




Redis是典型的key-value类型库,value有八种类型,分别是String(字符串)、List(列表)、hash(哈希结构)、set(集合)、sorted set(有序集合,也叫zset)、Bitmaps(位图)、HyperLogLog(基数统计)、GEO(地理信息定位)。
一、String(字符串)
1、简单介绍
字符串类型是Redis最基础的数据结构,字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML)),数字(整数、浮点数),甚至是二进制(图片、音频、视频)。
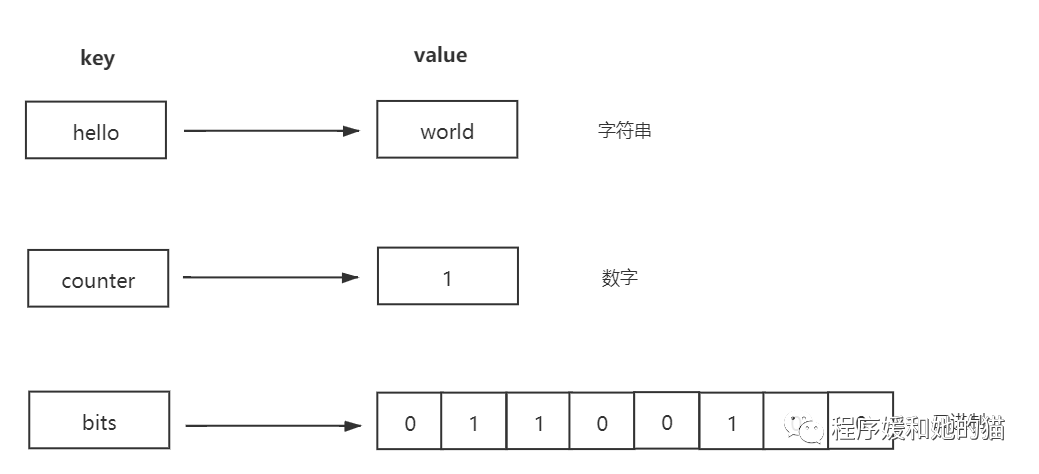 String类型
String类型
2、应用场景
(1)、缓存功能
MySQL操作硬盘,速度很慢,Redis操作内存,速度很快。所以在高并发场景下,一般会在MySQL前面加上Redis作为缓存,起到加速读写和降低MySQL库压力的作用。
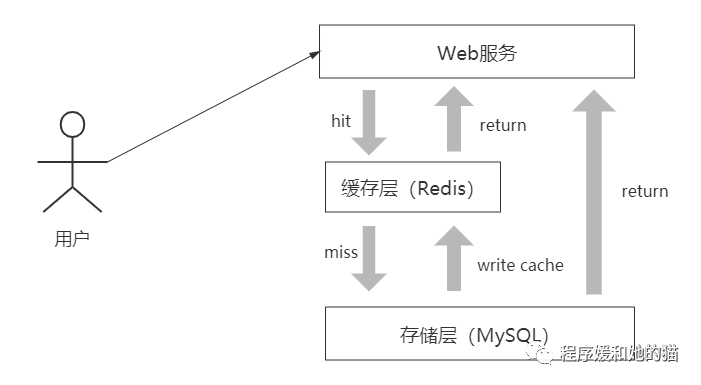 String类型用作缓存
String类型用作缓存
UserInfo getUserInfo(String userId){
String userRedisKey = "user:info" + userId;
UserInfo userInfo = redis.get(userRedisKey);
if(userInfo != null){
return userInfo;
} else {
userInfo = mysql.get(userId);
if(userInfo != null){
redis.setex(userRedisKey, 3600, userInfo);
}
}
}
Redis键的设计:
与MySQL等关系型数据库不同的是,Redis没有命令空间,而且对键名也没有强制要求(除了不能使用一些特殊字符)。但设计合理的键名,有利于防止键冲突,提高项目的可维护性。推荐使用“业务名:对象名:id:[属性]”作为键名,例如MySQL的数据库名为vs,用户表名为user,那么对应的键可以用"vs:user:1","vs:user:1:name"来表示。
(2)、计数
由String的incr自增命令,许多应用都会使用Redis作为计数的基础工具。比如点赞系统,incr key表示点赞,decr key表示取消点赞。
redis> INCR user:<userId>:like // 点赞
redis> DECR user:<userId>:like // 取消点赞
(3)、限速
限制网站或者APP在某段时间的访问次数,比如我们登录某个网站需要用手机获取验证码,但是我们发送验证码使用的是第三方系统,是要收费的,肯定不能让用户一直点,一直发短信。虽然前端JS可以做校验,但是如果有人用fiddler拦截绕过前台,那就麻烦啦,所以为了安全保证,后端还要再加一层拦截,这时候可以用redis的incr命令和expire结合起来做一个解决方案,控制1分钟内最多发送5次短信。
 手机验证码示意图
手机验证码示意图
String phoneNum = "138xxxxxxxx";
String key = "shortMsg:limit:" + phoneNum;// Redis的key
// 先判断Redis中是否有该key值
if(redis.exists(key)){
int num = redis.get(key);// 取出发送次数,Redis的value
// 如果发送次数大于等于最大次数
if (num >= 5) {
return;// 限速
}
// 若不大于,则通过,发送手机验证码并将访问次数加1
sundMsg();// 通过,发送手机验证码
redis.incr(key, 1L);
