




大数据处理框架,是一个“老生常谈”的话题了。大家都很清楚,技术演进在我们信息化时代的价值。它从诞生至今,也在不断地颠覆、不断地演化。

LAMBDA -> KAPPA 技术演进
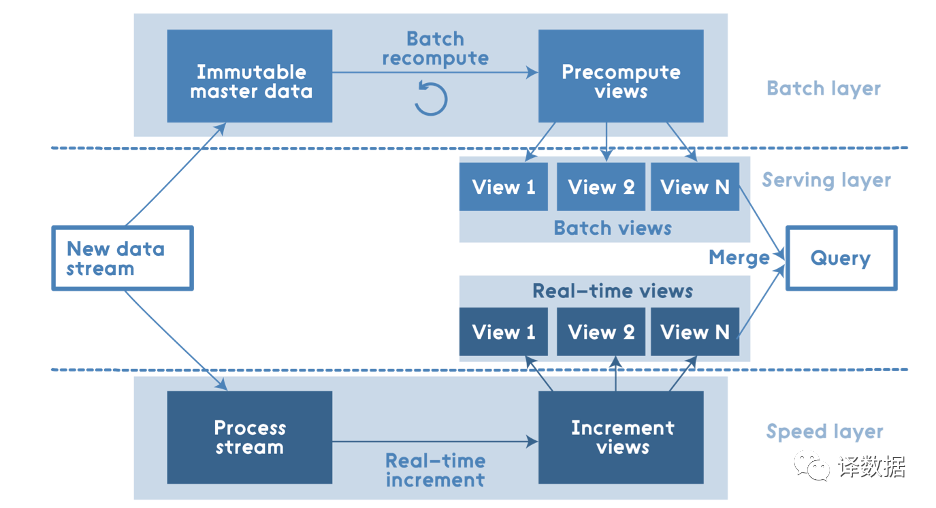
Lambda架构优势在于,将数据处理的需求,按照实时和离线进行区分。离线部分,可以追求更好的吞吐和准确性,实时部分,则可以获得更低的延迟。随着数据规模和数据业务的发展,Lambda架构暴露出如下的问题:
1. 实时与离线计算结果不一致引起的数据口径问题。因为离线和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
2. 维护成本较大。如果在离线和实时pipeline输出相同的指标,那么上游业务逻辑和数据的变更,都需要2边同时修改上线,那么整体运维和开发成本较大。
3. 数据冗余导致存储开销较大。数据仓库的典型设计,会产生大量的中间结果表,造成数据快速膨胀,加大存储压力。
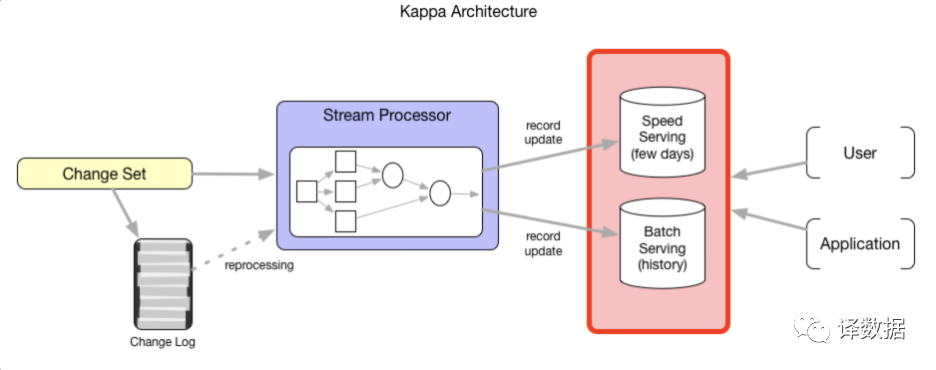
KAPPA架构
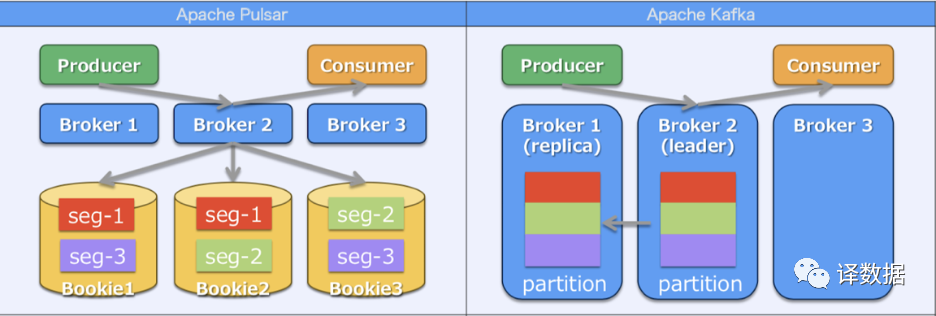
2. Flink Exactly Once Semantics
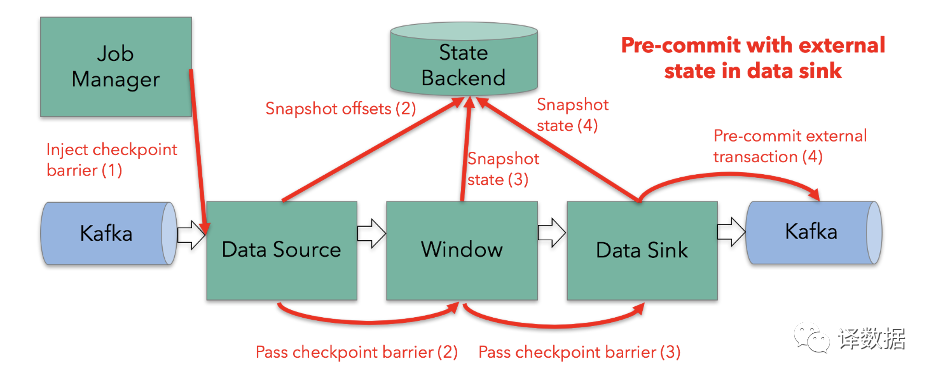
例如,Flink从Kafka消费,经过处理之后,把结果输出到Kafka。在这种场景下,Flink 端到端的Exactly-Once语义,是借助了Flink Checkpoint机制,Operator状态管理的能力,以及输出端(Sinker)事务的支持。