




Kafka作为消息中间件是各公司平台架构绕不开的话题。
不管你是把Kafka作为队列,还是消息通道,都需要在应用中通过producer写数据到Kafka,再用consumer从Kafka中消费。应用往Kafka写数据的原因有很多:用户行为分析、日志存储、异步通信等。多样化的使用场景带来了多样化的需求:消息是否能丢失?是否容忍重复?消息的吞吐量?消息的延迟?
这么苛刻的要求Kafka能满足吗?
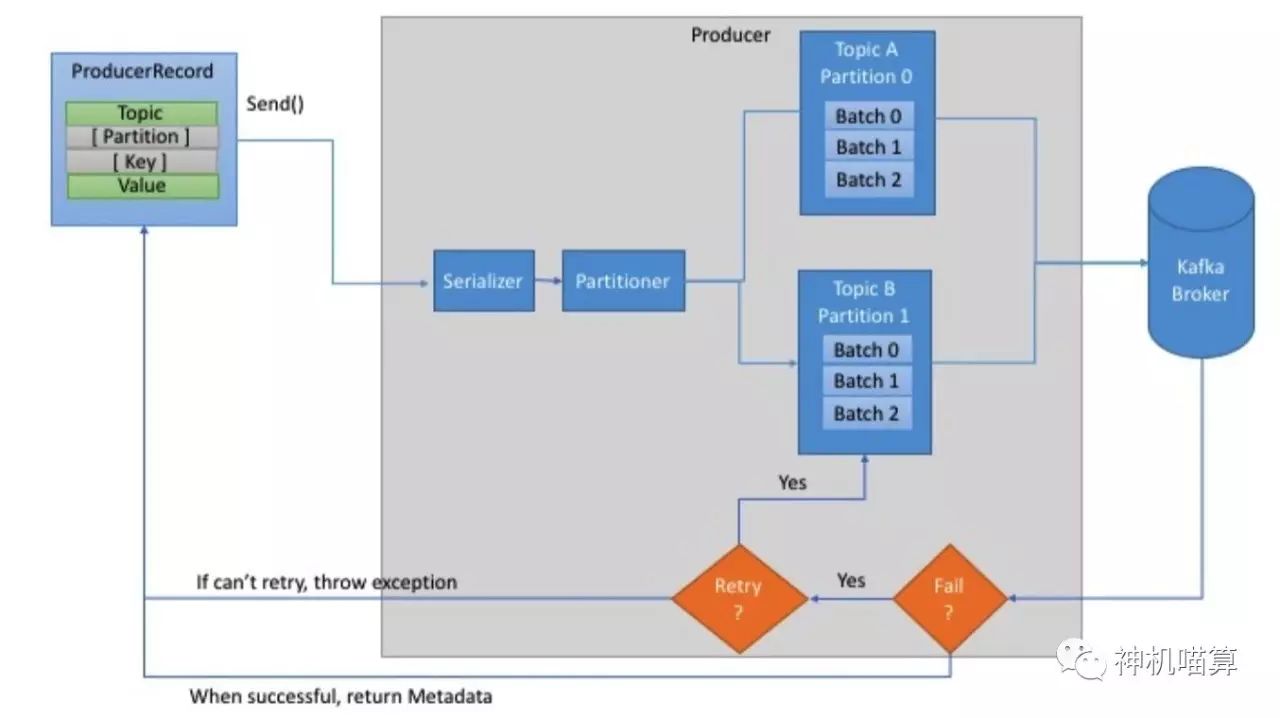
Kafka Producer
首先,创建ProducerRecord必须包含Topic和Value,key和partition可选。然后,序列化key和value对象为ByteArray,并发送到网络。
接下来,消息发送到partitioner。如果创建ProducerRecord时指定了partition,此时partitioner啥也不用做,简单的返回指定的partition即可。如果未指定partition,partitioner会基于ProducerRecord的key生成partition。producer选择好partition后,增加record到对应topic和partition的batch record。最后,专有线程负责发送batch record到合适的Kafka broker。
当broker收到消息时,它会返回一个应答(response)。如果消息成功写入Kafka,broker将返回RecordMetadata对象(包含topic,partition和offset);相反,broker将返回error。这时producer收到error会尝试重试发送消息几次,直到producer返回error。
Producer实战
构造Kafka Producer
创建Properties对象,配置producer参数。根据Properties创建producer对象。Kafka producer必选参数有3个:
bootstrap.servers :Kafka broker的列表,包含host和port。此处不必包含Kafka集群所有的broker,因为producer会通过其它broker查询到所需信息。但至少包含2个broker;
key.serializer:序列化key参数,值为类名,org.apache.kafka.common.serialization.Serializer接口的实现;
value.serializer:序列化value参数,值为类名,使用方式同key.serializer。
最简代码实现如下:
private Properties kafkaProps = new Properties();kafkaProps.put("bootstrap.servers", "broker1:9092,broker2:9092");kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.String-Serializer");kafkaProps.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer");producer = new KafkaProducer<String, String>(kafkaProps);
创建Properties对象,key和value为String类型,选用Kafka自带的StringSerializer。通过属性配置可以控制Producer的行为。
实例化producer后,接着发送消息。这里主要有3种发送消息的方法:
立即发送:只管发送消息到server端,不care消息是否成功发送。大部分情况下,这种发送方式会成功,因为Kafka自身具有高可用性,producer会自动重试;但有时也会丢失消息;
同步发送:通过send()方法发送消息,并返回Future对象。get()方法会等待Future对象,看send()方法是否成功;
异步发送:通过带有回调函数的send()方法发送消息,当producer收到Kafka broker的response会触发回调函数