} else {
sundMsg();// 通过,发送手机验证码
redis.set(key, 1, "EX 60");// 过期时间设置为1分钟
}
(4)、分布式系统共享Session
Session作用:一般我们会在用户进行操作的时候用一个拦截器去拦截用户的请求,然后再查看服务器中的Session中有没有该用户的信息,如果有就放行,如果没有就跳转到登录界面提示登录。
一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各个服务器中,这样会造成一个问题,在做Nginx负载均衡的时候,各个用户的请求都会被负载到各自的服务器上,这就会产生很不好的用户体验。
见图1,用户第一次请求被Nginx转发到了服务器A,用户登录之后,操作请求又随机被分发到了服务器B,这时B服务器的Session中没有用户信息,又提示用户需要登录,造成了非常不友好的用户体验。
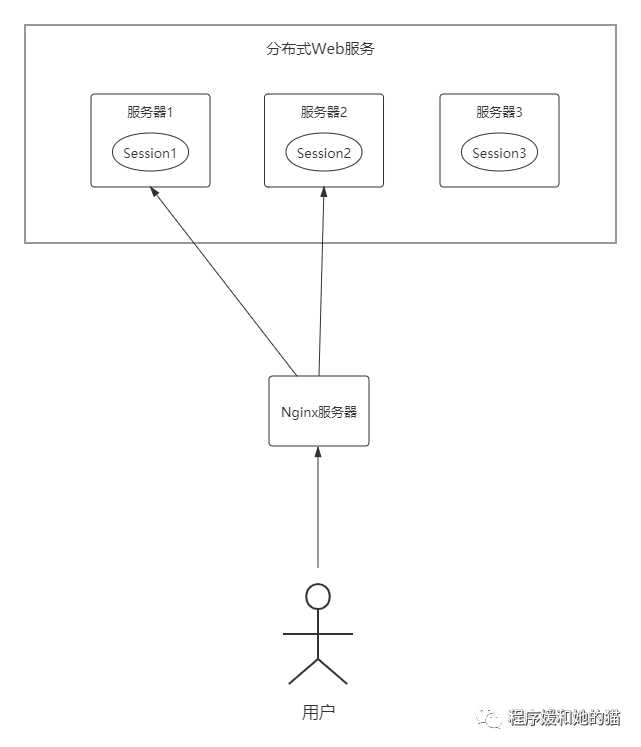 Session图1
Session图1
那应该怎么解决呢?见图2,使用Redis将用户的Session信息进行集中的管理,每次用户登录信息都从Redis中获取。
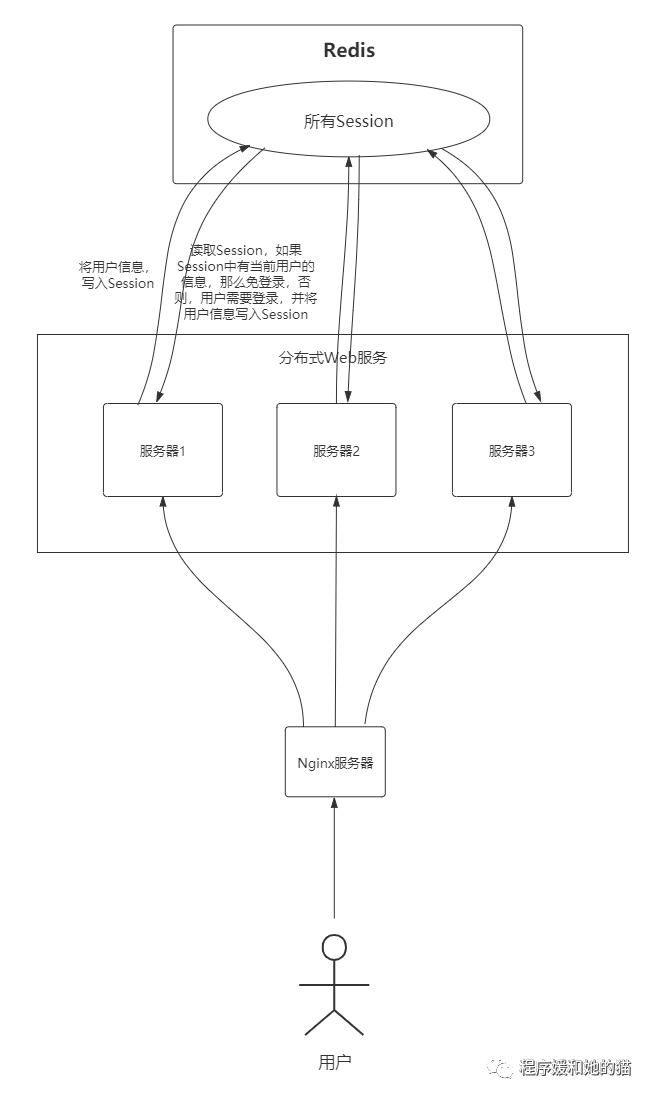 Session图2
Session图2
3、底层实现
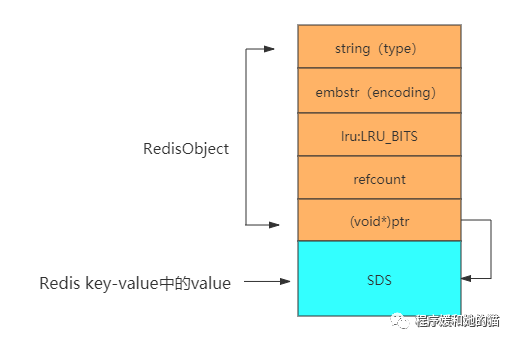
(1)、RedisObject
首先我们讲解一下Redis的RedisObject的数据结构,如下所示:
typedef struct redisObject {
// 对外的类型 string list set hash zset等 所占内存大小为4bit
unsigned type:4;
// 底层存储方式 4bit
unsigned encoding:4;
// LRU时间 24bit
unsigned lru:LRU_BITS;
// 引用计数 4byte
int refcount;
// 指向对象(Redis key-value中的value)的指针 8byte
void *ptr;
} robj;
(2)、string的底层实现对于不同的对象,Redis会使用不同的类型type来存储。对于同一种类型会有不同的存储方式encoding。对于string类型(type)的字符串,其底层编码方式(encoding)共有三种,分别为int、embstr和raw。
int:当存储的字符串中全是数字时,此时使用int方式来存储;
embstr:当存储的字符串长度小于等于39个字节时,此时使用embstr方式来存储;
raw:当存储的字符串长度大于39个字节时,此时使用raw方式来存储;
对于embstr和raw这两种encoding类型,其存储方式还不太一样。对于embstr类型,它将RedisObject对象头和SDS对象在内存中地址是连在一起的,但对于raw类型,二者在内存地址不是连续的。
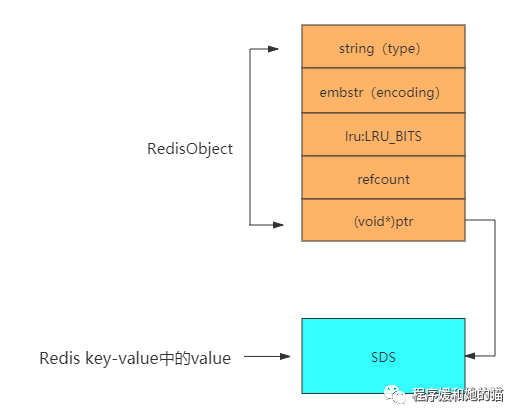
(3)、SDS我们知道Redis是用C语言写的,但是它却没有完全直接使用C的字符串(以空字符’\0’结尾的字符数组),而是自己又重新构建了一个叫简单动态字符串SDS(simple dynamic string)的抽象类型,并将SDS作为Redis的默认字符串表示。
有一点需要注意:在redis数据库中,key-value键值对凡是含有字符串值的,都是由SDS来实现的。比如:在Redis执行一个简单的set命令时,这时Redis会新建一个键值对。
127.0.0.1:6379> set hello world
此时键值对的key和value都是一个字符串,而字符串的底层实现分别是两个保存着字符串hello和world的SDS结构。
