





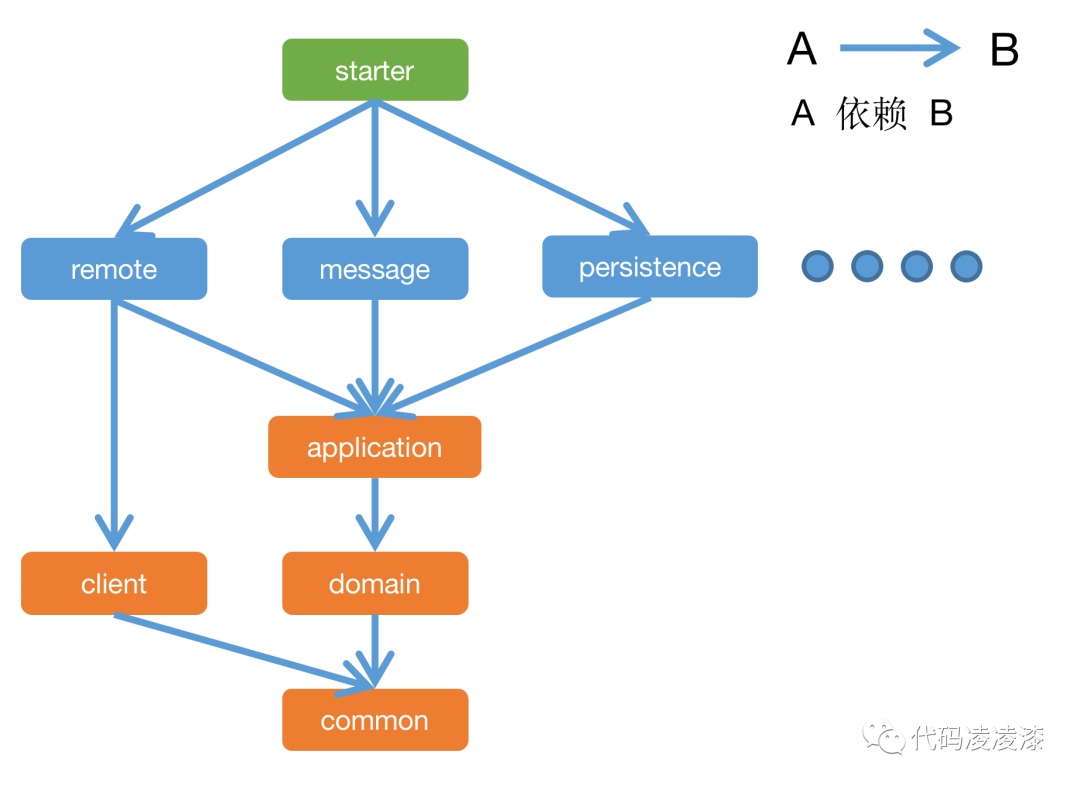
核心业务逻辑由领域模型负责实现,而一些复杂查询逻辑则是绕过领域模型直接访问数据库,这样就省去了持久化模型到领域模型再到 DTO 模型的复杂转换过程。所以,我们按照这样的思想对上期(聊聊 DDD)讲到的模块依赖做如下转换:
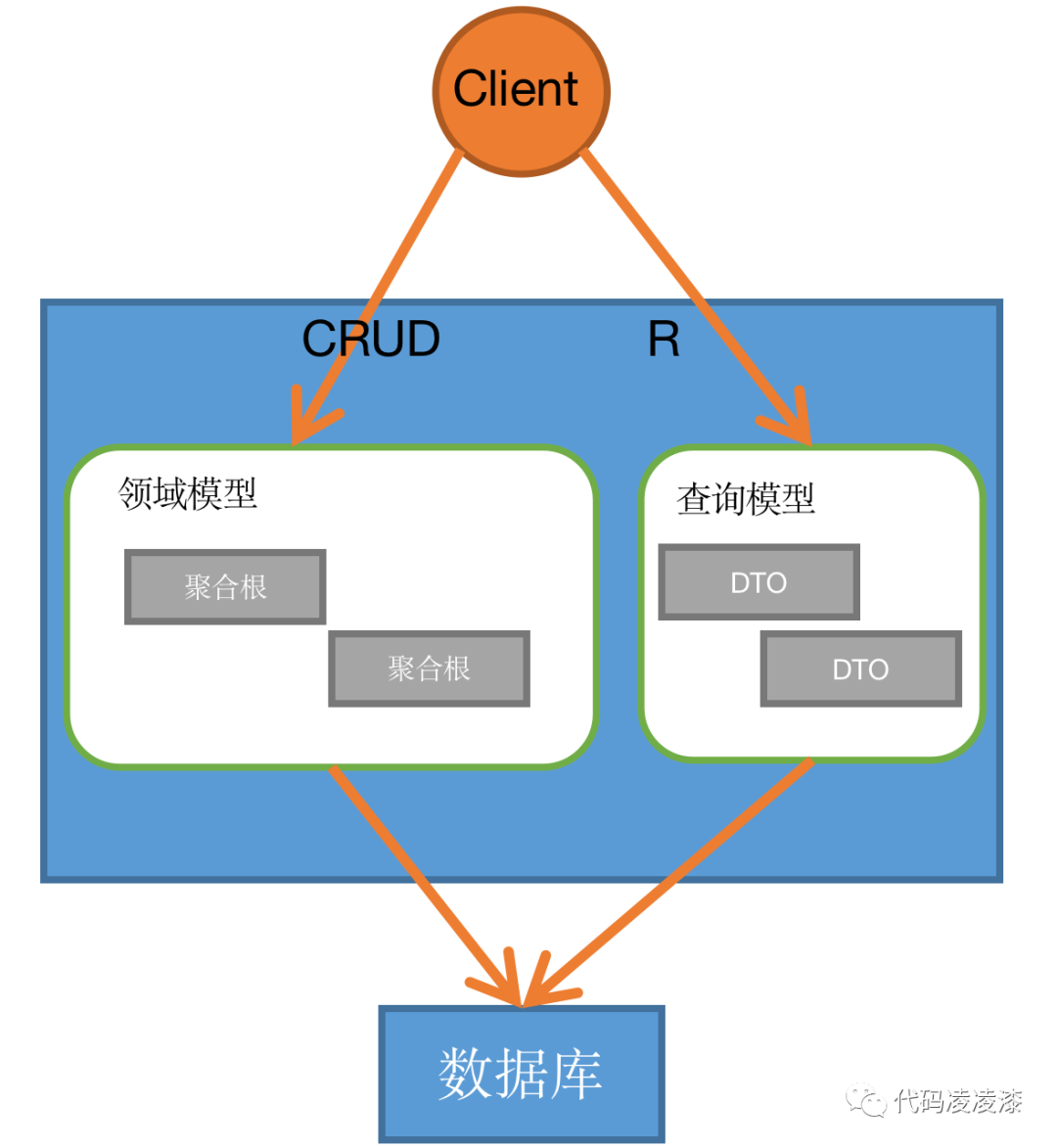
这种仅在代码层面的读写分离模式并不能体现 CQRS 的真正作用,许多企业级的应用程序会将读写模型分开,分别对接不同的数据库。
将写模型对接关系型数据库,充分发挥关系型数据库的事务功能,保障写业务在并发状态下的数据一致性。而将读业务模型对接文本搜索数据库(如Elasticsearch 或 Solr),充分发挥此类数据库的搜索功能,提升查询效率。系统架构模式如下图所示:
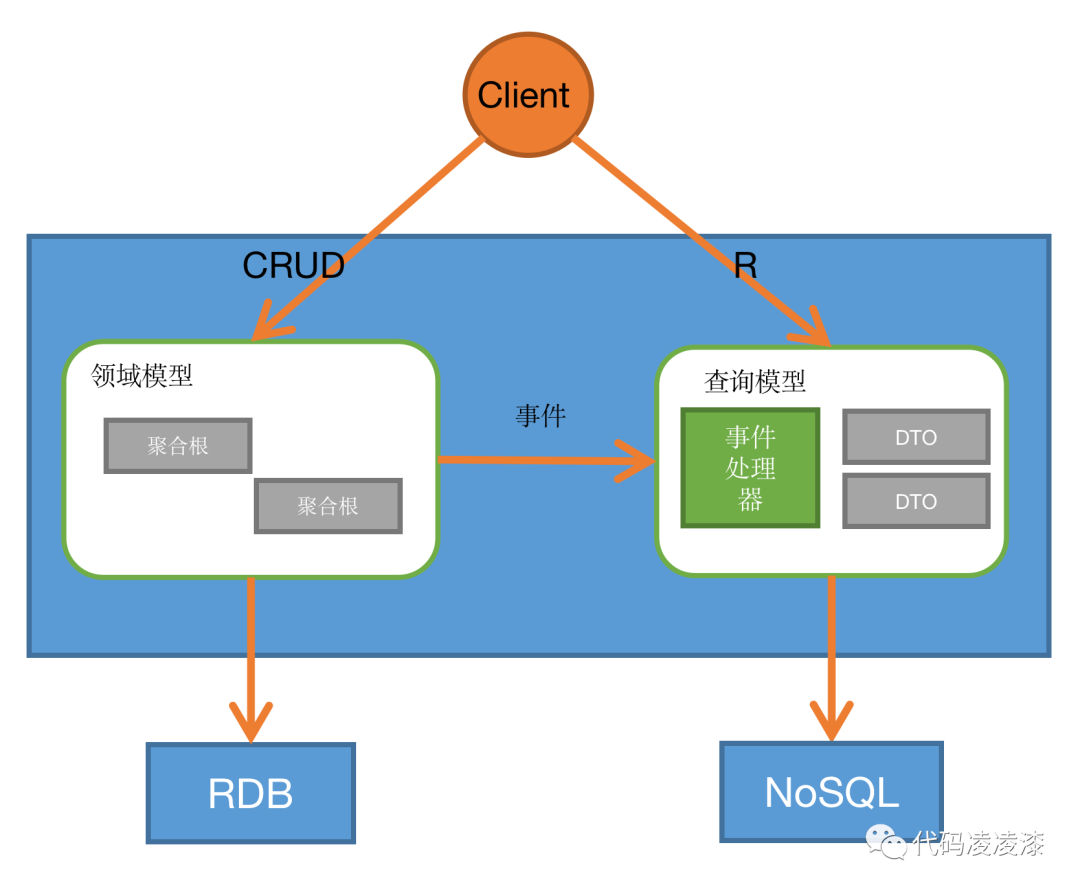
写业务模型接受客户端请求,向关系型数据库写入数据,同时发送数据变化事件,查询模型监听事件,将数据变化写入到NoSQL数据库。
CQRS 模式下,读数据库相当于写数据库的数据副本,而如何保证副本数据库与原数据库之间的数据一致性,这是 CQRS 模式要解决的核心问题。
