




周末快乐。今天周赛,第一题直接模拟,用了一个时间复杂度比较高的方法;第二题贪心;第三题考数据结构,个人认为借助C++ STL库可以大大降低这类题的难度,许多实现细节可以不关注,从而可以快速解决;第四题状态压缩+二分(此"二分"非彼二分)。今天的代码敲了些空格,看起来舒服些,开始培养这个习惯。
5894. 至少在两个数组中出现的值
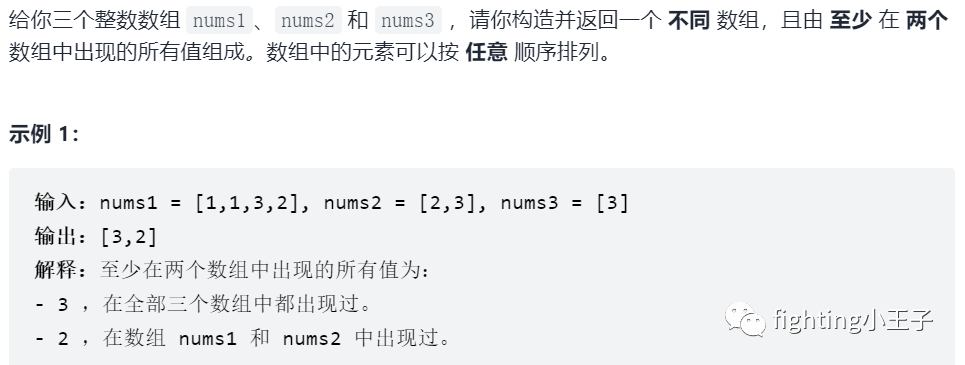

数据规模比较小,直接排序去重,然后统计每个元素出现次数。这样的时间复杂度应该是o(nlogn),也可以把vector转存到set实现去重,空间换时间。
class Solution {public:int cnt[110];vector<int> twoOutOfThree(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3) {memset(cnt , 0 , sizeof cnt);vector<int> ans;sort(nums1.begin() , nums1.end());nums1.erase(unique(nums1.begin() , nums1.end()) , nums1.end());for(auto &x : nums1)cnt[x] ++;sort(nums2.begin() , nums2.end());nums2.erase(unique(nums2.begin() , nums2.end()) , nums2.end());for(auto &x : nums2)cnt[x] ++;sort(nums3.begin() , nums3.end());nums3.erase(unique(nums3.begin() , nums3.end()) , nums3.end());for(auto &x : nums3)cnt[x] ++;for(int i = 1; i <= 100; i++)if(cnt[i] >= 2) ans.push_back(i);return ans;}};
5895. 获取单值网格的最小操作数



说来也奇怪,做的时候直接展成一维,然后取中位数计算能不能转成单值网格,没多想。回头琢磨,确实是贪心的思路,只是当时没注意。
首先操作次数要最少,那么最后转换成的那个元素一定是网格里现有的,这很显然。若不然,转成了一个比网格中所有元素都大的数,那需要的操作次数一定比转成网格中最大的数需要的次数多。另外,转成网格中哪个数操作次数最少,可以这样思考,目的是要把所有元素移动到同一位置,都移到中位数一定是整体移动距离最少的(没有严格的数学证明...)。
代码写得比较长,但实际就做了两件事,找中位数,然后统计将其他数变成中位数需要的操作。代码长是因为分了元素为奇数和偶数个两种情况,偶数个元素时还单独算了一遍转成第n和第n+1个元素需要的操作数,取最小。
class Solution {public:int minOperations(vector<vector<int>>& grid, int x) {vector<int> num;int ans = 9999999999;for(auto &x : grid){for(auto &y : x)num.push_back(y);}sort( num.begin() , num.end() );int n = num.size();if(n%2 == 0){int id1 = n / 2 , id2 = n / 2 - 1;bool flag = true;int cnt = 0;for(int i = 0; i < n; i ++){if(i != id1){if(abs(num[i] - num[id1]) % x == 0) cnt += abs(num[i] - num[id1]) / x;else flag = false;}if(flag == false) break;}if( flag )ans = min( cnt , ans );cnt = 0; flag = true;for(int i = 0; i < n; i ++){if(i != id2){if(abs(num[i] - num[id2]) % x == 0) cnt += abs(num[i] - num[id2]) / x;else flag = false;}if(flag == false) break;}if( !flag ) return -1;else ans = min( ans , cnt );}else{int id = n / 2;bool flag = true;int cnt = 0;for(int i = 0; i < n; i ++){if(i != id){if(abs(num[i] - num[id]) % x == 0) cnt += abs(num[i] - num[id]) / x;else flag = false;}if(flag == false) return -1;}ans = min( ans , cnt );}return ans;}};
5896. 股票价格波动