与C语言的原始字符串结构相比,SDS多了一个sdshdr的头部信息,sdshdr基本数据结构如下所示:
struct sdshdr{
// 表示buf[]数组所保存的字符串的长度
int len;
// 表示buf[]数组未使用的字节的长度
int free;
// 实际保存字符串的char类型数组
char buf[];
}
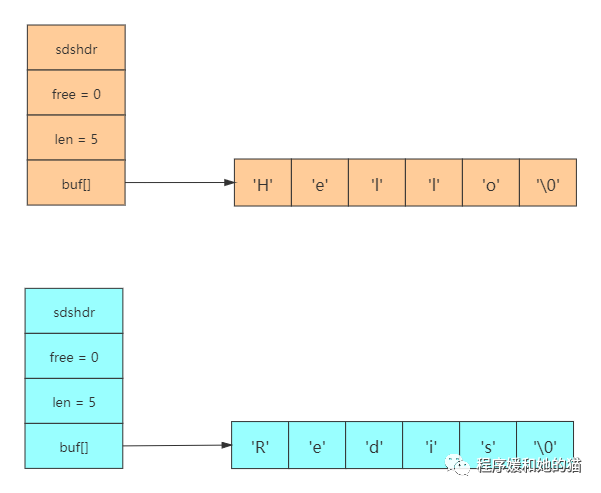
用SDS保存字符串"hello"具体图示如下: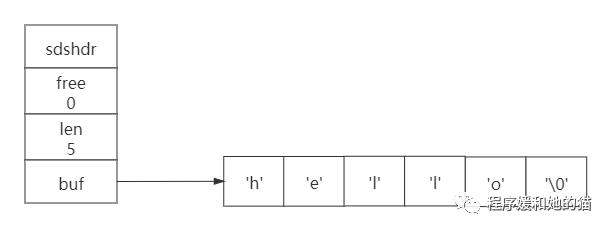
上图表示的是buf[]保存长度为5个字节的字符串,未使用的字节数free为0,但是我们发现这明明是6个字符,还有一个"\0"啊,为什么len是5呢?
这是因为SDS没有完全直接使用语言的字符串,但还是沿用了一些C语言特性的,,比如遵循C的字符串以空格符结尾的规则。这样做的目的是还可以使用一部分C字符串的函数。
(4)、为什么不用C语言的字符串,而是要使用自己定义的SDS呢,岂不是多此一举?
(a)、SDS效率更高
工作中使用redis,经常会通过STRLEN命令获取一个字符串的长度,在SDS结构中len属性记录了字符串的长度,所以我们获取一个字符串长度时直接取len的值,复杂度是O(1)。
而如果用C语言的字符串,在获取一个字符串的长度时,需要对整个字符串进行遍历,直至遍历到空格符结束(C语言中遇到空格符代表一个完整字符串结束),时间复杂度是O(N)。
在高并发场景下,如果需要频繁获取字符串的长度,使用SDS比C语言的字符串效率要高得多。
(b)、SDS可以杜绝数据溢出
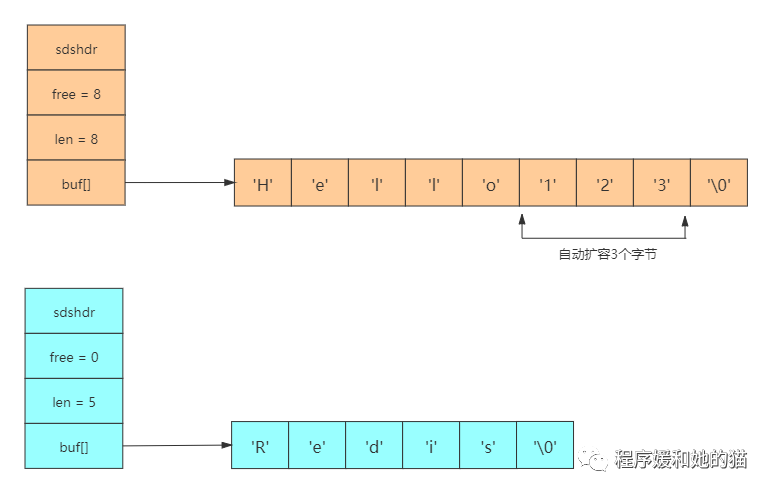
见下图,两个C语言字符串s1和s2在内存中相邻存储,s1保存了字符串"Hello",s2保存了字符串"Redis"。

此时我们想把s1由"Hello"改成"Hello123",那就会出现一个问题,之前分配给s1的内存只有5个字节,修改后的字符串需要8个字节才能放下,s1空间不够了,它只能侵占相邻字符串s2的空间,就会造成自身数据溢出导致其他字符串的内容被修改的情况,见下图。
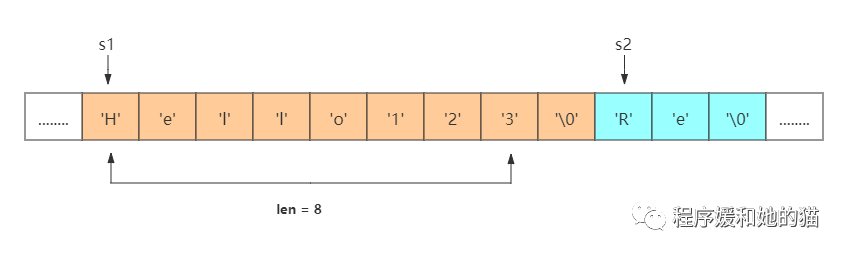 字符串C语言的存储图示2
字符串C语言的存储图示2
与C语言字符串不同,SDS的空间分配策略完全杜绝了发生数据溢出的可能性:当我们需要修改数据时,首先会检查SDS的空间(len)是否满足修改所需的要求,如果不满足的话,则自动将SDS的空间扩展至修改所需的大小,然后才执行实际的修改操作,所以使用SDS既不需要手动修改SDS的空间大小,也不会出现前面所说的数据溢出问题。s1的修改,不会影响到s2,见下图。
见图2,我们可以看到在把"Redis"5个字节扩容到"Redis123"8个字节后,发现free属性的值变成了扩容后字符串的总长度,这就是下边要说的内存重分配策略。
(c)、SDS的内存重分配策略,可以减少修改字符串长度时所需的内存重分配次数,相对于C字符串每次修改都要重新分配内存,可以显著提高性能 C字符串的长度是一定的,所以我们每次在修改字符串长度时,都要做内存的重分配,内存重分配是一个比较耗时的操作,如果程序不需要经常修改字符串还是可以接受的,但是Redis作为一个数据库,里面的数据肯定会被频繁修改,如果每次修改都要执行一次内存重分配,那么就会严重影响Redis的性能。
SDS通过两种内存重分配策略,解决了字符串在修改时的内存分配问题。
第一种策略:空间预分配
空间预分配策略用于优化SDS字符串增长操作,当修改字符串并且需要对SDS的空间进行扩展时,不仅会为SDS分配修改所必要的空间,还会为SDS分配额外的未使用空间free,下次再修改就先检查未使用空间free是否满足,满足则不用在扩展空间。