一种常见的解决方案,就是通过消息的方式保障数据一致性。写模型在数据成功落库后,将数据更新事件封装成消息,发送至数据同步 topic。读模型监听数据同步 topic,收到消息后对副本数据进行更新。最终,两边的数据能够保证最终一致性。
消息的方式使用起来非常简单,但其中要注意很多问题。
首先,我们要注意保证消息消费的顺序性。通常的解决方案是,消息发送端将具有业务唯一标识 ID 的消息发送至同一队列,而消息消费端则采用顺序消费的方式,开启与队列相同数量的消费线程,一个消费线程顺序消费一个队列的消息。
RocketMQ 是天然支持顺序消费的消息中间件,但有些主流消息中间件是不支持顺序消费的,例如 Kafka。那如何整合 Kafka 实现顺序消费呢?要么手动实现一套类似于 RocketMQ 的顺序消费机制,要么消息发送端发送的消息只包含业务唯一标识 ID,消费端在收到消息后,根据业务唯一标识 ID 主动调用写模型接口查询最新数据,然后同步至副本数据库。后一种方式虽然简单、高效、可靠,但也对写模型造成了一定的接口压力以及数据库压力。
其次,我们要注意保证消息消费的幂等性。通常的解决方案是,在消息体内增加唯一性标识 ID,消息消费端额外设置消息数据库,消息消费前先根据消息唯一性标识 ID 查询数据库中是否存在该消息,如果不存在才进行消费,消费成功后再将消息落库。此外,还要针对消息消费逻辑加分布式锁,防止出现消息还未落库,系统又消费到了重复消息的情况。