以上所有情况,一定要时刻考虑发送消息可能会失败,想清楚如何去处理异常。
通常我们是一个producer起一个线程开始发送消息。为了优化producer的性能,一般会有下面几种方式:单个producer起多个线程发送消息;使用多个producer。
下面开始详细展示上面所提到的三种发送消息的方法,以及各种类型错误的处理方式。
发送消息到Kafka
最简单的方法如下:
ProducerRecord<String, String> record =new ProducerRecord<>("CustomerCountry", "Precision Products","France");try {producer.send(record);} catch (Exception e) {e.printStackTrace();}
创建ProducerRecord对象,Producer使用send()方法发送ProducerRecord。send()方法会返回带有RecordMetadata的Future对象,这里只简单的忽略返回值,所以我们并不会知道消息是否发送成功;
但即使如此简单,Producer发送消息到Kafka也仍然得处理些异常:当序列化消息失败会抛出SerializationException;buffer溢出会抛出BufferExhaustedException;当发送线程终止会抛出InterruptException。
同步发消息
ProducerRecord<String, String> record =new ProducerRecord<>("CustomerCountry", "Precision Products", "France");producer.send(record).get();
这里,我们使用Future.get()方法等待Kafka的状态返回。Producer可以实现自己的Future来处理Kafka broker返回的异常。如果Producer发送消息成功,它会返回RecordMetadata对象(可用来检索消息的offset)。
Kafka Producer一般有两类错误。可重试错误会通过重试发送消息解决。比如,连接重连可解决连接错误;partition重新选举leader可解决“no leader”错误。Kafka Producer能配置重试次数,超过重试次数还不能解决的会抛出错误。另外一类就是不能通过重试处理的错误,比如,消息大小太大,这种情况下Kafka Producer会立即报错。
异步发送消息
如果应用和Kafka集群间的网络质量太差,那么同步发送消息的方式发送每条消息后需要等待较长时间才收到应答。这对高并发海量消息发送简直就是灾难,因为等待应答的时间远超过消息发送时间。另外,有些app压根就不要求返回值。况且,即使发送消息失败了,只要写下对应的错误日志即可。
为了异步发送消息,同时可以处理错误。Producer支持带有回调函数的发送消息方法。
private class DemoProducerCallback implements Callback {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e != null) {e.printStackTrace();}} }ProducerRecord<String, String> record =new ProducerRecord<>("CustomerCountry", "Biomedical Materials", "USA");producer.send(record, new DemoProducerCallback());
使用回调函数的前提是实现org.apache.kafka.clients.producer.Callback 接口。如果Kafka返回错误,onCompletion捕获到非null异常。示例代码仅仅打印出了异常信息,实际应用开发需根据实际情况添加业务逻辑处理。
未完待续。。。
Enjoy!
侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny分享相关技术文章。
若发现以上文章有任何不妥,请联系我。

