




更多精彩内容请访问小程序:
51.哪些机器学习算法不需要做归一化处理?
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、XGBoost、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化。
52.说说梯度下降法。
@LeftNotEasy
机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
53.梯度下降法找到的一定是下降最快的方向么?
梯度下降法并不是下降最快的方向,它只是目标函数在当前的点的切平面(当然高维问题不能叫平面)上下降最快的方向。在Practical Implementation中,牛顿方向(考虑海森矩阵)才一般被认为是下降最快的方向,可以达到Superlinear的收敛速度。梯度下降类的算法的收敛速度一般是Linear甚至Sublinear的(在某些带复杂约束的问题)。
知识点链接:一文清晰讲解机器学习中梯度下降算法(包括其变式算法)
54.牛顿法和梯度下降法有什么不同?
@wtq1993
知识点链接:机器学习中常见的最优化算法
55.什么是拟牛顿法(Quasi-Newton Methods)?
@wtq1993
机器学习中常见的最优化算法
56.请说说随机梯度下降法的问题和挑战?



57.说说共轭梯度法?
@wtq1993
机器学习中常见的最优化算法
58.对所有优化问题来说, 有没有可能找到比現在已知算法更好的算法?
答案链接
59、什么最小二乘法?
我们口头中经常说:一般来说,平均来说。如平均来说,不吸烟的健康优于吸烟者,之所以要加“平均”二字,是因为凡事皆有例外,总存在某个特别的人他吸烟但由于经常锻炼所以他的健康状况可能会优于他身边不吸烟的朋友。而最小二乘法的一个最简单的例子便是算术平均。
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。用函数表示为:

由于算术平均是一个历经考验的方法,而以上的推理说明,算术平均是最小二乘的一个特例,所以从另一个角度说明了最小二乘方法的优良性,使我们对最小二乘法更加有信心。
最小二乘法发表之后很快得到了大家的认可接受,并迅速的在数据分析实践中被广泛使用。不过历史上又有人把最小二乘法的发明归功于高斯,这又是怎么一回事呢。高斯在1809年也发表了最小二乘法,并且声称自己已经使用这个方法多年。高斯发明了小行星定位的数学方法,并在数据分析中使用最小二乘方法进行计算,准确的预测了谷神星的位置。
对了,最小二乘法跟SVM有什么联系呢?请参见支持向量机通俗导论(理解SVM的三层境界)。
60、看你T恤上印着:人生苦短,我用Python,你可否说说Python到底是什么样的语言?你可以比较其他技术或者语言来回答你的问题。
15个重要Python面试题 测测你适不适合做Python?
61.Python是如何进行内存管理的?
2017 Python最新面试题及答案16道题
62.请写出一段Python代码实现删除一个list里面的重复元素。
1、使用set函数,set(list);
2、使用字典函数:
1
2
3
4
5
1
2
3
4
5
63.编程用sort进行排序,然后从最后一个元素开始判断。
1
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
64.Python里面如何生成随机数?
@Tom_junsong
random模块
随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
65.说说常见的损失函数。
对于给定的输入X,由f(X)给出相应的输出Y,这个输出的预测值f(X)与真实值Y可能一致也可能不一致(要知道,有时损失或误差是不可避免的),用一个损失函数来度量预测错误的程度。损失函数记为L(Y, f(X))。
常用的损失函数有以下几种(基本引用自《统计学习方法》):
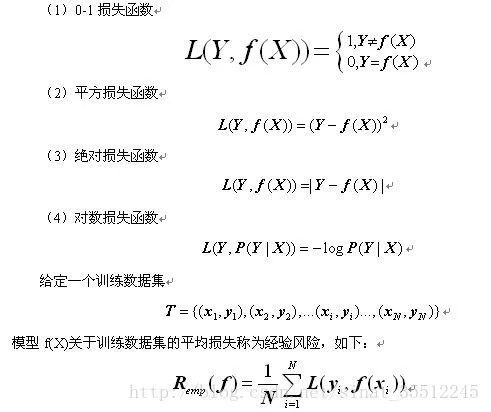

66.简单介绍下Logistics回归。
Logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
假设函数:
其中x是n维特征向量,函数g就是Logistic函数。而:的图像是:
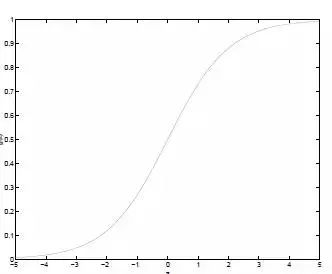
可以看到,将无穷映射到了(0,1)。而假设函数就是特征属于y=1的概率。

