




计算机硬件内存模型
Java内存模型与计算机硬件内存模型大致相同,理解计算机硬件内存模型,能够帮助我们更好地学习Java内存模型。
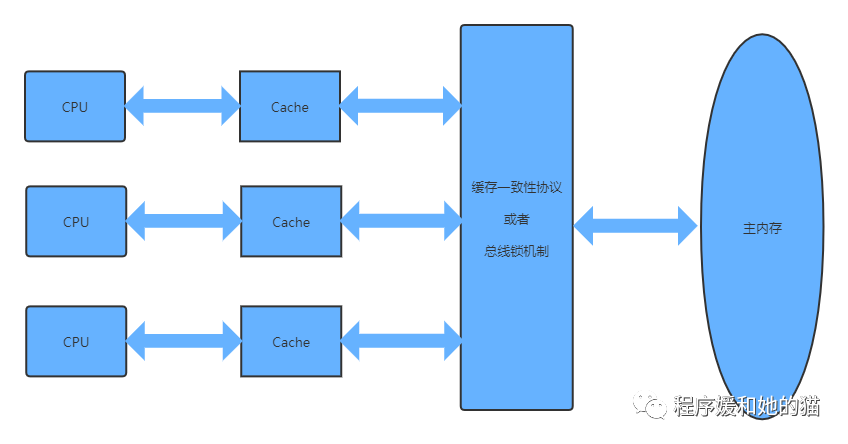
计算机硬件架构的简单图示,如图1所示。
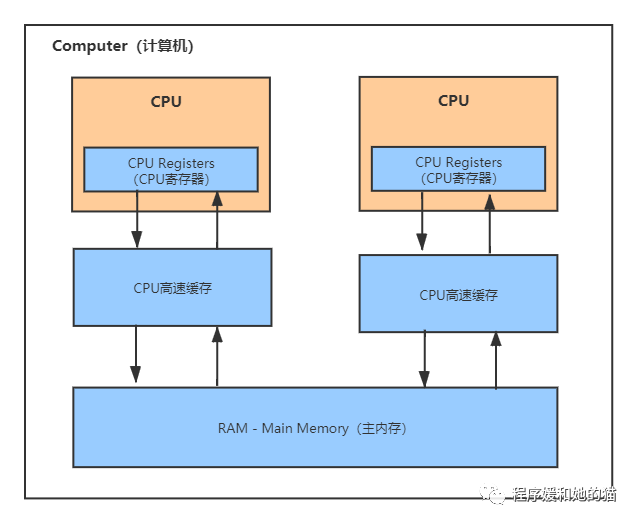
1、使用CPU高速缓存来解决CPU和内存等其他硬件之间的速度矛盾
计算机发展至今,CPU处理器的运算能力越来越强大,为了充分利用CPU处理器的效能,多任务处理在现代计算机操作系统中几乎已是一项必备的功能了。
"更充分地利用CPU的效能"和"让计算机并发执行若干个计算任务"之间的因果关
系,看起来顺理成章,实际上并没有想象中的那么简单,原因就在于绝大多数的运算任务都不可能只靠CPU处理器"计算"就能完成,CPU处理器至少要与内存交互,比如从内存读取运算数据、存储运算结果到内存中等,这些IO操作的速度与CPU处理器的运算速度有几个数量级的差距,所以协调cpu和各个硬件之间的速度差异是非常重要的,要不然cpu就一直在等待,浪费资源。
所以现代计算机系统在CPU中加入了一层读写速度尽可能接近CPU处理器运算速度的高速缓存(Cache),来解决CPU和内存等其他硬件之间的速度矛盾:当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据,当CPU运算结束,将运算结果写入高速缓存,最后把高速缓存中的运算结果同步回内存之中,这样CPU处理器就无须等待缓慢的内存读写了,图示见图2。
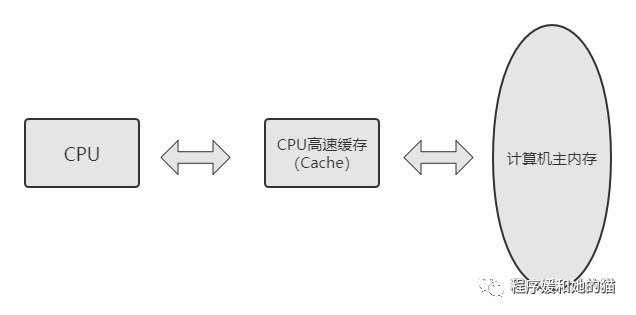
CPU内部的高速缓存:
见图3,摘自《深入理解计算机系统》中描述Intel Core i7处理器的高速缓存的概念模型,L1、L2、L3就是我们所说的高速缓存。在目前主流的多核处理器设计中,一般每个核心都会包含1个L1缓存和1个L2缓存,多个核心共享一个L3高速缓存,L1距离CPU最近,L2距离CPU次远,L3离CPU最远,越重要的数据存储在L1中,越大的数据存储在L2,更大的数据存储在L3,CPU从高速缓存读取数据规则是先找L1,再找L2,最后找L3。

我们可以看自己使用的计算机L1、L2、L3分别多大,查看方式:任务管理器-》性能,见图4右下角,我们发现相比于计算机的内存是几个G,高速缓存几百KB、几MB别真的很小。
2、CPU高速缓存会带来缓存不一致的问题,以及何为缓存不一致?
