




“现代CPU都采用了流水线技术,使得同一时刻可以执行多条指令。也就是说一个时钟周期内其实是有多条指令在同时执行。而指令并行引发的一个问题就是数据冒险。为了降低CPU因数据冒险而运行效率低下,CPU又采用了乱序执行技术尽量避免这个问题。那么硬件的乱序执行会对Java程序产生什么影响呢?
”
乱序执行对并发编程的影响
CPU的乱序执行,编写的程序运行出来的结果就会出现一些让人匪夷所思玄之又玄的计算结果。比如下面一段程序:
public class ConcurrencyTest03 {
public static void main(String[] args) {
Demo demo01 = new Demo();
for (;;){
new Thread(()->{
demo01.actor1();
}).start();
new Thread(()->{
demo01.actor2();
}).start();
// ....new了很多Thread操作demo01对象
}
}
}
class Demo {
private int x, y;
private int a, b;
public void actor1() {
x = 1;
b = y;
}
public void actor2() {
y = 2;
a = x;
}
}
当多个线程同时操作共享对象demo01时,我们可以猜测一下变量a,b的结果总共有多少种情况:
# 情况一:a=1,b=0
线程1 执行了actor1()方法 x=1, b=0;
线程2 执行了actor2()方法 y=2,x已经被线程1赋值,因此 a=1;
# 情况二:a=0,b=2
线程1 执行了actor2()方法 y=2, a=0;
线程2 执行了actor1()方法 x=1,y已经被线程1赋值,因此 b=2;
# 情况三:a=1,b=2
步骤1:线程1 执行了actor1()方法 x=1, 此时CPU发生了上下文切换,切换到线程2执行...
步骤2:线程2 执行了actor2()方法 y=2, x已经被线程1赋值,因此 a=1,接着又发生了上下文切换,切换到线程1执行...
步骤3:线程1 继续步骤1的指令往下执行,为b赋值时,由于在步骤2中,已经将y赋值为2,因此 b=2
以上三种情况是我们可以预见的,我么先默认程序是按照方法内代码的顺序翻译成对应的机器指令,然后一条条顺序执行。而且我们还考虑了CPU时间片调度机制,因此出现了情况三的结果。
但是 还有第四种情况:a=0,b=0;这种情况的出现是因为编译器可能优化了代码,将一些没有依赖关系的指令重排序了,也有可能CPU内部进行了乱序执行(也称为CPU指令重排序)产生的结果。
验证 a=0,b=0
出现第四种情况原因是这样的
/*
actor1()方法内的两条代码没有依赖关系,
因此在CPU执行对应的指令时将两条代码对应的指令进行了重排序,
因此 b=y 在前,x = 1这条代码在后
*/
public void actor1() {
b = y;
x = 1;
}
/*
actor2()同理
*/
public void actor1() {
a = x;
y = 2;
}
步骤1:线程1 执行了actor1()方法 b = y;y还没被赋值,因此b = 0。此时CPU发生了上下文切换,切换到线程2执行... 步骤2:线程2 执行了actor2()方法 a = x;x还没被赋值,因此a = 0。接着又发生了上下文切换,切换到线程1执行...
因此 a=0,b=0;
我们可以利用一款并发测试工具,验证想法。jcstress是JDK官方提供的并发压测工具。构建好相关的骨架就可以进行测试。关于测试骨架的构建不做过多赘述,网络上有很多教程可以学习该工具。
@JCStressTest
@Outcome(id = {"0, 2", "1, 0", "1, 2"}, expect = Expect.ACCEPTABLE, desc = "ethan'ok")
@Outcome(id = {"0, 0"}, expect = Expect.ACCEPTABLE_INTERESTING, desc = "ethan'interest")
@State
public class ConcurrencyTest {
int x;
int y;
@Actor
public void actor1(II_Result r) {
x = 1;
r.r2 = y;
}
@Actor
public void actor2(II_Result r) {
y = 2;
r.r1 = x;
}
}
第一个@Outcome中的id是我们预期的值,也就是对应我们在第一部分分析的三种情况,第二个@Outcome是感兴趣情况也就是a=0,b=0的情况。运行起来后观测结果
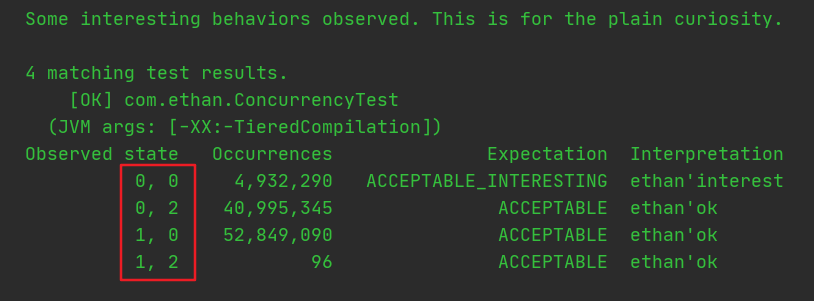
可以看到state列中的情况,在并发执行下【a=0,b=0】出现了 4百多万次,【a=0,b=2】出现4千多万次,【a=1,b=0】出现了5千多万次【a=1,b=2】出现了96次。
CPU这么佛系,Java程序咋办?
总的来说为了Java开发者专心做业务不用理会底层硬件细节。JMM模型帮开发者构建了相关的规则,只要根据这些规则编写代码,无论CPU多么佛系,我们编写出的代码的计算结果都会是唯一的并且确定的。这些规则会对编译器、CPU等硬件做相关的约束。这个约束就是不能改变程序运行的结果,至于什么编译器优化,重排序、乱序执行什么的,只要不改变运行结果,你们可以随便搞。
as-if-serial规则:该规则保证了在编写单线程程序时,执行结果不会被改变,该结果是唯一且永远正确的 happens-before规则:该规则保证了只要正确使用同步机制控制多线程,执行出来的结果不会被改变,唯一且正确;因此如果遵循了happens-before规则,那么多个线程对内存操作就是可见的了。
大名鼎鼎的volatile关键字就是happens-before规则之一。因此一提到volatile,就会想起可见性,有序性(指令不重排)。
无论CPU多么佛系,JMM替开发者扛着,保证程序运行的顺序是按照我们书写的顺序(给开发者一个幻觉,看似顺序,其实内部还是可能乱序,但是并不影响计算结果)。因此只要根据相关的规则书写代码,就可以避免出现让人匪夷所思的计算结果。毕竟有时候CPU在执行计算的时候自己也不知道该执行哪一条指令。
当然如果上面演示的程序在变量x,y都添加volatile的话就不会出现情况四【a=0,b=0】的情况,这里就不演示了。
总结
为了提高CPU的计算性能和吞吐量,现代CPU采用了流水线技术,但是随之带来了一系列不能避免的问题,比如控制冒险,数据冒险,结构冒险。而为了降低这些冒险的出现机率,又采用了诸如操作数前推、乱序执行等技术。这些技术的引入对应用软件的编写就增加了难度。好在作为一个Java开发者,JMM相关规范和底层的实现屏蔽了硬件上的特性。只要开发者按照规范编写代码就不会出现一些解释不通的Bug。