在扩展SDS空间之前,会先检查未使用空间是否足够,如果足够的话,就会直接使用未使用空间,而无须执行内存重分配。通过这种预分配策略,SDS将连续增长N次字符串所需的内存重分配次数从必定N次降低为最多N次。
额外分配的未使用空间的长度由以下公式决定:
(1)、如果对SDS进行修改之后,SDS的长度(len属性)小于1MB,那么此时额外分配的未使用空间 free 的大小与 len 相等。
举例说明:
如果进行修改之后,SDS的len将变成12字节,那么程序也会分配12字节的未使用空间,SDS的buf数组的实际长度将变成12+12=24字节(len:12,free:12)。
初始SDS如下图所示:
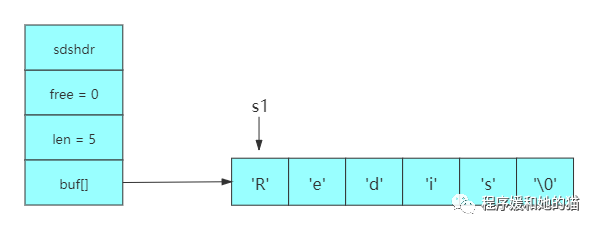
SDS空间预分配图示1
执行strcat(s1, "Cluster"),在字符串"Redis"后面拼接上"Cluster",那么将触发一次内存重分配操作,将SDS的长度修改为12字节,并将SDS的未使用空间同样修改为12字节,如下图所示:
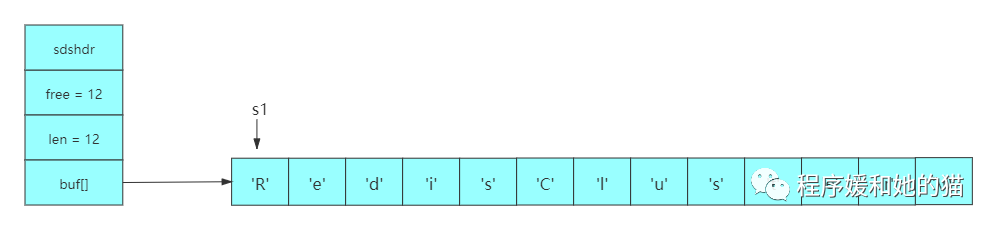
如果这时我们再次执行strcat(s1, "Tutorial"),那么这次将不需要执行内存重分配,因为未使用空间里面的12字节足以保存8字节的"Tutorial",此时free变成12-8=4,len变成12+8=20。执行完这步操作之后的SDS如下图所示:

(2)、如果对SDS进行修改之后,SDS的长度大于等于1MB,那么此时额外分配未使用空间 free 的大小为1M。
举例说明:
如果进行修改之后,SDS的len将变成30MB,那么程序会分配1MB的未使用空间,SDS的buf数组的实际长度将为30MB+1MB。
第二种策略:惰性空间释放
惰性空间释放策略则用于优化SDS字符串缩短操作,当缩短SDS字符串后,并不会立即执行内存重分配来回收缩短后多出来的空间,而是用free属性将这些空间记录下来,如果后续有增长操作,则可直接使用。
举例说明:
如果有个字符串:aaabbbccc,SDS如下图所示:
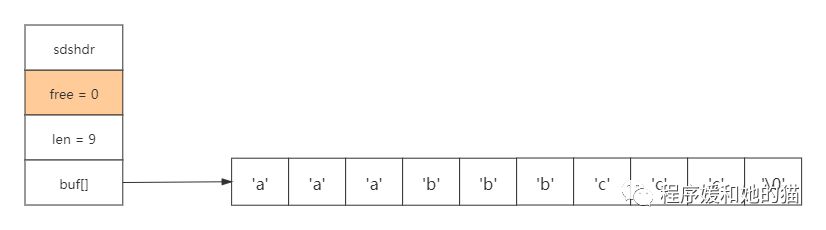
现在要移除ccc,SDS移除后如下图:
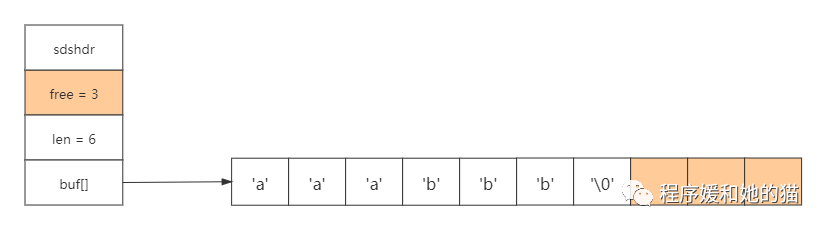 SDS惰性空间释放图示2
SDS惰性空间释放图示2
注意执行字符串缩短操作之后,SDS并没有释放多出来的8字节空间,而是将这8字节空间作为未使用空间保留在了SDS里面(free=8),如果将来要对SDS进行增长操作的话,这些未使用空间就可能会派上用场。
现在想要对上面的字符串后面拼接上"123",因为SDS里面预留的3字节空间已经足以拼接3个字节长的"123"了,所以不需要重新分配内存了。
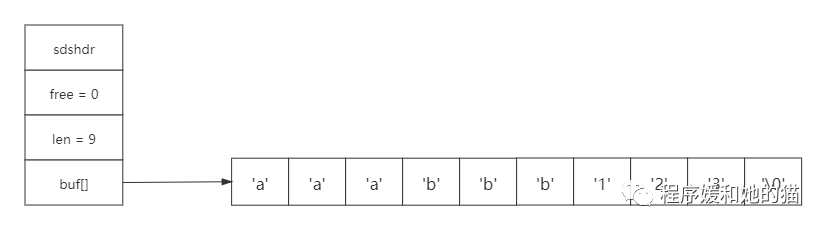
二、List(列表)
1、简单介绍
列表(list)是按照插入顺序排序的字符串列表,可以对列表两端执行插入(push)和弹出(pop)操作,还可以获取指定范围的元素列表、获取指定索引下标的元素等,列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。
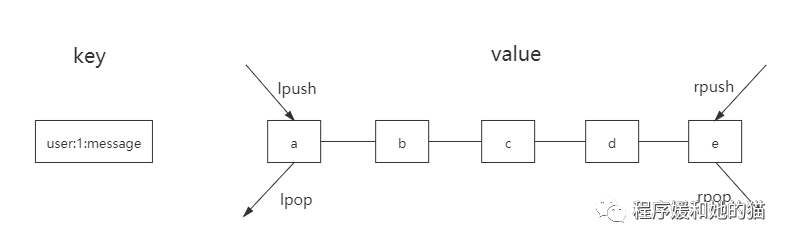
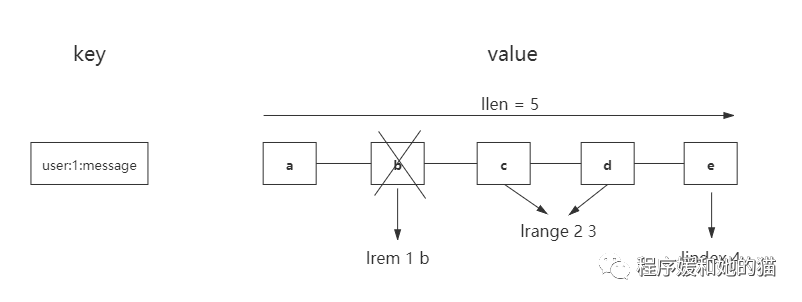
列表(list)有两个特点,:第一、列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表,见下图要获取第5个元素,可以执行lindex user:1:message 4(索引从0算起)就可以得到元素e。第二、列表中的元素可以是重复的,见下图列表中包含了两个字符a。