基于高速缓存很好地解决了CPU处理器与内存的速度矛盾,但是也带来了新的问题:缓存不一致。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享主内存中同一块内存(共享变量),将可能导致多个处理器缓存不一致的问题,如果真的发生这种情况,那同步回主内存时以哪个处理器的缓存数据为准呢?举个简单的例子来说明,比如下面的这段代码:
i = i +1;
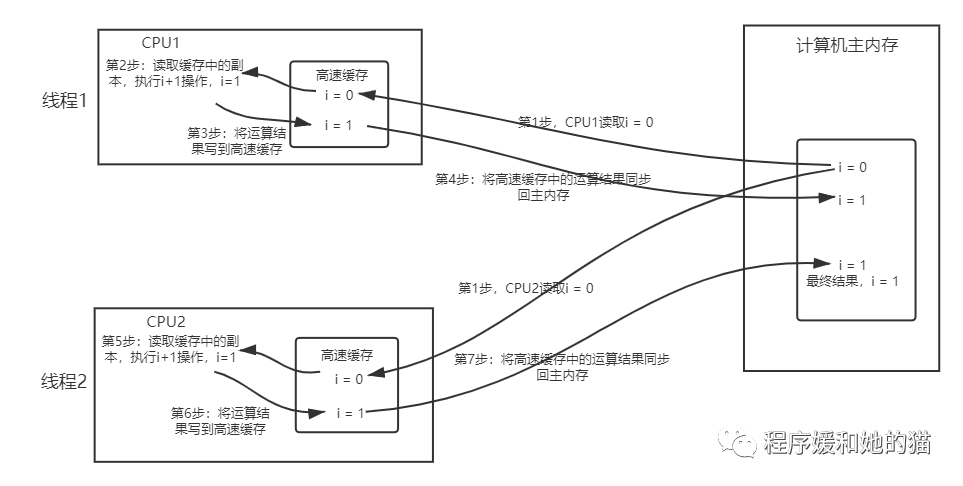
在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存。在多核CPU环境中,同时有2个线程执行这段代码,假如初始时i的值为0,我们希望两个线程执行完之后i的值变为2。但实际运行结果可能并不是我们想要的。
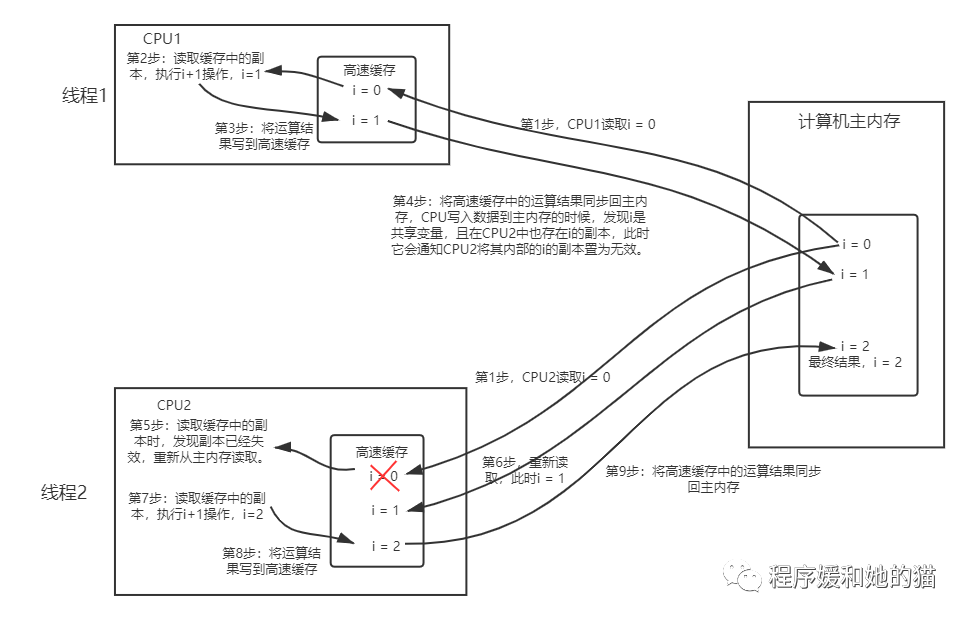
可能存在如下这种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存,最终结果i的值是1,而不是2,这就是缓存不一致的问题,如图5所示。
3、如何解决CPU高速缓存带来的缓存不一致问题?
