




MapReduce是hadoop的三驾马车之一,是一个批处理计算框架。
以下内容中,为方便描述 MapReduce有时简写为MR。
理论基础:源自于Google发表于2014年12月的MapReduce论文,可以把Hadoop MapReduce是Goole MapReduce的克隆版。
整体思路:局部性原理将整个问题分而治之。
MR之前,数据分布在各个节点;MR时每个节点就近读取本地存储的数据处理(MAP)-处理后的数据进行合并(combine)-排序(shuffle & sort)-分发到各个reduce节点。

MapReduce特性:
易于编程
(1)用户主要考虑如何使用MR模型,实现几个hook函数即可实现一个分布式程序。
(2)由mapTask 和 reduceTask组成。
(3)分发、合并、同步、监测均由执行框架负责,用户无需关心。
良好的扩展性(HDFS的分布式存储特点)
高容错性(HDFS数据副本策略)
适合海量数据的离线处理(就近读取,避免大量数据传输,提高处理效率)
任何编程语言和框架都有适合和不适合的场景,
MapReduce亦是如此:
| 适合的场景 |
(1)聚类算法 (2)分类算法 (3)推荐算法 ... ... |
| 不适合的场景 |
|

MapReduce将作业的整个运行过程分为Map阶段和Reduce阶段
下面表格中,红色字体部分属于可自定义的范围。
| Map阶段 | 由一定数量的Map Task组成(并行执行) •输入数据格式解析:InputFormat •输入数据处理:Mapper •数据分组:Partitioner |
| Reduce阶段 | 由一定数量的Reduce Task组成 •数据远程拷贝,从Partitioner分区数据中拷贝 •数据按照key排序(相同KEY的值封装成集合) •数据处理:Reducer (对封装后的每组值进行处理) •数据输出格式:OutputFormat (写出到外部存储,如HDFS、HBase) |
扩展内容:
1、InputFormat
InputFormat从HDFS获取文件分片信息,分片信息格式化后解析成KV的格式按行传给Mapper进行处理。(key是行在文件中的偏移量,value是行内容。)
默认实现是TextInputFormat
Split与Block Block:HDFS中最小数据存储单位,默认128MB Split:MapReduce中最小的计算单元,默认与Block一 一对应 (可调整) |
从HDFS获取文件,进行文件分片(InputSplit)时存在跨行问题: 遇到一行被截断的情况(一行数据分别存在于两个分片中时),处理完前边的行去下一个分片读取剩余被截断的字符,当处理下一个分片的时候需要自动跳过属于前一个被截断行的字符。 LineRecordReader读取过从而避免漏读或重复读取开头一行呢? LineRecordReader使用了一个简单而巧妙的方法:既然无法断定每一个split开始的一行是独立的一行还是被切断的一行的一部分,那就跳过每个split的开始一行(除第一个split外),从第二行开始读取,然后在到达split的结尾端时总是再多读一行,这样数据既能接续起来又避开了断行带来的麻烦。 |
2、Mapper
Mapper是用户自定义的业务逻辑处理程序(分组、过滤等操作),处理完后每组数据通过Partitioner分发给不同的reduce处理(KEY和reduce的数量进行取余,分发给不同reduce)。
3、Partitioner分区
Partitioner决定了Map Task输出的每条数据交给哪个Reduce Task处理。
默认实现:HashPartitioner
计算逻辑:Hash(key) mod R (R是Reduce Task数目),计算结果等于Reduce Task号。
说明:允许自定义分区(例如按年龄段分区等,根据业务逻辑进行自定义)

Map方法中可获取各行数据,根据业务进行处理。按KV格式 写出供reduce使用;Reduce方法可获取合并KEY后的KV数据,根据业务进行处理,按KV格式写出。