class StockPrice {public:StockPrice() {}void update(int timestamp, int price) {}int current() {}int maximum() {}int minimum() {}};/*** Your StockPrice object will be instantiated and called as such:* StockPrice* obj = new StockPrice();* obj->update(timestamp,price);* int param_2 = obj->current();* int param_3 = obj->maximum();* int param_4 = obj->minimum();*/
快速根据key来更新value,要求key与value有准确的映射关系,而由于key取值较大,数组不太合适,可以用哈希表来实现。快速获取最大最小值,这里我使用的是两个堆,一个大顶堆,一个小顶堆。这个思路还有一个问题,如何准确地修改某个元素,修改完还要维护大/小顶堆的性质,同时还要均衡时间复杂度。此时如果堆中仅保存price这一个关键字就不太好做了,需要同时存上timestamp和price构成一个pair。插入或者修改元素时只管插入,只是在查询最大最小price时,若堆顶元素的timestamp与哈希表里的该timestamp对应的不是同一个price,说明该timestamp是被修改过的,原来的最小/大值已被修改了,删掉堆顶元素,重新找下一个值就行。复杂度o(nlogn)。
前面有过几次这类的题,我都用堆解决的,这题也是首先想到的就是堆。评论区也有同学粘了个multiset的代码,set可以精准查找然后删除,底层由红黑树实现,整体时间复杂度也是o(nlogn),代码更精简美,思路也更容易想通,代码我写了一遍,学习一哈。
typedef pair<int,int> pii;class StockPrice {public:unordered_map<int , int> record;priority_queue<pii , vector<pii> , less<pii> > maxp;priority_queue<pii , vector<pii> , greater<pii> > minp;int cur;StockPrice() {cur = -1;}void update(int timestamp, int price) {if(timestamp > cur)cur = timestamp;record[timestamp] = price;maxp.push({price , timestamp});minp.push({price , timestamp});}int current() {return record[cur];}int maximum() {pii top = maxp.top();while(record[top.second] != top.first){maxp.pop();top = maxp.top();}return top.first;}int minimum() {pii top = minp.top();while(record[top.second] != top.first){minp.pop();top = minp.top();}return top.first;}};
class StockPrice {public:unordered_map<int , int> record;multiset<int> p;int cur;StockPrice() {cur = -1 ;}void update(int timestamp, int price) {if(record.count(timestamp)){auto it = p.find(record[timestamp]);p.erase(it);}record[timestamp] = price;p.insert(price);cur = max(cur,timestamp);}int current() {return record[cur];}int maximum() {return *prev(p.end());}int minimum() {return *p.begin();}};
5897. 将数组分成两个数组并最小化数组和的差




2n个元素分成两个集合,使两个集合的和的差最小,可以认为是给i个元素加上负号,剩下的元素加正号,使2n个元素和最小。可以状态压缩枚举i。但是,2n能到30,状态压缩直接枚举的话,2^30超过了10^9,会超时。可以分成两部分来考虑。前n个元素里选i个加正号,后n个元素里选j个加正号,剩下的2n-i-j个元素都加负号,找和最小的情况。这也就是把2n分成两块来做,分治的思想,看起来,规模只是从30变成15,但指数是爆炸式增长的,这个减小实质上给性能带来很大提高。
操作上,状态压缩模拟前n个元素选取方案,找出前n个元素中任意选i个元素添加正号,剩下元素添负号后所有可能的和,后n个同理。这一步数据处理完成后,对于每个i,再遍历一次,找后n个元素中选n-i个元素添加正号时整体的和的最小绝对值。看到这估计会有点难懂,可以看看代码实现细节,帮助理解。
class Solution {public:vector<int> sum1[16], sum2[16];int minimumDifference(vector<int>& nums) {int n = nums.size() / 2;int ans = 1e9 + 10;for(int i = 0; i < ( 1 << n ); i ++ ){int sum = 0, cnt = 0;for(int j = 0; j < n; j ++){if(i >> j & 1){cnt ++;sum += nums[j];}else{sum -= nums[j];}}sum1[cnt].push_back( sum );}for(int i = 0; i < 16; i ++)sort(sum1[i].begin() , sum1[i].end());for(int i = 0; i < ( 1 << n ); i ++ ){int sum = 0, cnt = 0;for(int j = 0; j < n; j ++){if(i >> j & 1){cnt ++;sum += nums[n + j];}else{sum -= nums[n + j];}}sum2[cnt].push_back( sum );}for(int i = 0; i < n; i ++)sort(sum2[i].begin() , sum2[i].end());for(int i = 0; i < n; i ++){for(int j = sum1[i].size()-1 , k = 0; j >= 0; j--){/* 注意 k 和 j 不能同时从0或者同时从尾开始扫 否则会丢失解*/while(k < sum2[n - i].size() && sum1[i][j] + sum2[n - i][k] < 0)k ++;if(k < sum2[n - i].size())ans = min(ans , abs(sum1[i][j] + sum2[n - i][k]));if(k >= 1)ans = min(ans , abs(sum1[i][j] + sum2[n - i][k - 1]));}}return ans;}};