为了解决缓存不一致性问题,通常来说有以下2种解决方法,一是通过在总线加LOCK#锁的方式,二是通过缓存一致性协议,这2种方式都是硬件层面上提供的方式,见如下图6。
(1)通过在总线加LOCK#锁的方式
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件(如内存)的访问,从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i + 1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作,这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
(2)通过缓存一致性协议
为了解决缓存不一致的问题,需要各个处理器访问高速缓存的时候都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、MESI、MOSI等,最出名的就是Intel的MESI协议,它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取,如图7所示。
Java内存模型(JMM)
1、Java内存模型是什么?以及JMM有什么作用?
Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果,JMM规范了Java虚拟机与计算机内存是如何协同工作的:规定了一个线程何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步地访问共享变量。
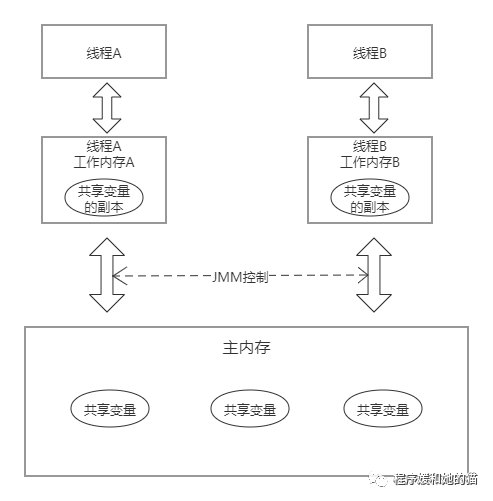
Java内存模型与前面讲的计算机内存模型很相似,这里的主内存相当于计算机中的主内存,这里的线程工作内存相当于计算机CPU处理器中的高速缓存,Java内存模型的抽象示意图如图9所示。
原始的Java内存模型存在一些不足,因此Java内存模型在Java1.5时被重新修订,这个版本的Java内存模型在Java8中仍然在使用。
2、主内存和工作内存
Java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。
此处的变量与Java编程中所说的变量有所区别,此处的变量包括了实例字段、静态字段和构成数组对象的元素,但不包括局部变量与方法参数,因为后者是在虚拟机栈中定义的,虚拟机栈是线程私有的,不会被共享,自然就不会存在线程之间的竞争问题。可以简单地认为主内存是java虚拟机内存区域中的堆,因为堆是线程共享的区域,堆中的变量如果在多线程中使用,就涉及到数据一致性的问题。
主内存:
Java内存模型规定了所有变量都存储在主内存中(Main Memory),该内存是线程共享的,为了方便理解,可以认为是Java堆。此处的主内存可以类比前面讲的物理机的主内存,只不过物理机的主内存是整个机器的内存,而虚拟机的主内存是虚拟机内存中的一部分。
工作内存:
每条线程还有自己的工作内存(Working Memory),该内存是线程私有的,为了方便理解,可以认为是虚拟机栈。可以与前面讲的CPU处理器高速缓存类比。线程的工作内存中保存了被该线程使用到的变量的主内存副本,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
这里需要说明一下:主内存、工作内存与java内存区域中的java堆、虚拟机栈、方法区并不是一个层次的内存划分。这两者是基本上是没有关系的,上文只是为了便于理解,做的类比。
线程、主内存、工作内存三者的交互关系如图9所示。
3、主内存与工作内存之间交互操作
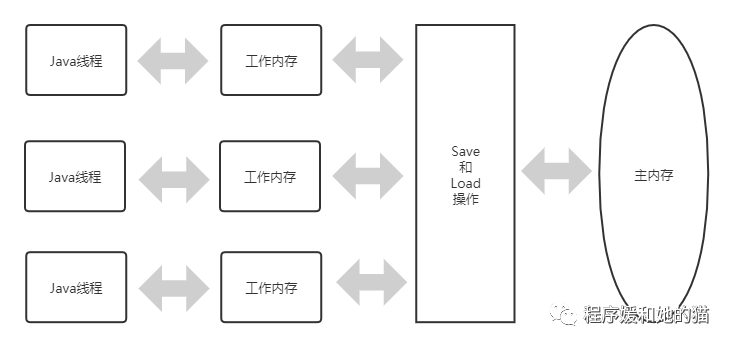
物理机CPU高速缓存和主内存之间的交互有协议(上面讲到的缓存一致性协议),同样的,Java内存模型中主内存和线程的工作内存之间也有具体的交互协议。Java虚拟机中主内存和工作内存的交互,就是一个变量如何从主内存拷贝到工作内存、如何把修改后的变量从工作内存同步回主内存的实现细节,Java内存模型中定义了以下8种操作来完成,虚拟机实现时必须保证每种操作都是原子的、不可再分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许有例外)。
