




从上一篇文章 ZooKeeper与CAP是什么关系?适用于哪些场景?
我们知道,ZooKeeper是一个分布式服务框架,是Apache Hadoop 的一个子项目,主要用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、配置管理、集群管理、分布式锁、发布/订阅等。
从技术本质上来说,ZooKeeper的作用主要体现在两个方面:
文件系统
监听通知机制
怎么理解这句话的意思呢?带着这个问题,下面咱们开始讨论ZooKeeper的体系架构。

1、ZooKeeper的角色划分
一个ZooKeeper集群是由多个服务器组成(分布式啊,肯定得多台啊!),每个节点都有各自的角色,不同角色的节点在集群中负责不同的任务,作为一个整体对外提供稳定、可靠的服务。
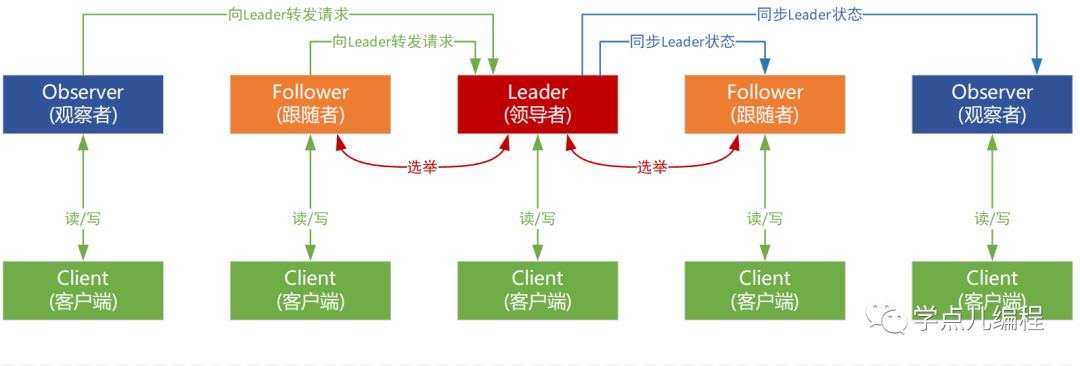
上图体现了ZooKeeper集群中几种角色间的关系,相关描述如下:
领导者 Leader | 处理事务请求,更新系统状态。 负责进行投票的发起和决议。 | |
学习者 Leaner | 跟随者 Follower | 处理客户端非事务请求并向客户端返回结果,将写事务请求转发给Leader; 参与选举投票,并同步Leader的状态, |
观察者 Observer | 接收客户端读请求,将客户端写请求转发给Leader; 不参与投票过程,只同步Leader的状态; 目的是为了扩展系统,提高读取速度。 | |
客户端 Client | 请求发起方 |
既然有了Follower,为什么还要有Observer呢? 虽然通过Client直接连接到ZooKeeper集群的性能已经很好了,但该架构在面对超大规模的Client时,需添加ZooKeeper集群的Server数量。 随着Server的添加,ZooKeeper集群的写性能必定下降(ZooKeeper的ZNode变更是要过半数投票通过,随着机器的添加,因为网络消耗等原因必定导致投票成本添加,从而导致写性能的下降。) Observer是一种新型的ZooKeeper节点,提供ZooKeeper的可扩展性,同时Observer不參与投票,仅仅是简单的接收投票结果。因此我们添加再多的Observer也不会影响集群的写性能;另一方面,Observer不參与投票,所以他们不属于ZooKeeper集群的关键部位,即使他们Failed,或者从集群中断开,也不会影响集群的可用性。 |

2、ZooKeeper选举
ZooKeeper的选举运作可能出现在两个场景:
| 集群初始化 | 部署ZooKeeper集群过程中,各个节点陆续加入集群,各个节点为争leader头衔进行投票选举。 |
| 集群运行中 | ZooKeeper集群运行过程中,leader节点可能由于某个原因挂掉了,节点之间重新投票选举。 说明:当有非leader节点宕机或新加入,不会影响当前的leader,也就不会触发重新选举。 |
讨论选举过程,必须得先了解ZooKeeper集群中每个节点都有的两个属性:
这两个属性也可称为选举指标/规矩,无规矩不成方圆!