(1)作业提交后,InputFormat按照策略将输入数据切分成若干个Split,各Map任务节点上根据分配的 Split元信息获取相应数据,将其解析成key/value对,通过Mapper任务后处理为新的key2/value2对。
(2)新的 key2/value2对先进行排序,然后由 Partitioner将有符合关系的数据分到同一个Reducer上进行处理,中间数据存入本地磁盘。各Reduce任务节点根据己有的 Map节点远程获取数据(只获取属于该 Reduce 的数据,该过程称为 Shuffle);
(3)对数据进行排序,并进行分组(将相同 key 的数据分为 一组),迭代KV对,并由Reducer合并处理为新的key3/value3对,新的key3/value3对由OutputFormat保存到输出文件中。
1、shuffle过程(MR过程中关键步骤)
shuffle过程实现相同 key数据的整合与排序,是整个MR过程的关键步骤。
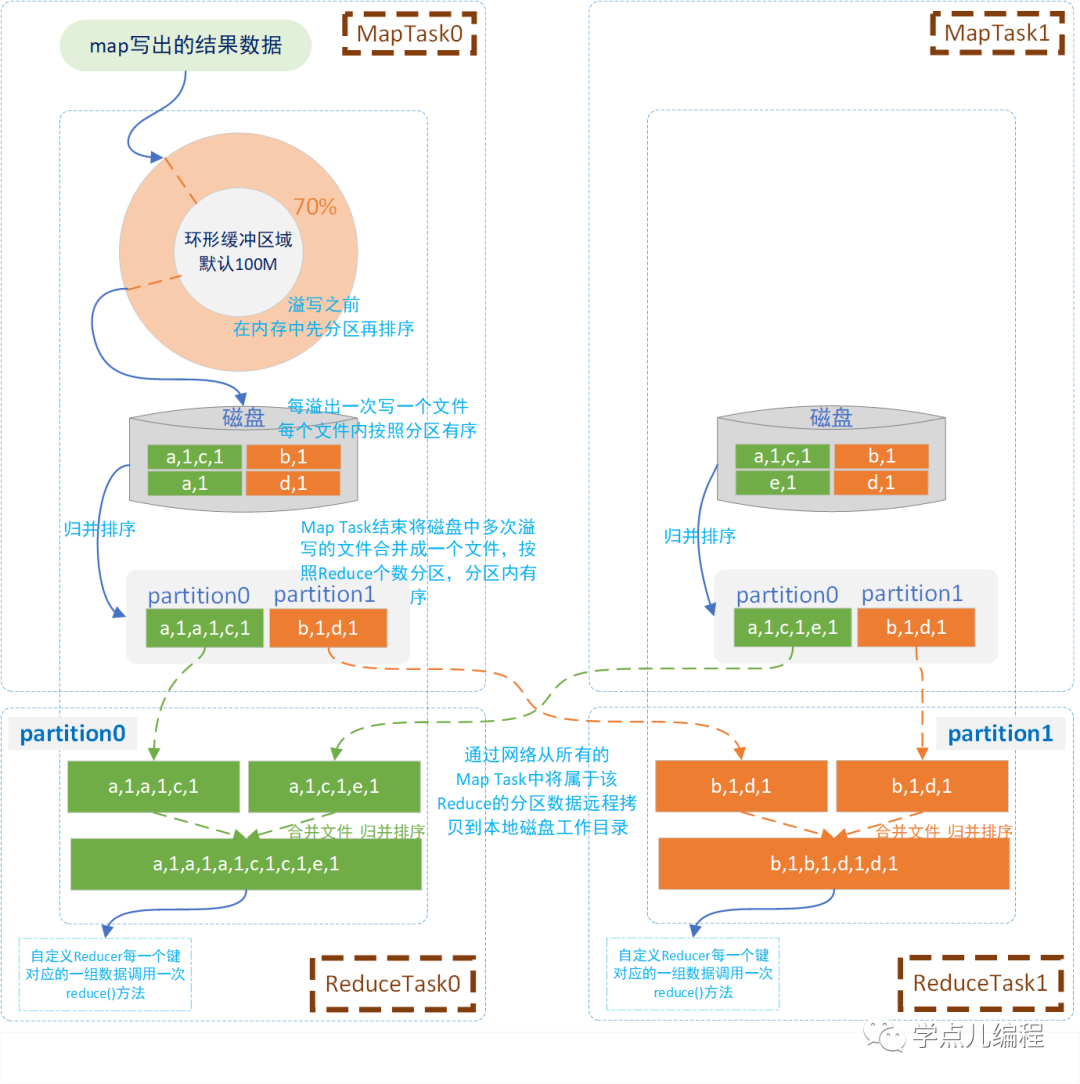
1、Map Task执行完成后,Map结果会写出到环形缓冲区。
缓冲区是一个内存数组,默认大小是100M (可调整),当缓冲区中数据达到 80% 时会溢写,溢出数据写到磁盘中(map边写入,缓冲区边溢出)。
写的时候,把数据写入到不同的进行分区(hash值%reduce个数 对应分区号(即:reduce任务号)),同时对分区内的数据按KEY进行排序,然后写入磁盘。
2、随着Map Task的运行,溢出到磁盘上的小文件越来越多,相同partition下的小文件会进行归并排序。
3、Reduce Task通过网络远程拷贝Map Task的结果文件中属于它的分区数据,同时会合并所有拷贝过来的数据文件并排序,并将相同KEY的数据分为一组,每个KEY对应一组值,各KEY之间有序。