67.看你是搞视觉的,熟悉哪些CV框架,顺带聊聊CV最近五年的发展史如何?
68.深度学习在视觉领域有何前沿进展?
@元峰
本题解析来源:深度学习在计算机视觉领域的前沿进展
69.HashMap与HashTable区别?
HashMap与Hashtable的区别
70.在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是( )
A、将负样本重复10次,生成10w样本量,打乱顺序参与分类
B、直接进行分类,可以最大限度利用数据
C、从10w正样本中随机抽取1w参与分类
D、将负样本每个权重设置为10,正样本权重为1,参与训练过程
@管博士:准确的说,其实选项中的这些方法各有优缺点,需要具体问题具体分析,有篇文章对各种方法的优缺点进行了分析,讲的不错 感兴趣的同学可以参考一下:
How to handle Imbalanced Classification Problems in machine learning?
71.深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假90设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m <n <p <q,以下计算顺序效率最高的是(A)
A.(AB)C
B.AC(B)
C.A(BC)
D.所以效率都相同
正确答案:A
@BlackEyes_SGC:m*n*p <m*n*q,m*p*q < n*p*q, 所以 (AB)C 最小
72.Nave Bayes是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是:( C )
A.各类别的先验概率P(C)是相等的
B.以0为均值,sqr(2)/2为标准差的正态分布
C.特征变量X的各个维度是类别条件独立随机变量
D.P(X|C)是高斯分布
正确答案:C
@BlackEyes_SGC:朴素贝叶斯的条件就是每个变量相互独立。
73.关于支持向量机SVM,下列说法错误的是(C)
A.L2正则项,作用是最大化分类间隔,使得分类器拥有更强的泛化能力
B.Hinge 损失函数,作用是最小化经验分类错误
C.分类间隔为,||w||代表向量的模
D.当参数C越小时,分类间隔越大,分类错误越多,趋于欠学习
正确答案:C
@BlackEyes_SGC:
A正确。考虑加入正则化项的原因:想象一个完美的数据集,y>1是正类,y<-1是负类,决策面y=0,加入一个y=-30的正类噪声样本,那么决策面将会变“歪”很多,分类间隔变小,泛化能力减小。加入正则项之后,对噪声样本的容错能力增强,前面提到的例子里面,决策面就会没那么“歪”了,使得分类间隔变大,提高了泛化能力。
B正确。
C错误。间隔应该是才对,后半句应该没错,向量的模通常指的就是其二范数。
D正确。考虑软间隔的时候,C对优化问题的影响就在于把a的范围从[0,+inf]限制到了[0,C]。C越小,那么a就会越小,目标函数拉格朗日函数导数为0可以求出,a变小使得w变小,因此间隔变大
74.在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计( D )
A.EM算法
B.维特比算法
C.前向后向算法
D.极大似然估计
正确答案:D
@BlackEyes_SGC:
EM算法:只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法:用动态规划解决HMM的预测问题,不是参数估计
前向后向算法:用来算概率
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数
注意的是在给定观测序列和对应的状态序列估计模型参数,可以利用极大似然发估计。如果给定观测序列,没有对应的状态序列,才用EM,将状态序列看不不可测的隐数据。
75.假定某同学使用Naive Bayesian(NB)分类模型时,不小心将训练数据的两个维度搞重复了,那么关于NB的说法中正确的是:(BD)
A.这个被重复的特征在模型中的决定作用会被加强
B.模型效果相比无重复特征的情况下精确度会降低
C.如果所有特征都被重复一遍,得到的模型预测结果相对于不重复的情况下的模型预测结果一样。
D.当两列特征高度相关时,无法用两列特征相同时所得到的结论来分析问题
E.NB可以用来做最小二乘回归
F.以上说法都不正确
正确答案:BD