另外,如果在设计Sinker能支持幂等操作,可以有效解决重复处理导致结果不正确的问题。Flink最小的处理数据的单位是消息,它比Spark Streaming的Micro Batch能够更容易实现每个处理环节的Exactly-Once。
3.DeltaLake/Apache Hudi/Iceberg数据组织方式,实现了离线和近实时处理系统的数据输出格式的管理的统一。
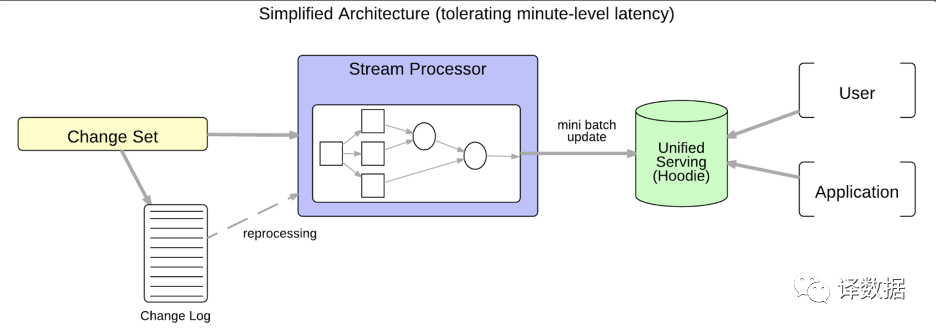
KAPPA架构可以通过实时处理流程,数据更新到Hudi data format。时间处理颗粒度较小产生的碎片化文件,DeltaLake/Hudi/Iceberg都提供了丰富的能力来实现异步的compaction,使得数据在更长时间跨度下,仍然支持查询引擎(OLAP)的高效访问。另外,这些新的数据格式,都是以列式数据存储Parquet作为基础格式,并支持到Spark/Flink/Presto等数据处理平台的集成。Lakehouse是同时具备DataLake的低廉存储介质和Data Warehouse的ACID/Data Version/Cache/Index等功能的一种全新的数据管理方案。由于开源系统,都是以library提供,在生产环境里更容易得到普及。
总结:流批融合是趋势,但不是目的。近些年技术演进的思路,也在证明,实时数据处理和离线数据处理,用同样的处理框架和统一的数据存储方案,可以大幅度地降低开发和维护成本,提升服务能力。但是,这些新兴技术也需要逐渐得到技术市场的认可和消化,对于,大数据从业人员,我们只需要保持积极开发的态度准备好下一轮技术升级的到来。
欢迎大家转发点赞!