4、每个KEY对应的一组数据会调用一次reduce方法。
Reduce Task通过网络远程拷贝Map Task的结果文件中属于它的分区数据: 该过程中会将磁盘中多个文件进行归并排序时,不同文件同一分区的数据进行合并,放到同一个分区中,然后合并成一个大文件。由于网络延迟、传输效率等因素,执行过程中M和R处理大量数据有很大压力,所以shuffle的优化是MapReduce过程中比较关键的点。任务执行的慢可关注 shuffle的过程,shuffle的优化可参考下面的combiner方式。 |
2、Combiner优化
如果数据量比较多,可采用combiner优化小文件的数量,提高性能。
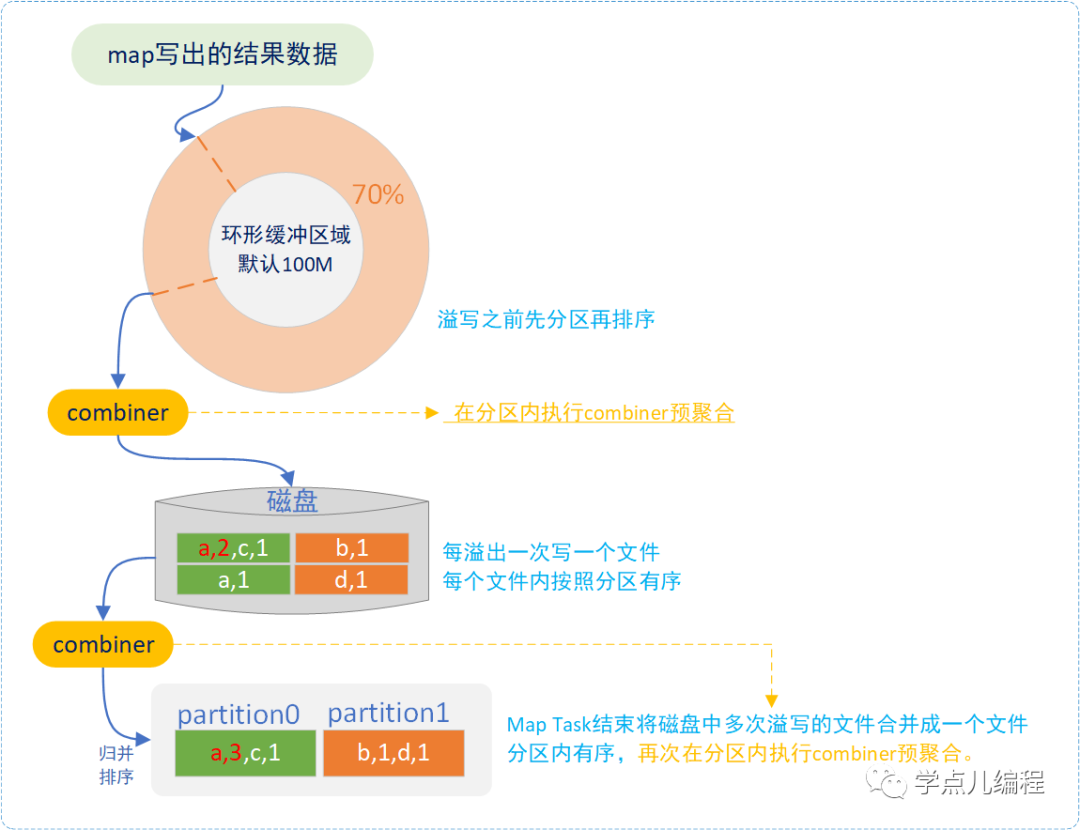
Map Task在两个阶段使用combiner方法,来提高处理性能。
(1)环形缓冲区向磁盘写文件之前调用combiner,减少文件数量。
原来:溢写之前会先分区再排序。
现在:combiner会在分区内执行一次聚合,这样写的磁盘文件就小了。此时是各个小文件内的聚合。
(2)MAP阶段在合并本地多个文件后 写入一个大文件之前调用 (合并重复数据,减小大文件大小)
mapTask执行完后会将磁盘中多次溢写的文件合并成一个大文件,并且分区内有序,此时在分区内执行combiner会多个文件的聚合(一个文件有多个分区,两个文件中的相同分区会合并并排序,数值合并)。
combiner的好处:合并后的文件数据量少了、小了,对应的磁盘IO、网络传输也就少了。 使用场景:针对结果可叠加的场景(例如:sum求和),averaget平均数不合适(局部数据的平均数,再求平均数 可能就不准确了) 使用方法(一行代码): job.setCombinerClass(WordCountReducer.class) 本质是:提前执行两次reduce,设置为reduce.class即可。 |