@BlackEyes_SGC:NB的核心在于它假设向量的所有分量之间是独立的。在贝叶斯理论系统中,都有一个重要的条件独立性假设:假设所有特征之间相互独立,这样才能将联合概率拆分。
76.以下哪些方法不可以直接来对文本分类?(A)
A、Kmeans
B、决策树
C、支持向量机
D、KNN
正确答案: A分类不同于聚类。
@BlackEyes_SGC:A:Kmeans是聚类方法,典型的无监督学习方法。分类是监督学习方法,BCD都是常见的分类方法。
77.已知一组数据的协方差矩阵P,下面关于主分量说法错误的是( C )
A、主分量分析的最佳准则是对一组数据进行按一组正交基分解, 在只取相同数量分量的条件下,以均方误差计算截尾误差最小
B、在经主分量分解后,协方差矩阵成为对角矩阵
C、主分量分析就是K-L变换
D、主分量是通过求协方差矩阵的特征值得到
正确答案: C
@BlackEyes_SGC:K-L变换与PCA变换是不同的概念,PCA的变换矩阵是协方差矩阵,K-L变换的变换矩阵可以有很多种(二阶矩阵、协方差矩阵、总类内离散度矩阵等等)。当K-L变换矩阵为协方差矩阵时,等同于PCA。
78.Kmeans的复杂度?
时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数。
具体参考:机器学习之深入理解K-means、与KNN算法区别及其代码实现
79.关于Logit 回归和SVM 不正确的是(A)
A. Logit回归本质上是一种根据样本对权值进行极大似然估计的方法,而后验概率正比于先验概率和似然函数的乘积。logit仅仅是最大化似然函数,并没有最大化后验概率,更谈不上最小化后验概率。A错误
B. Logit回归的输出就是样本属于正类别的几率,可以计算出概率,正确
C. SVM的目标是找到使得训练数据尽可能分开且分类间隔最大的超平面,应该属于结构风险最小化。
D. SVM可以通过正则化系数控制模型的复杂度,避免过拟合。
@BlackEyes_SGC:Logit回归目标函数是最小化后验概率,Logit回归可以用于预测事件发生概率的大小,SVM目标是结构风险最小化,SVM可以有效避免模型过拟合。
80.输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为:()
正确答案:97
@BlackEyes_SGC:计算尺寸不被整除只在GoogLeNet中遇到过。卷积向下取整,池化向上取整。
本题 (200-5+2*1)/2+1 为99.5,取99
(99-3)/1+1 为97
(97-3+2*1)/1+1 为97
研究过网络的话看到stride为1的时候,当kernel为 3 padding为1或者kernel为5 padding为2 一看就是卷积前后尺寸不变。计算GoogLeNet全过程的尺寸也一样。
81.影响聚类算法结果的主要因素有(BCD )
A.已知类别的样本质量;
B.分类准则;
C.特征选取;
D.模式相似性测度
82.模式识别中,马式距离较之于欧式距离的优点是(CD)
A. 平移不变性;
B. 旋转不变性;
C. 尺度不变性;
D. 考虑了模式的分布
83.影响基本K-均值算法的主要因素有(ABD)
A. 样本输入顺序;
B. 模式相似性测度;
C. 聚类准则;
D. 初始类中心的选取
84.在统计模式分类问题中,当先验概率未知时,可以使用(BD)
A. 最小损失准则;
B. 最小最大损失准则;
C. 最小误判概率准则;
D. N-P判决
85.如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有(BC)
A. 已知类别样本质量;
B. 分类准则;
C. 特征选取;
D. 量纲
86.欧式距离具有(AB );马式距离具有(ABCD )。
A. 平移不变性;
B. 旋转不变性;
C. 尺度缩放不变性;
D. 不受量纲影响的特性
87.你有哪些Deep Learning(RNN,CNN)调参的经验?
答案解析,来自知乎
88.简单说说RNN的原理。
我们升学到高三准备高考时,此时的知识是由高二及高二之前所学的知识加上高三所学的知识合成得来,即我们的知识是由前序铺垫,是有记忆的,好比当电影字幕上出现:“我是”时,你会很自然的联想到:“我是中国人”。
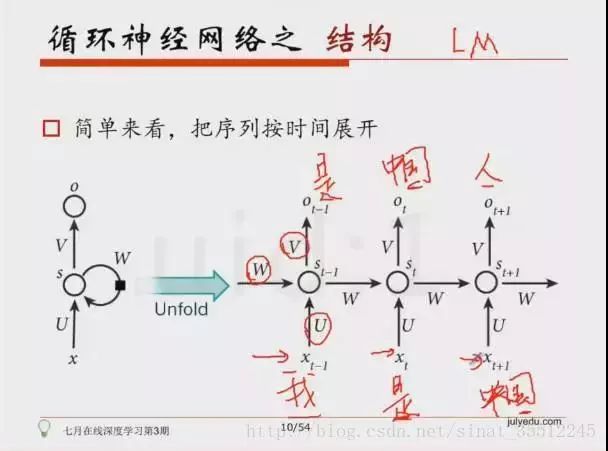
89.什么是RNN?
@一只鸟的天空,本题解析来源:
循环神经网络(RNN, Recurrent Neural Networks)介绍

您的关注和转发,是我们不断努力的原动力!
