,即安装 scrapy-fake-useragent
库。
另外,反爬措施除了设置随机 UA 以外,还有一种重要措施是设置随机 IP,我们之后文章介绍。
我是AI悦创,依然不会定时给你们分享一些有趣好玩实用的东西,欢迎关注~
警察蜀黍!就是这个人!脑子简直有泡!还不赶紧关注一下!