lock(锁定):作用于主内存的变量,一个变量在同一时间只能一个线程锁定,该操作表示这条线程独占这个变量。 unlock(解锁):作用于主内存的变量,该操作把一个处于锁定状态的变量释放出来,这样其他线程才能对该变量进行锁定。 read(读取):作用于主内存的变量,该操作把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。 load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。 use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令的时候就会执行这个操作。 assign(赋值):作用于工作内存的变量,它把执行引擎返回的结果赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的字节码指令时就会执行该操作。 store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。 write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。举个简单的例子来说明上述的操作,有两个线程执行 i = i + 1;这段代码,操作过程如图10所示。
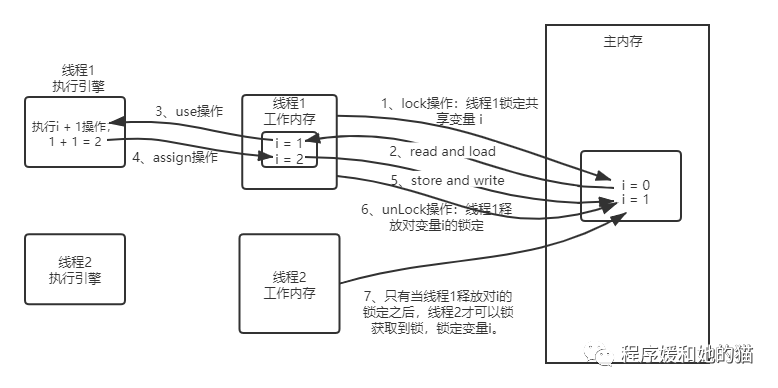
如果把一个变量从主内存复制到工作内存,那就要顺序地执行read和load操作,如果要把变量从工作内存同步回主内存,就要顺序地执行store和write操作。注意,Java内存模型只要求上述两个操作必须按顺序执行,而没有保证是连续执行,也就是说,read和load之间、store和write之间是可以插入其他指令的,比如两个线程分别从主内存中读取变量a和b的值,并不一定要read a、load a、read b、load b,也会出现如下执行顺序:read a、read b、load b、load a。对于这8种操作,虚拟机也规定了一系列规则,在执行这8种操作的时候必须遵循如下的规则:
不允许read和load、store和write操作之一单独出现,也就是不允许从主内存读取了变量的值但是工作内存不接收的情况,即执行了read,不执行load。或者不允许从工作内存将变量的值回写到主内存但是主内存不接收的情况,即执行了store,不执行write。 不允许一个线程丢弃最近的assign操作,即不允许线程在自己的工作内存中修改了变量的值却不同步回主内存。 不允许一个线程回写没有修改的变量到主内存,也就是说如果线程工作内存中变量没有发生过任何assign操作,是不允许将该变量的值回写到主内存的。 一个新的变量只能在主内存中产生,不允许在工作内存中直接使用一个未被初始化(初始化,即load或assign)的变量,也就是说对一个变量实施use、store操作之前,必须先经过assign和load操作。 一个变量在同一时刻只能被一个线程对其进行lock操作,也就是说一个线程一旦对一个变量加锁后,在该线程没有释放掉锁之前,其他线程是不能对其加锁的,但是同一个线程对一个变量加锁后,可以继续加锁。此外释放锁次数必须和加锁次数相同,即多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。 如果对一个变量执行lock操作,就会清空工作内存中该变量的值,在执行引擎使用这个变量之前,需要重新执行load或assign操作初始化变量的值。 不允许对没有lock的变量执行unlock操作,如果一个变量没有被lock操作,那也不能对其执行unlock操作,当然一个线程也不能对被其他线程lock的变量执行unlock操作。 对一个变量执行unlock之前,必须先把变量同步回主内存中,也就是说在对一个变量执行unlock操作之前,必须先执行store和write。
这8种内存访问操作以及上述对这8种操作的规则限定,再加上后续即将讲到的volatile的一些特殊规定,就已经完全可以确定Java程序中哪些内存访问操作在并发下是安全的。但是使用上述的方法去判断一个操作是否并发安全,虽然严谨,却也有一定的缺点:很繁琐,实践起来很麻烦。后续我们将介绍这种方法的一个等效判断原则-先行发生原则,用来确定一个访问在并发环境下是否安全。