MapReduce的Java编程接口有新旧两套API:
旧API:所在java包:org.apache.hadoop.mapred
新API:所在java包:org.apache.hadoop.mapreduce
两种接口只是调用形式不同(执行引擎相同),新API具有更好的扩展性。
下面以经典的WordCount为例,来分析MapReduce过程。
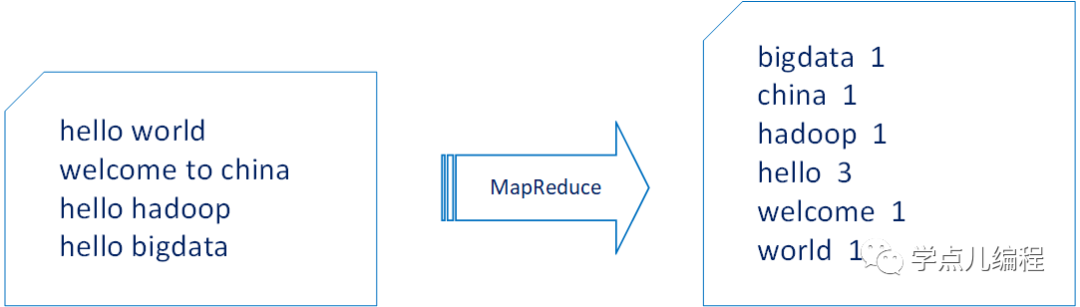
1、WordCount需求描述
有TB级数据量的文件,文件中存储着大量的单词,统计这些文件中每个单词出现的次数。如下图所示:
2、MapReduce编程思路
Map阶段 (1)TextInputFormat将文本数据解析成key-value对。 其中:Key是偏移量,value是行内容。 (2)针对每行数据应用map方法,按照分隔符拆分 (3)Map阶段输出单词作为key,1作为value Map阶段编程实现: 通过继承org.apache.hadoop.mapreduce.Mapper类,编写自己的Mapper实现类,重写map方法,实现具体处理逻辑。
|
Reduce阶段 (1)远程把Map阶段的输出结果数据拷贝到Reducer中。 (2)对拷贝过来的数据整理排序,将相同key的数据整合成一个key对应一组value形式的数据集。 (3)每个KEY对应的数据集会调用一次reduce方法,对数据集中的value求和。
Reduce阶段编程实现: 通过继承org.apache.hadoop.mapreduce.Reducer类,编写自己的Reducer 实现类,重写reduce方法,实现具体的处理逻辑。 |
任务提交: 写完Map和Reduce的处理逻辑后,设置好Job的属性(jar包路径、主类路径、输入路径、输出路径等)后打包并提交jar包。 有个注意点:输出路径在提交之前要保证路径不存在,MapReduce运行完会自动创建,如果提前任务时已存在输出路径会报文件夹存在的错误。 |


该示例的相关代码,本篇就先不具体介绍了。
后面会有专门的hadoop部署、hadoop实战相关章节。
如果想提前看该示例的代码,可通过以下链接下载 链接:https://pan.baidu.com/s/1Jfv4nmy4anShHGxhjHfXww 提取码:请关注公众号“学点儿编程”,回复“百度网盘密码”获取。 |

1. 用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
2.Mapper中的业务逻辑写在map()方法中,输入数据是KV对的形式,输出数据也是KV对的形式。map()方法对每一个<K,V>调用一次
3.Reducer的业务逻辑写在reduce()方法中,输入数据类型对应Mapper的输出数据类型(是KV对),Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法。
4.用户自定义的Mapper和Reducer都要继承各自的父类,整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象


