




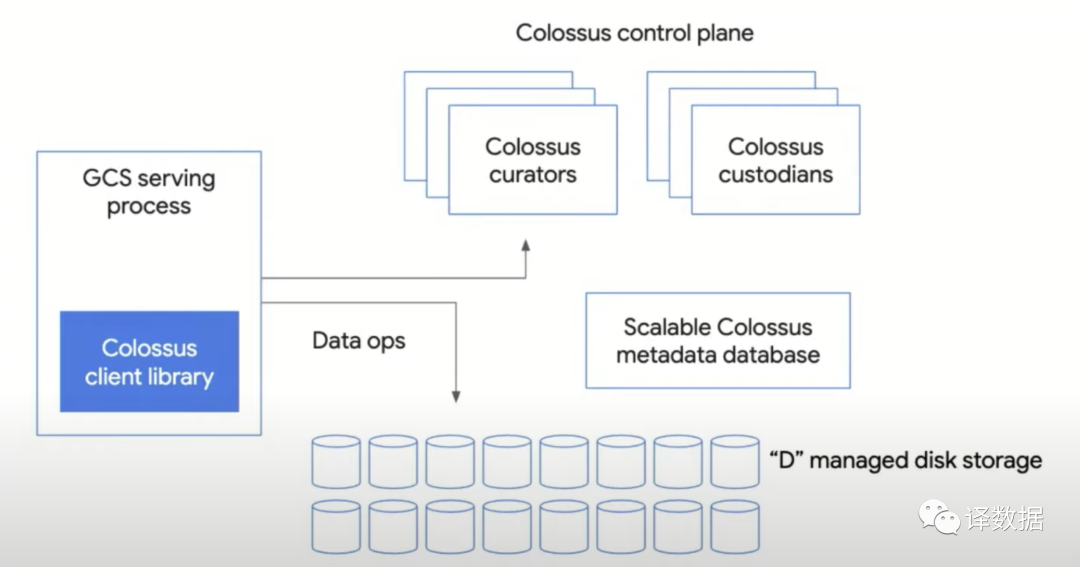
Colossus是GFS的下一代分布式文件系统,它成为了GCS(Google Cloud Storage)存储系统的基石。
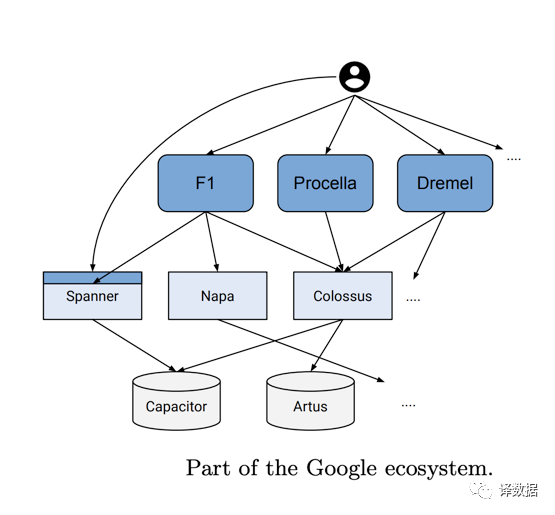
Apache Parquet 列式存储。它是Dremel的数据存储模型(Capacitor)的开源实现,已经成为数据湖/数据仓库等核心技术的默认存储方案。
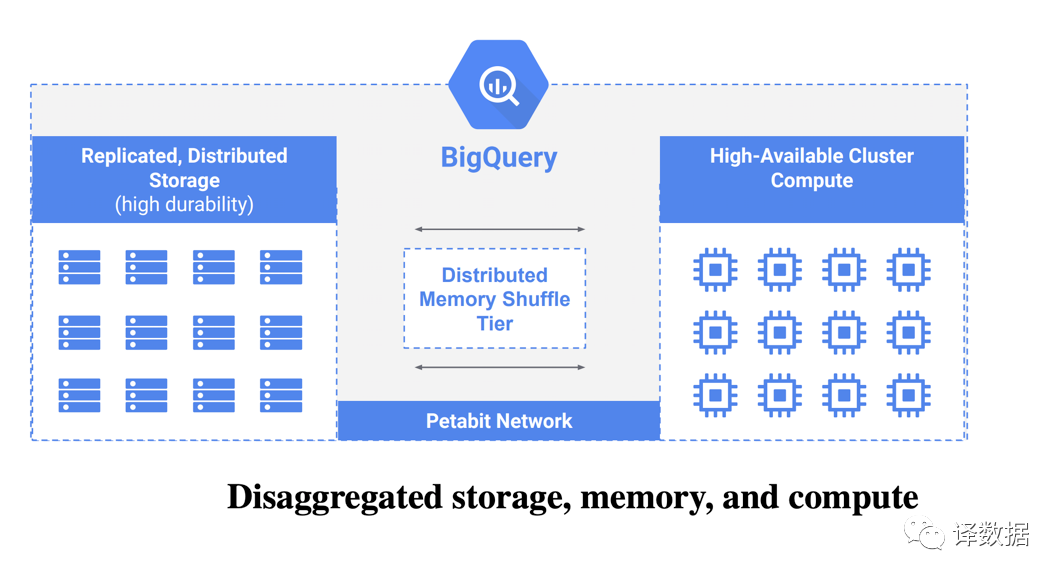
存储和计算的分离架构。无论是分布式计算架构还是OLAP架构,计算和存储分离的架构思想,在弹性/扩展性/资源利用率等众多方面都带来了比较大的提升。所以,在VLDB2020,Dremel回归了过去10年该技术在Google的演化,指出分离存储和计算的模型也迎合了过去10年云计算Pay-As-You-Use的哲学。在Google BigQuery的架构里,更是将Shuffle Tier从计算和存储架构中独立出来。最近,Spark Remote Shuffle Service的快速演化,也在推动这种面向Cloud更友好的架构思想潮流。
Procella是针对Youtube业务线,面向数据处理和分析的统一服务。随着数据需求的演化,会出现多种数据查询服务。它们的存储格式、数据管理模型、数据更新接口、查询引擎接口往往会针对不同需求有深度定制化的能力。现实世界是,一份数据,在不同系统里有一种特殊的存在和服务形式,这导致了维护一致性和成本的负担。那么,针对报表、绘图、集成的统计分析、监控和即时分析等场景,有没有一个统计的解决方案呢?