最后,还需要建立必要的对账体系。即使我们采用上述方案保证了消息消费的顺序性及幂等性,但仍旧会产生一些特殊情况,造成副本数据与原数据的不一致。为此,我们还需要设定一系列的对账措施,例如凌晨定时对账、提供手动对账接口,保证数据的最终一致。
另一种常见的解决方案,则是采用数据同步中间件来实现数据的一致,例如阿里开源数据同步框架 Canal。Canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议,向MySQL Mater发送 dump 协议,MySQL mater 收到 Canal 发送过来的 dump 请求,开始推送 binary log 给 Canal,然后 Canal 对 binary log 进行业务解析,最终将数据存储到 MySQL、Kafka、Elasticsearch 等数据库中。
提到 CQRS,就不得不提近些年逐渐流行的 Event Sourcing 概念。
Event Sourcing,即事件溯源,是Martin Fowler提出的一种架构模式。事件,可以理解为外界对系统产生影响的起因,例如针对一个订单而言,用户的下单、付款、退订、加购等动作都会造成订单数据的变化,这些动作都是造成一条订单数据变化的 “事件”。
事件是造成系统数据变化的 “因”。通常,我们的系统在运行时计算这些事件,将这些事件对数据的影响进行持久化,因此,我们的业务数据库关注的是事件造成的 “果”,记录的是数据最新、最终的状态。
而事件溯源模式下,我们的业务数据库关注的是 “因”,直接存储每个事件。在读取数据时,系统再将事件从业务数据库拉出来,实时计算得出当前数据的最新状态。
举个银行转账的例子。假设银行账户管理系统包含 “账户” 实体,该实体包含的属性有 “账户ID”、“账户余额”,包含的方法有 “转入”、“转出”。某 ID 为 “9527” 的账户初始金额为 0,针对该账户发生了以下事件:
1、转入 200 元;
2、取出 100 元;
3、 转入 300 元。
写模型直接对这三个事件进行持久化,同时将这三个事件通知到读模型,读模型的事件处理器进行运算,将最终的计算结果进行持久化。最终,读写模型各自存储的业务数据如下图所示:
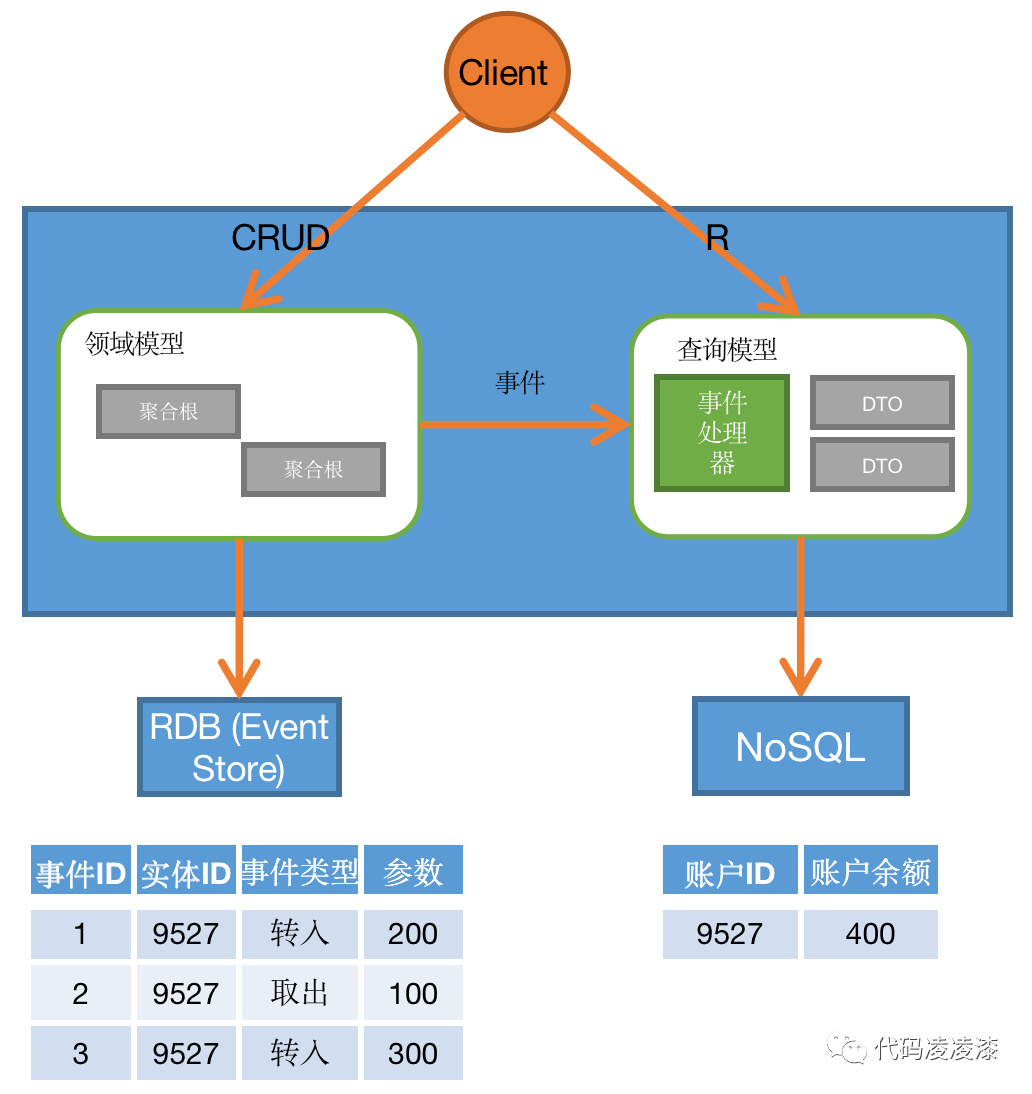
一个事件必须要包含实体 ID、事件类型、事件参数以及事件顺序等信息,以方便事件处理器针对一个实体的事件列表进行回放,计算出该实体的最新状态。
