





引入 | 记一次从执行计划定位SQL问题及性能优化的思考过程
一、问题复现:
写在前面的话,童鞋遇到了这样一个问题-SQL慢查询,在30万数据中查询,某个接口响应耗时,导致页面直接挂掉,其中,SQL引入了视图,比较复杂,这里暂时就不贴代码了。
下面列举几个示例,在实际项目中,当数据量一上来,就发现索引其实是多么的重要,怎么排查视图中的表有没有建立索引,其中索引有没有失效,哪些索引没有利用上,又是如何失效的,耗时分析等,或许这能给我们在实际项目中作SQL优化,在整体思路上有着及其重要的启发!
二、假设猜想:
1、在sql查询条件中,未对条件字段建立索引?
2、在view中,表的访问方式、连接顺序以及连接方式是否合理?
3、在已建立的索引中,索引是否命中,是否存在失效的情况,走全表扫描?
三、思考过程:
从页面发起请求到后端服务接口响应耗时至页面直接挂掉:
1、首先,通过F12查阅页面加载耗时以及对后端接口加入耗时日志,得以分析最长耗时卡在DAO层,即SQL业务逻辑查询-结果响应。
2、接着,由于这里是远程排查,我们可以通过堡垒机的方式登入或者其他远程方式,然后打开Oracle客户端PL/SQL Developer,拷贝日志中打印的SQL语句在客户端查询。