 列表的两个特点:有序、可重复
列表的两个特点:有序、可重复
2、应用场景
(1)、消息队列
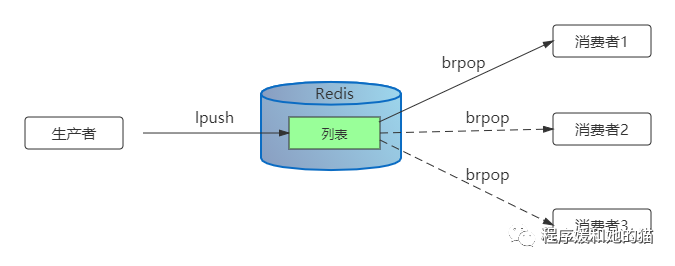
如下图所示,使用Redis的lpush+brpop命令,可以实现一个阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式地“抢”列表尾部的元素。
(2)、最新内容
因为list底层是链表结构,所以查询两端附近的数据性能非常好,适合一些需要获取最新数据的场景,比如新闻类应用的 “最近新闻”。
3、底层实现
ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时 (默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用 linkedlist作为列表的内部实现。
下面的示例演示了列表类型的内部编码,以及相应的变化。
1)当元素个数较少且没有大元素时,内部编码为ziplist;
127.0.0.1:6379> rpush listkey e1 e2 e3
(integer) 3
127.0.0.1:6379> object encoding listkey
"ziplist"
2)当元素个数超过512个,内部编码变为linkedlist:
127.0.0.1:6379> rpush listkey e4 e5 ...忽略... e512 e513
(integer) 513
127.0.0.1:6379> object encoding listkey
"linkedlist"
3)或者当某个元素超过64字节,内部编码也会变为linkedlist;
127.0.0.1:6379> rpush listkey "one string is bigger than 64 byte............... ................."
(integer) 4
127.0.0.1:6379> object encoding listkey
"linkedlist"
三、hash(哈希结构)
1、简单介绍
hash 类型很像一个关系型数据库的数据表,hash 的 Key 是一个唯一值,value 部分是一个 hashmap 的结构。
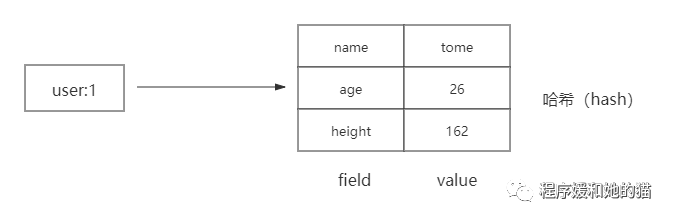 hash类型
hash类型
2、应用场景
hash 类型十分适合存储对象类型数据,相对于使用string存储对象需要把对象转化为json字符串进行存储,hash结构可以任意添加或删除‘字段名’,更加高效灵活。
hmset user:1 name tome age 26 height 162
3、底层实现
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的 结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时哈希类型中元素个数很多,使用ziplist读写效率会下降,而hashtable的读写时间复杂度为O(1),使用hashtable读写效率会提高。
下面的示例演示了哈希类型的内部编码,以及相应的变化。
1)当field个数比较少且没有大的value时,内部编码为ziplist:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
2)当有value大于64字节,内部编码会由ziplist变为hashtable;
127.0.0.1:6379> hset hashkey f3 "one string is bigger than 64 byte...忽略..."