事件处理器具有实体数据的回放功能,其逻辑一般由写模块进行定义,以二方包的形式被读模块或者其他业务模块集成。
写模块的业务逻辑不仅仅包含数据的写入,写入过程中也需要查询实体的最新状态,以做业务判断,例如账户转出金额的过程中,需要检查账户余额够不够转出这些金额,余额不足则要拒绝转出。而随着时间的推移,一个实体对应的事件数据越来越多,不可能在运行时将所有事件都从数据库拖出来进行回放。
针对这个问题,一般都解决方案是在写模型的业务数据库里创建实体的状态数据表,定时扫描每个实体的事件数据,回放出最新状态存储到实体状态数据表,同时软删除已回放过的事件数据。这样,写模型在读取数据时,可以基于实体状态数据的水位进行数据回放,提高了效率。
1、转变思路。Event Sourcing的落地需要在设计时就用领域驱动的方式开展,需要有基于事件的响应式编程思维。这种方式需要以领域模型设计优先,而不是传统的数据库设计优先;
2、事件历史包袱重,变更事件结构困难。随着业务流程的变化需要不断调整事件结构,对事件添加或者修改一些数据。这种行为会影响到 “历史重现”,需要考虑兼容之前的事件结构;
3、要保证事件的幂等性。如果对应的事务在执行过程中被中断,需要通过事件回放的方式达到事务的最终一致性问题。此时需要对事件的幂等性提出要求,也就是同一个事件运行多次得到的结果不变,需要在事件处理时丢弃重复事件。