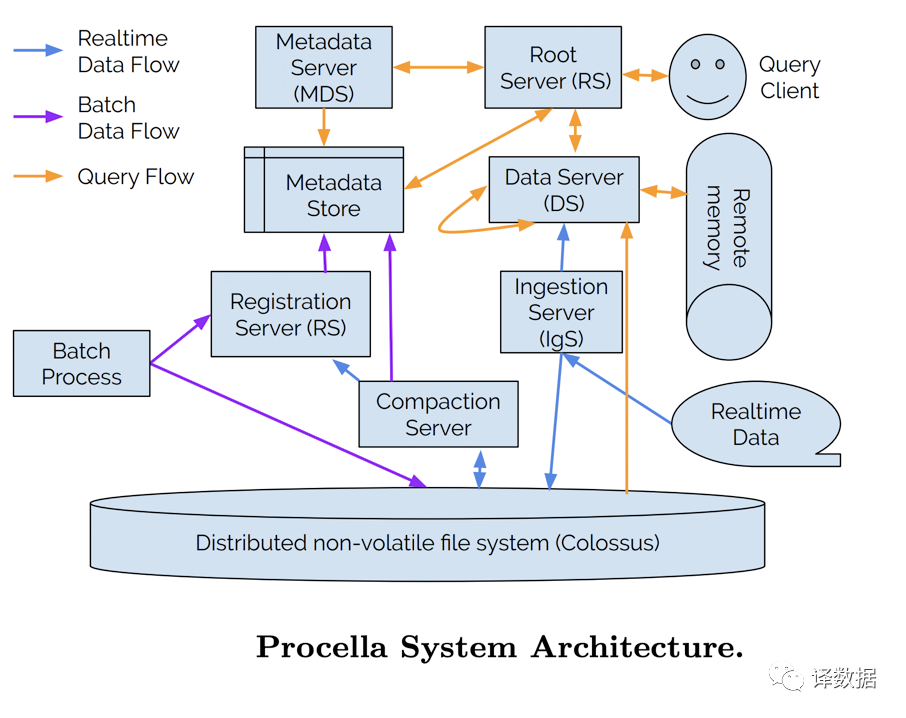
Procella在计算和存储分层的整体框架的基础上,提出了实时数据增量导入,以及本地缓存系统,缓存列式存储的metadata/Index/raw data。为了进一步降低跨层访问Colossus的开销,充分利用缓存,它还在调度任务时,引入了类似于Data Locality的affinity调度,也就是提供一套降低直接访问远程存储的任务分配和调度方案。
它还优化Dremel的列式存储方案(Capacitor),在支持数据扫描的基础上,提出了一种面向点查询和范围查询优化的列式存储格式Artus。为了提供更好的查询谓词下推的功能,Procella在数据导入过程中,会生成更多的元数据信息和索引信息,这些信息会和数据信息一起使用更加灵活高效的编码方案,例如,dictionary and indexer types, run-length, delta 等。
Procella的架构和设计的影响:
开源系统Cortex/Druid等一大批实时数据OLAP系统,在一定程度上,架构设计非常接近。它们的出现直接影响了我们管理数据更新和查询的方式。
数据缓存是面向云平台存储的OLAP架构优化的关键。如何结合查询引擎做更高效的查询优化,如何高效地利用缓存等问题在工业界还面临较大的挑战。
编码技术在查询引擎优化的运用。Bloom Filter,Roaring Bitmap,Data Sketch等,给我们优化带来新的思路。
对于Google分布式系统的回顾,F1/Mesa/Spanner/Borg等系统的特点和它的指导意义也会在后面的文章里给大家解读。
请关注译数据公众号,会尽可能为大家推送更高质量的数据系统架构的思考。

(本文所有架构图均来自于Google发布的Paper里的截图)