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
3)当field个数超过512,内部编码也会由ziplist变为hashtable;
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2 f3 v3 ...忽略... f513 v513
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
四、set(集合)
1、简单介绍
set 数据类型是一个集合,集合中不允许有重复元素,并且集合中的元素是无序的。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。
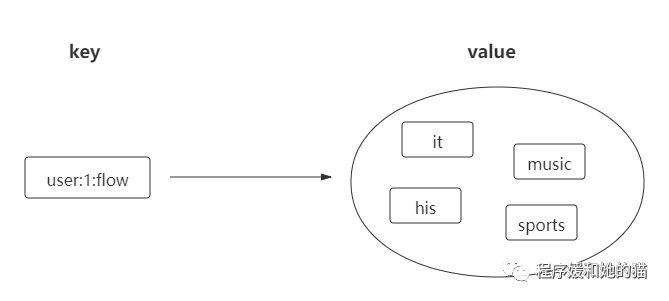 set类型
set类型
2、应用场景
(1)、社交网站,好友/关注/粉丝/感兴趣的人集合
set集合中不允许有重复元素,这一特点使其适合在社交网站存储好友/关注/粉丝/感兴趣的人,set类型提供了一些很实用的命令用于直接操作这些集合:
sadd user:Rose Lulu Kobe Cherry Kitty
sadd user:Tom Richard Kobe Cherry Kitty
sinter命令可以获得Rose和Tom两个用户的共同好友;
sinter user:Rose user:Tom
输出:
1)Kobe
2)Cherry
3)Kitty
sismember命令可以判断Rose是否是Tom的好友;
sismember user:Tom Rose
输出:
(integer) 0
scard命令可以获取Rose的好友数量;
scard user:Rose
输出:
(integer) 3
srem命令可以用来删除好友;
srem user:Rose Lulu Kobe
输出:
(integer) 2
(2)、随机展示
通常,app首页的展示区域有限,但是又不能总是展示固定的内容,一种做法是先确定一批需要展示的内容,再从中随机获取。如下图所示,网易云音乐首页根据平时的听歌风格做的每日推荐。
srandmember key [count],随机从集合返回指定个数元素。
(3)、黑名单/白名单
系统出于安全性的考虑,需要设置用户黑名单、ip黑名单、设备黑名单等,set类型适合存储这些黑名单数据,sismember命令可用于判断用户、ip、设备是否处于黑名单之中。
3、底层实现
intset(整数集合):当集合中的元素都是整数且元素个数小于set-maxintset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使 用hashtable作为集合的内部实现。
下面的示例演示了集合类型的内部编码,以及相应的变化。
1)当元素个数较少且都为整数时,内部编码为intset:
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 4
127.0.0.1:6379> object encoding setkey
"intset"
2)当元素个数超过512个,内部编码变为hashtable:
127.0.0.1:6379> sadd setkey 1 2 3 4 5 6 ... 512 513
(integer) 513
127.0.0.1:6379> scard setkey
(integer) 513
127.0.0.1:6379> object encoding listkey
"hashtable"
3)当某个元素不为整数时,内部编码也会变为hashtable:
127.0.0.1:6379> sadd setkey a
(integer) 1
127.0.0.1:6379> object encoding setkey
"hashtable"
五、sorted set(有序集合)
1、简单介绍
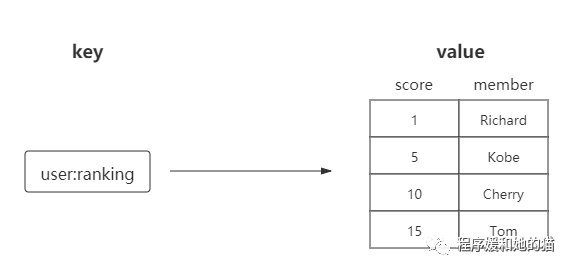
有序集合,它保留了集合不能有重复成员的特性,但不同的是,有序集合中的元素可以排序。在 set 的基础上给集合中每个元素设置了一个分数(score),往有序集合中插入数据时会自动根据这个分数排序。
 zset类型
zset类型
有序集合中的元素不能重复,但是score可以重复,就和一个班里的同学学号不能重复,但是考试成绩可以相同一样。
2、应用场景
(1)、排行榜系统
有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,,榜单的维度可能是多个方面的:按照时间先后顺序、按照播放数量、按照获得的赞数。我们使用点赞数这个维度,讲解一下如何实现。
// 用户Tom在2021年2月21日上传一个视频,赞数初始化为0
zadd user:ranking:2021_02_21 Tom 0
// 获得一个赞,使用zincrby命令加1
zincrby user:ranking:2021_02_21 Tom 1
// 展示获取赞数最多的十个用户
zrevrange user:ranking:2021_02_21 0 9
3、底层实现
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplistentries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配 置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist可以有效减少内存的使用。
skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作 为内部实现,因为此时ziplist的读写效率会下降。
下面的示例演示了集合类型的内部编码,以及相应的变化。
1)当元素个数较少且每个元素较小时,内部编码为skiplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3
(integer) 3
127.0.0.1:6379> object encoding zsetkey
"ziplist"
2)当元素个数超过128个,内部编码变为ziplist:
127.0.0.1:6379> zadd zsetkey 50 e1 60 e2 30 e3 12 e4 ...忽略... 84 e129
(integer) 129
127.0.0.1:6379> object encoding zsetkey
"skiplist"
3)当某个元素大于64字节时,内部编码也会变为hashtable:
127.0.0.1:6379> zadd zsetkey 20 "one string is bigger than 64 byte............. ..................."