3、然后,笔记本电脑的话可通过Fn+F5快捷键,在客户端打开当前SQL的查询计划进行具体排查,作进一步分析。
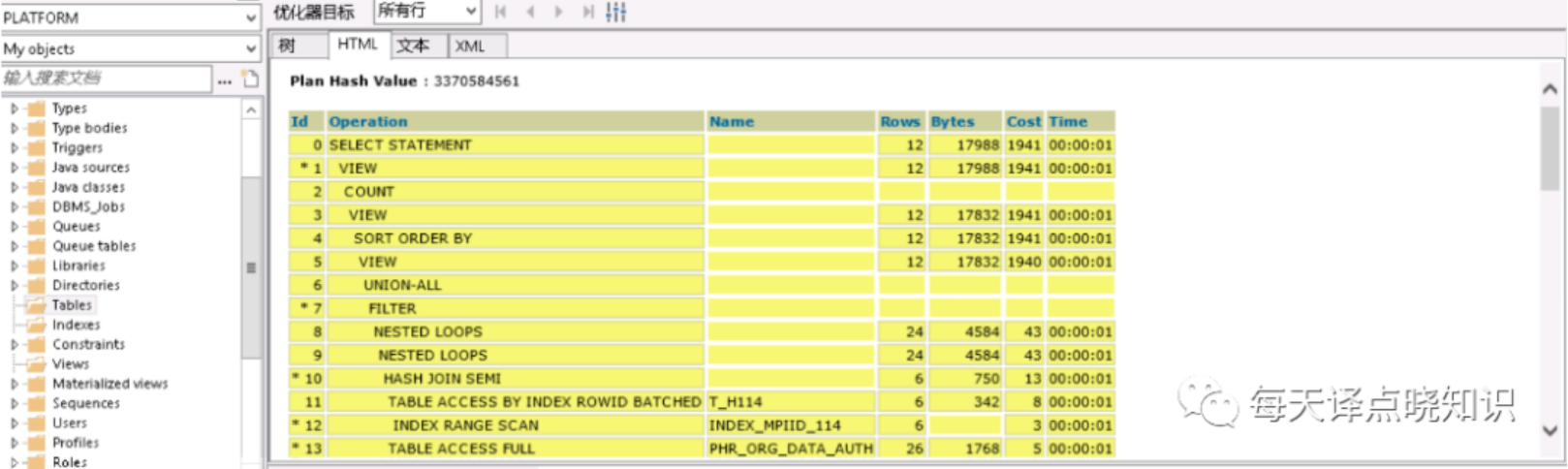
图一
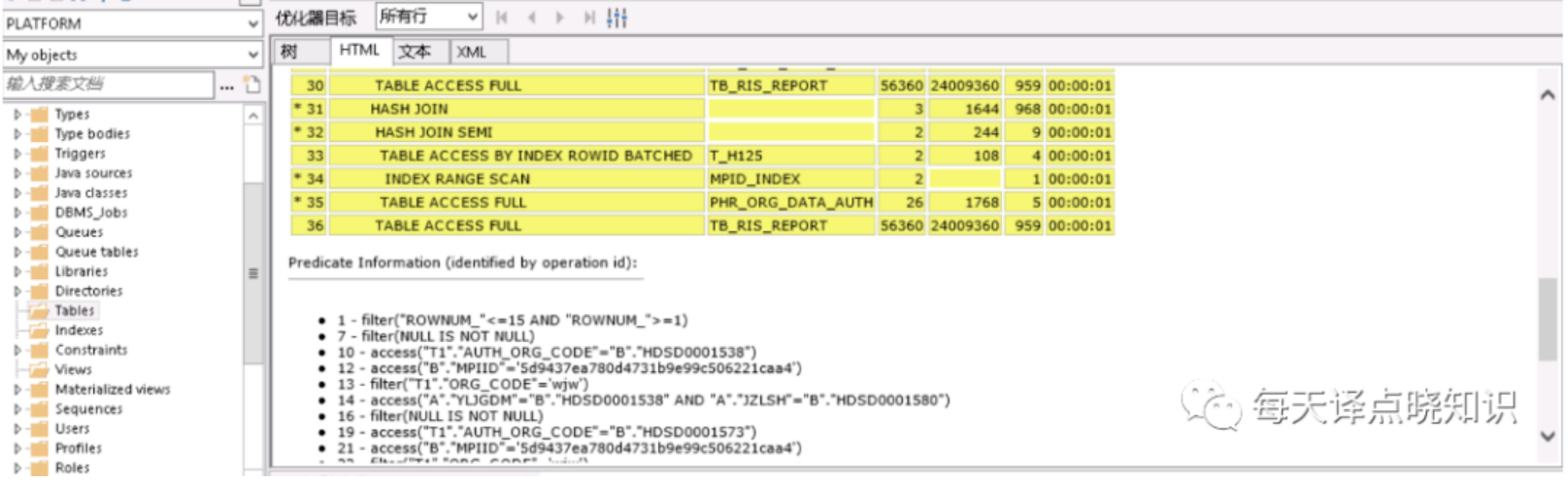
图二
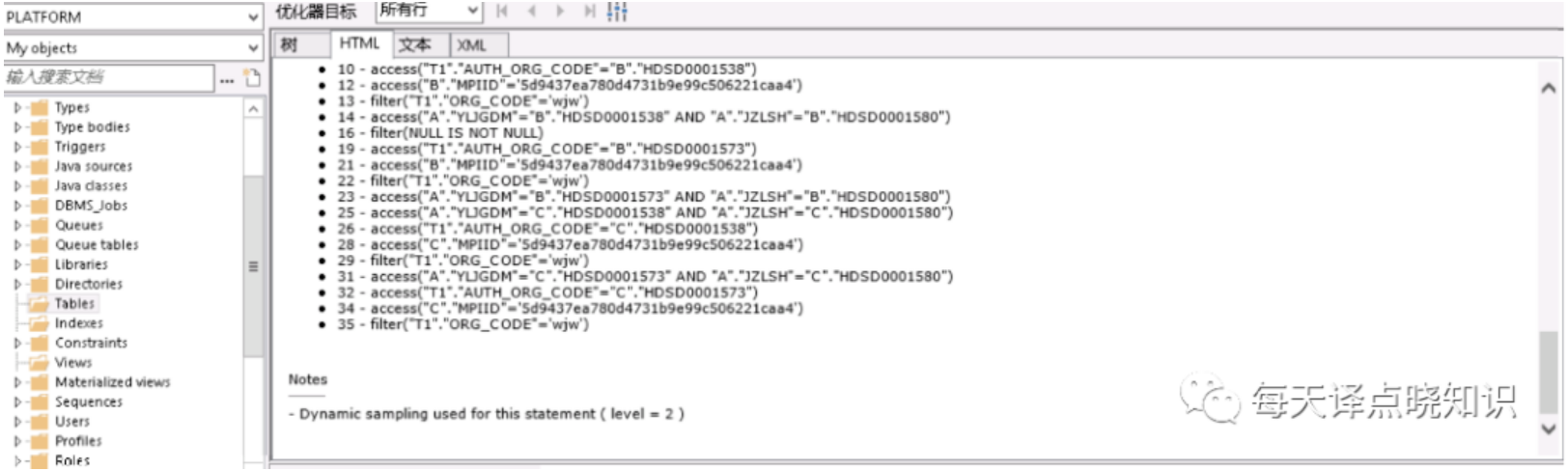
图三
这里,先对执行计划中一些概念作下详细说明:
资源成本耗费 (COST)
全表扫描(TABLE ACCESS FULL)
索引扫描 (INDEX SCAN)
嵌套循环(NESTED LOOPS)
哈希连接(HASH JOIN)
排序-合并连接(SORT MERGE JOIN)
其中,每一个执行步骤都有对应的COST,可以从单步COST的高低,以及单步的估计结果集-对应ROWS/基数,来分析表的访问方式、连接顺序以及连接方式是否合理。
我们从执行计划中可知,其中可看到走了全表扫描-TABLE ACCESS FULL的表,且扫描的行数ROWS以及COST也占居最高。分析到了这里,问题的根源离我们又近了一步。但是当我们查看打印出来的SQL语句并没有查到当前表名,那会不会是存在view视图中呢?