2.1、集群初始化阶段的选举

第一步:每个节点都会“我选我”,把投票投给自己(话说,这服务器脸皮也挺厚的 )
)
每张投票中包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,此时Server1的投票为(1, 0),Server2的投票为(2, 0),
第二步:处理投票
集群的每个节点收到投票后,会判断该投票的有效性(如检查是否是本轮投票、是否来自LOOKING状态的服务器)。
然后,针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下:
优先检查ZXID。ZXID比较大的服务器优先作为Leader。
如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1,它的投票是(1, 0),接收Server2的投票为(2, 0),先比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票。
对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
第三步:统计投票
每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,
对于Server1、Server2,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时集群便认为已经选出了Leader。
第四步:改变服务器状态
一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
2.2、集群运行过程中的选举
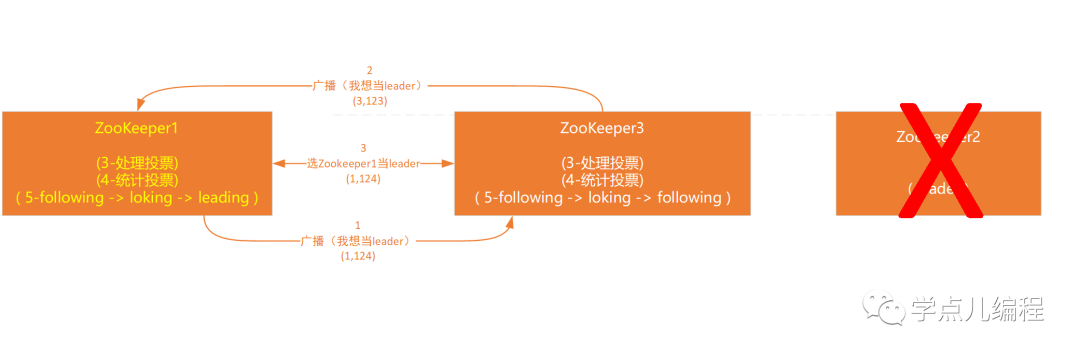
Zookeeper集群运行期间,一旦Leader服务器宕机,整个集群会暂停对外服务,进入新一轮Leader选举(过程和集群初始化阶段基本一致)。
如上图:原集群有三台服务器,当前Leader(Zookeeper2)某种原因宕机了,此时便开始Leader选举:
第一步:变更状态
Leader宕机后,剩下的非Observer服务器将状态变更为LOOKING,然后开始投票。
第二步:投票
参与投票的节点又是“我选我”得开始投票(myid,ZXID),和集群初始化阶段不同的是,集群运行了一段时间,每个服务器上的ZXID可能不同。
后续步骤:
后续的处理投票、统计投票、改变状态 与 集群初始化阶段的选举过程相同。此处不再描述。

3、数据模型Znode
Znode是Zookeeper特有的数据模型,Znode的特点支撑Zookeeper的特性。
3.1、Znode的特点
 | 1、视图结构类似Linux文件系统(根由“/”开始),但没有目录和文件的概念。 2、Znode是Zookeeper中数据的最小单元,可以保存数据。通过挂载子节点构成一个树状的层次化命名空间。 |
3.2、Znode节点分类
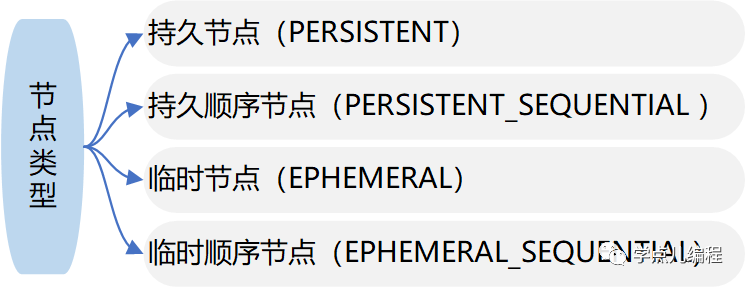
临时节点:客户端和服务器端断开连接后,节点自动删除
持久节点:客户端和服务器端断开连接后,节点不会删除
顺序节点:Zookeeper给该节点名称进行顺序编号(在分布式系统中被用于全局排序)。是一个单调递增的计数器,由父亲节点维护。
每个Znode节点都有版本信息,有多种版本属性:
dataVersion:当前数据节点数据内容的版本号
cVersion:当前数据节点子节点的版本号
aVersion:当前数据节点ACL权限变更版本号
Zookeeper集群如何保证各节点的原子性操作:
悲观锁
乐观锁
使用version实现乐观锁机制中的“写入校验”
3.3、Znode的watch机制
Znode的watch机制,是支撑配置管理、集群管理、分布式锁、发布/订阅等特性的基础。只要数据一发生变化,就会通知相应地注册了监听的客户端,从而实现数据的及时通知。
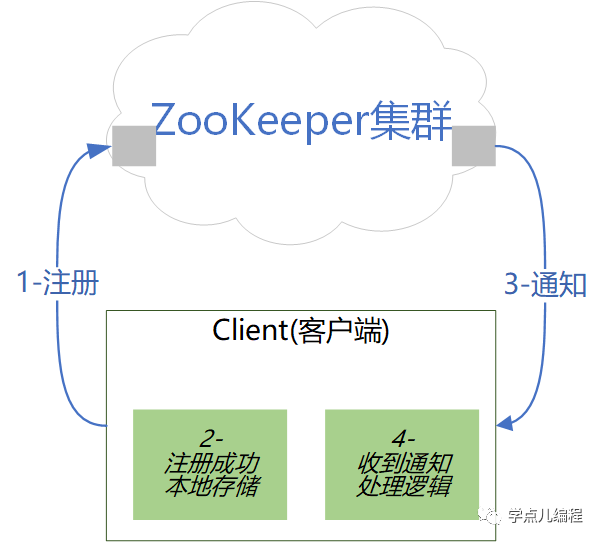 | 第1步:客户端注册Watcher到服务端; 第2步:注册成功,本地存储当前状态; 第3步:集群中所监控节点发生变化,服务端通知客户端数据变更; 第4步:客户端回调Watcher处理变更应对逻辑。 |
说明:客户端在Znode设置了Watch时,如果Znode内容发生改变,那么客户端就会获得Watch事件。例如:客户端设置getData("/znode1", true)后,如果/znode1发生改变或者删除,那么客户端就会得到一个/znode1的Watch事件。
介绍完上面的
现在应该清楚,本文开篇说的“从技术本质上来说,ZooKeeper的作用主要体现在文件系统和监听通知机制”的含义了吧。

下一篇,介绍ZooKeeper的安装部署和典型场景实战
理论知识讨论的差不多了,下面开始实操了。 敬请关注!