(integer) 1
127.0.0.1:6379> object encoding zsetkey
"skiplist"
六、Bitmaps(位图)
1、简单介绍
Bitmaps key-value中的value就是一个字符串,但是操作Bitmaps的value又和操作字符串不太相同,我们可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
许多开发语言都提供了操作位的功能,因为现代计算机用二进制(位)作为信息的基础单位,所以合理地使用位能够有效地提高内存使用率和开发效率。
举个例子演示使用Bitmaps存储数据:
现在我们想用Bitmaps存储字符串"big",'b'、'i'、'g'这三个字符对应的ASCII码分别是98、105、103,对应的二进制分别是 01100010、01101001和01100111,如下图1所示,使用Bitmaps存储'big'如下图2所示。


2、常用命令
对于二值状态统计(这里的二值状态就是指业务数据的取值就只有 0 和 1 两种)的业务场景,非常适合用Bitmaps存储数据,可以有效减少内存的损耗。
在签到打卡的场景中,我们将签到记作1,未签到记作0,用偏移量作为用户的id,它是非常典型的二值状态。
(1).设置值命令
// 偏移量offset从0开始
setbit key offset value
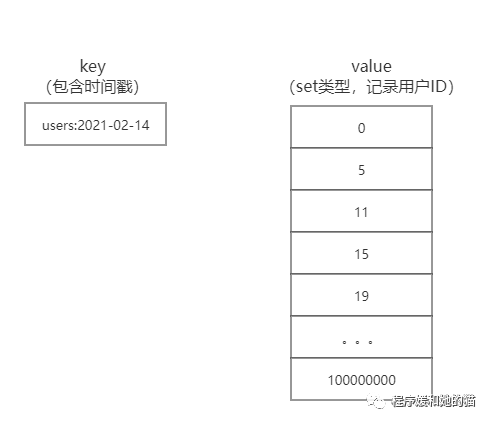
假设现在有10个员工, userid=0,5,11,15,19这五位员工在2021年2月14日签到了,其他都未签到,那么当前Bitmaps结果如下图所示。
 Bitmaps常用命令图示1
Bitmaps常用命令图示1
具体操作过程如下,users:2021-02-14代表2021-02-14这天员工签到情况。
127.0.0.1:6379> setbit users:2021-02-14 0 1
(integer) 0
127.0.0.1:6379> setbit users:2021-02-14 5 1
(integer) 0
127.0.0.1:6379> setbit users:2021-02-14 11 1
(integer) 0
127.0.0.1:6379> setbit users:2021-02-14 15 1
(integer) 0
127.0.0.1:6379> setbit users:2021-02-14 19 1
(integer) 0
(2).获取值
gitbit key offset
获取id=8这位员工在2021-02-14这天是否完成签到,返回0说明未签到。
127.0.0.1:6379> getbit users:2021-02-14 8
(integer) 0
(3).获取Bitmaps指定范围中值为1的个数
bitcount [start][end]
计算2021-02-14这天签到人员的数量。
127.0.0.1:6379> bitcount users:2021-02-14
(integer) 5
(4).Bitmaps间的运算
// op:and(交集)、or(并 集)、not(非)、xor(异或)
// 将操作结果保存在destkey中
bitop op destkey key[key....]
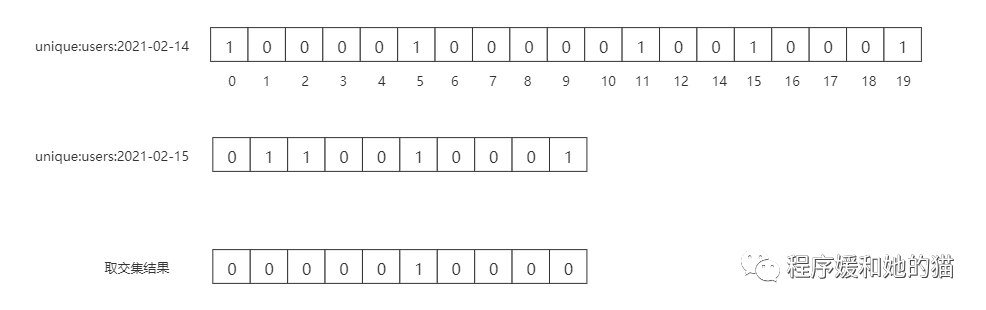
假设2021-02-14完成签到的员工id分别是userid=1,2,5,9,如下图所示。

计算出2021-02-14和2021-02-15这两天都完成签到的人员数量,只有员工5,见下图。
127.0.0.1:6379> bitop and users:and:2021-02-14_15 users:2021-02-14 users:2021-02-15
(integer) 2
127.0.0.1:6379> bitcount users:and:2021-02-14_15
(integer) 2
3、应用场景
当需要统计某个网站的活跃用户时,活跃用户存储1,不活跃用户存储0,刚好可以使用Bitmaps。假设某个网站有1亿用户,每天的活跃用户大概有5千万,如果每天用集合类型和Bitmaps分别存储活跃用户可以得到下表。很明显,这种情况下使用Bitmaps能节省很多的内存空间。
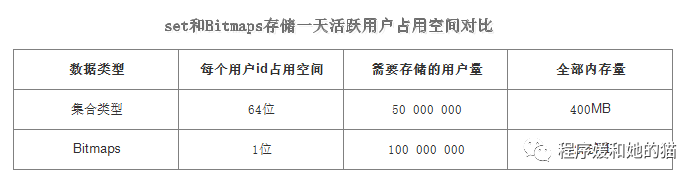
当然随着时间推移节省的内存是非常可观的,见下表。
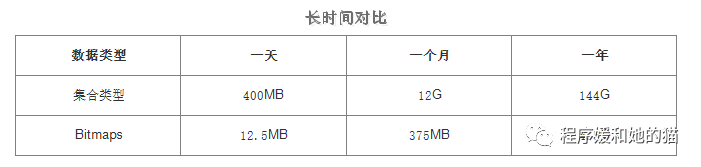
但Bitmaps并不是万金油,假如该网站每天的独立访问用户很少,例如 只有10万(大量的僵尸用户),那么两者的对比如下表所示,很显然,这时候使用Bitmaps就不太合适了,因为基本上大部分位都是0,但是还占着内存。
set和Bitmaps存储一天活跃用户的对比(活跃用户较少)
七、HyperLogLog(基数统计)
1、简单介绍
HyperLogLog 是一种用于统计计数的数据集合类型(实际上是一个字符串),此外HyperLogLog中存储的元素是不重复的,使用HyperLogLog可以非常节省内存地去统计各种计数,比如注册IP数、每日访问IP数、页面实时UV、在线用户数等。但是它也有局限性,就是只能统计数量,而没办法知道具体的内容是什么。
在Redis中,每个HyperLogLog只需要花费12KB内存(HyperLogLog实际上不会存储每个元素的值,它使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量,所以占用内存才会只有12KB这么小),就可以计算接近2^64个元素的基数。HyperLogLog和元素越多就越耗费内存的Set 和Hash类型相比,非常节省内存空间。
2、常用命令
(1).添加元素(注意:元素不重复)
pfadd key element [element …]
pfadd用于向HyperLogLog添加元素,如果添加成功返回1:
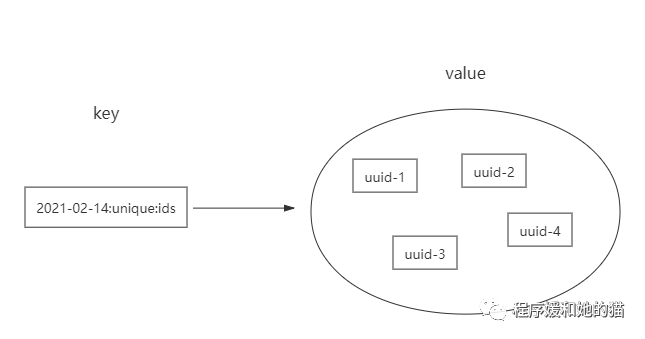
127.0.0.1:6379> pfadd 2021-02-14:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
具体HyperLogLog内部是什么的我们无法得知,但是其对应的set如下图所示。