我们在PL/SQL客户端通过每个表的仔细查阅,终于在view视图中找到了走全表扫描的表,这下问题就可以随之迎刃而解?
将复杂的SQL语句作查询步骤化解-"以大化小,以小化无",拆解成多个单步骤SQL片段,对每个SQL片段进行查询计划分析。但这里可优先对走全表扫描的表作进一步排查,分析之后,果然验证了之前的猜想。
上述全表扫描的表这里分别以A、B表昵称,在A、B表中分别有两个字段作为查询的条件属性,其中A表走模糊查询like '%A'而未命中索引,另一个B表是走条件查询未建立索引。针对上述排查后的结果,分别对A表作like 'A%'(可通过oracle函数达到like效果,但模糊匹配,不管是前缀还是后缀最终还是要扫描行数,其实还是可以更细粒度的优化滴~暂不详述),对B表查询条件字段建立INDEX索引,类型为Normal即可。
重点说明:本文重点在各种优化的思路,例如百度的搜索引擎,海量数据中检索有时候也是需要产品作出一部分妥协的,分页限制,滚动分页等,上千万亿级的数据不分库分表,可以上ElasticSearch分布式全文搜索引擎,参考->https://www.modb.pro/db/166356
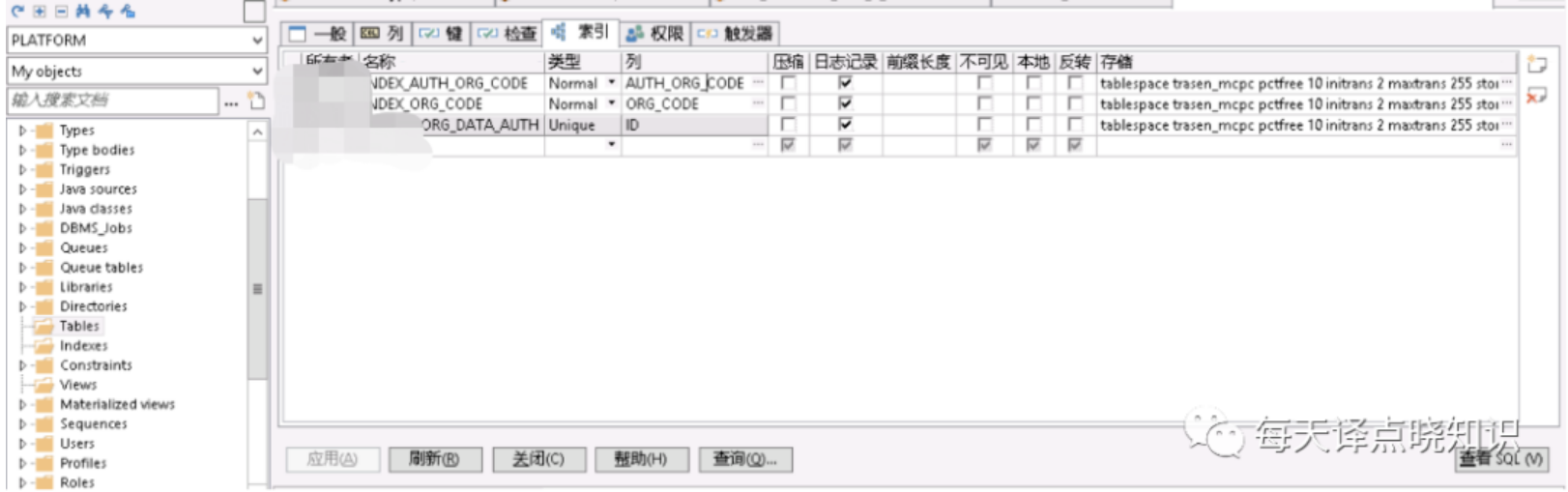
图四
Ok,now,我们继续看一下select的效果,页面正常请求后端服务接口,完成数据加载渲染,页面终于跑起来了,后端服务接口响应耗时日志打印,也从之前的请求耗时大幅缩短,继续在Oracle客户端查看执行计划,也未出现走全表扫描的情况。
四、解决方案:
针对失效的索引或查询条件字段未建立的索引,根据查询计划定位其问题及根源,并同时对参与条件查询的字段,调整并建立合适的索引及类型。
五、反思总结:
当然优化的点有很多,上述只是通过查询计划对索引作了合理的调整,当数据量基数非常之大的时候,关系型数据库可作分库分表,非关系型数据库可对数据作建模设计,选取Elastic Search-分布式全文检索-倒排索引或MongoDb等等,根据合适的业务场景择优选取,具体也可参考小编CSDN博文:
https://blog.csdn.net/yxd179引出这样一个小问题-思考:当你去图书馆借书或者书店的时候,想必都有用到过通过书的类型,书的名称去缩小你需要查找的范围,那为什么通过目录,索引搜索就这么快?什么情况下索引会失效?Oracle、Mysql、ES索引底层又是怎么实现的呢?^_^
当然,我们也可以在工作之余去看看底层的数据结构,B树,B+树,Hash索引,倒排索引......
在SQL优化这一块,若大家有需要,欢迎在文末留言分享:
根据大家的需求度,后续考虑在GitHub上开源一款SQL插件,支持插拔式-需要时开启,可自动将复杂SQL填充参数,打印SQL语句,并打印其执行计划及耗时,助力于生产环境分析SQL,排查问题,性能优化。
引出这样一个小案例-思考:
现有这样一个场景,在某张单表中数据量在1000-2000万,怎么样能够通过程序快速把这样1000-2000万数据读取,并同步到一些其他的大数据组件作下一步数据分析。
或许这就是一点不一样的IDEA应对不一样的场景,深度分页越往后,查询的效率会下降。
这里也给出Oracle跟MySQL在上千万级数据作深度分页优化的IDEA:
1、Oracle非主键字段实现自增
select count(*) from yd_info;
(1)alter table yd_info add info_id int;
select * from yd_info;
(2)update yd_info set info_id=rownum;
(3)commit;
select * from yd_info;2、Mysql非主键字段实现自增
(1)先添加字段,设置字段类型等基本属性:
alter table yd_info add info_id int(11) not NUll;
(2)为该字段添加任意key:
alter table yd_info ADD KEY `INFO_ID_KEY`(`INFO_ID`);
(3)将该字段修改为自增属性:
alter table yd_info MODIFY `INFO_ID` int(11) auto_increment;上面就此建立了INFO_ID辅助字段,当然索引是需要存储的,内存换时间,择优选取,当你想要设置的区间(start,end)跟info_id作判断即可,想必我们在SQL分页中怎么避免深度分页的问题啦!
附注:Mark一下之前的思考过程,坚持不易-自我驱动,由于时间等原因,阐述不一定俱全。本文暂时就到这里。对于SQL性能调优这块,方式有很多,希望对各位读者,在数据库SQL问题定位过程中能够有所帮助,欢迎提出宝贵建议^_^
「 往期文章 」
开源数据库 | 记一次基于鲲鹏欧拉操作系统openGauss实践过程
Elasticsearch读写数据工作原理 | MySQL的重复数据插入处理
Elasticsearch进阶篇 | 记kibana执行dsl脚本实战过程
Kafka | 记一次修复Kafka分区所在broker宕机故障-引发当前分区不可用的思考过程
序列化 | Google的Gson与Alibaba的FastJson机制