(2).计算数量
pfcount key [key …]
pfcount用于计算一个或多个HyperLogLog的元素数量,例如2021-02-14:unique:ids中元素数量为4。
127.0.0.1:6379> pfcount 2021-02-14:unique:ids
(integer) 4
此时向2021-02-14:unique:ids插入uuid-1、uuid-2、uuid-3、uuid90,结果是5(前三个元素重复,新增uuid-90)。
127.0.0.1:6379> pfadd 2021-02-14:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-90"
(integer) 1
127.0.0.1:6379> pfcount 2021-02-14:unique:ids
(integer) 5
3、应用场景
当需要对百万、千万甚至亿级别的数据进行统计计数时,用HperLogLog比使用set、hash集合可以节省更多的内存空间。下表列出了使用集合类型和HperLogLog统计百万级用户的占用空间对比。

HyperLogLog的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
综上,我们可以总结出在如下场景可以考虑使用HyperLogLog:
1、只为了计算数据的数量,不需要获取数据内容。
2、可以容忍一定误差率,毕竟HyperLogLog在内存的占用量上有很大的优势,如果对于内存的重视大于误差的存在,可以考虑使用HyperLogLog。
八、GEO(地理信息定位)
1、简单介绍
Redis3.2版本提供了GEO(地理信息定位)功能,支持存储地理位置信息,可以用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
2、常用命令
(1).增加地理位置信息
// 增加地理位置信息命令
// longitude、latitude、member分别是该地理位置的经度、纬度、成员
geoadd key longitude latitude member [longitude latitude member ...]
// 添加北京的地理位置信息。
// 返回结果代表添加成功的个数,如果cities:locations没有包含beijing,那么返回结果为1,如果已经存在则返回0。
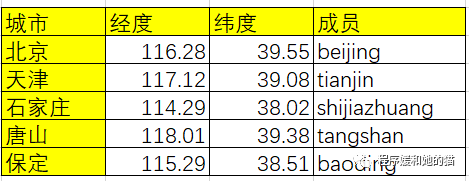
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing (integer) 1
如果需要更新地理位置信息,仍然可以使用geoadd命令,虽然返回结果为0。
// 更新北京的地理位置信息。
127.0.0.1:6379> geoadd cities:locations 117 40 beijing (integer) 0
geoadd命令可以同时添加多个地理位置信息。
127.0.0.1:6379> geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02 shijiazhuang 118.01 39.38 tangshan 115.29 38.51 baoding
(integer) 4
(2).获取地理位置信息
// 获取地理位置信息命令
geopos key member [member ...]
127.0.0.1:6379> geopos cities:locations tianjin
1) 1) "117.12000042200088501"
2) "39.0800000535766543"
(3).获取两个地理位置的距离
// 获取两个地理位置的距离命令
// unit代表返回结果的单位,包括四种,m(meters)代表米,km(kilometers)代表公里,mi(miles)代表英里,ft(feet)代表尺。
geodist key member1 member2 [unit]
// 计算天津到北京的距离,并以公里为单位
127.0.0.1:6379> geodist cities:locations tianjin beijing km
"89.2061"
(4).获取指定位置范围内的地理信息位置集合
// 获取指定位置范围内的地理信息位置集合命令
georadius key longitude latitude radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key] [storedist key]
以一个地理位置为中心算出指定半径内的其他地理信息位置并返回。其中radiusm|km|ft|mi是必需参数,指定了半径(带单位),后面是非必须参数。
withcoord:返回结果中包含经纬度。
withdist:返回结果中包含离中心节点位置的距离。
withhash:返回结果中包含geohash。geohash就是将二维经纬度转换为一维字符串,字符串越长,表示的位置更精确,两个字符串越相似,它们之间的距离越近。
COUNT count:指定返回结果的数量。
asc|desc:返回结果按照离中心节点的距离做升序或者降序。
store key:将返回结果的地理位置信息保存到指定键。
storedist key:将返回结果离中心节点的距离保存到指定键。
// 计算五座城市中,距离北京150公里以内的城市
127.0.0.1:6379> georadiusbymember cities:locations beijing 150 km
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
(5).删除地理位置信息
// 删除地理位置信息命令
zrem key member
// 删除北京的地理位置信息
zrem cities:locations beijing
3、应用场景
适用于需要使用地理位置的业务场景,比如高德地图、微信附近的人、微信摇一摇等等。
九、总结
在这一节中,我们简单介绍了Redis中常用的八种数据结构,对于其内部编码,有SDS、ziplist(压缩列表)linkedlist(链表)hashtable(哈希表)intset(整数集合)skiplist(跳跃表),我们这节只讲了SDS,下节将会讲解一下另外几个内部编码数据结构。
