





https://www.biduo.cc/biquge/40_40847/




https://www.biduo.cc/biquge/40_40847/
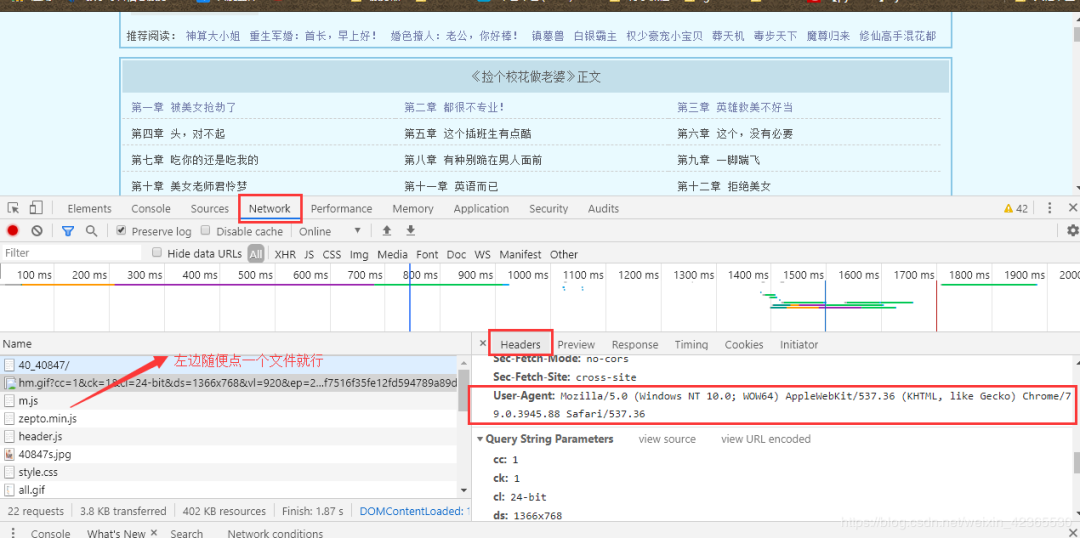
拿到所有HTML数据后,利用正则库结合XPath语法(可以自己去学一下XPath 教程:)
https://www.w3school.com.cn/xpath/index.asp
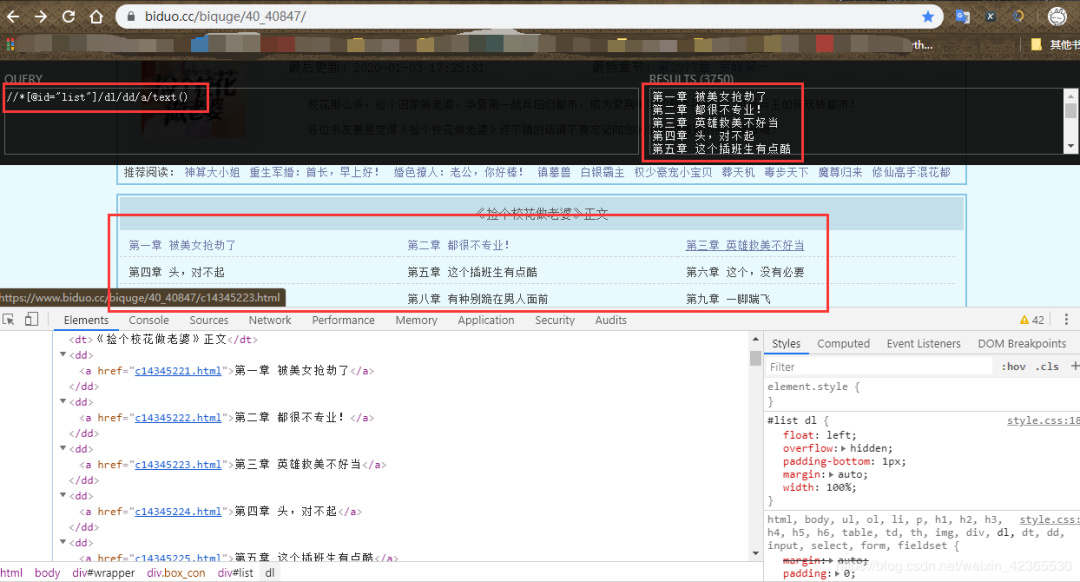
//*[@id="list"]/dl/dd/a/text()//*[@id="list"]/dl/dd/a/@href
通过上面两个XPath语法,即可拿到我们需要的章节名称和对应的链接地址(PS:这里浏览器中的黑框小工具,是谷歌浏览器的一个扩展程序Xpath Help,需要这个扩展程序的小伙伴,可在我公众号回复 扩展程序 获取)


https://www.biduo.cc/biquge/40_40847/
Python
# 2. 请求文章拿到HTML数据,抽取文章内容并保存response = requests.get(url + src,headers=headers)
Python
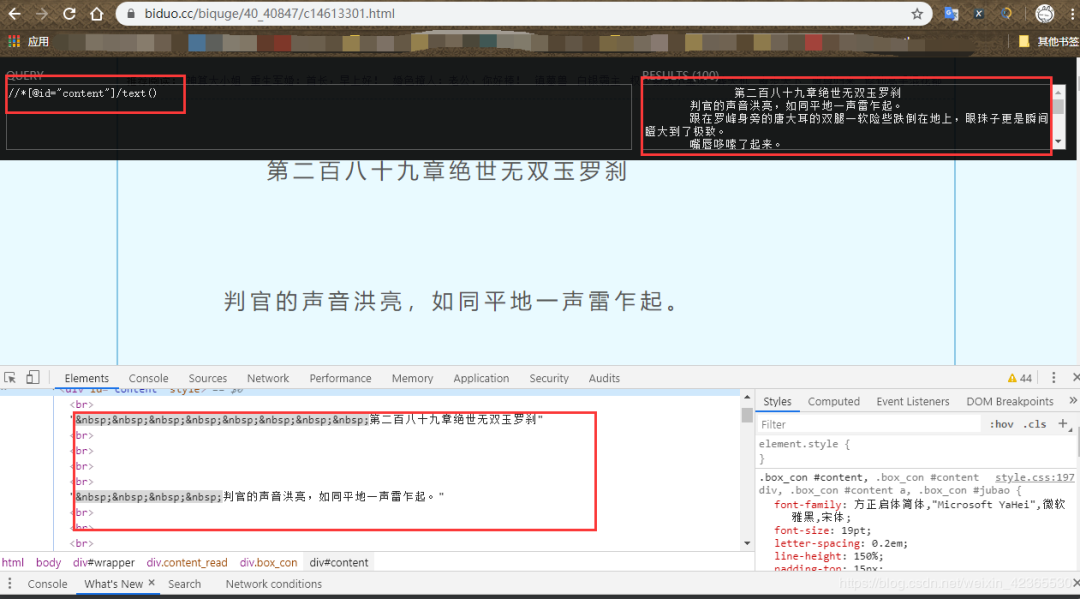
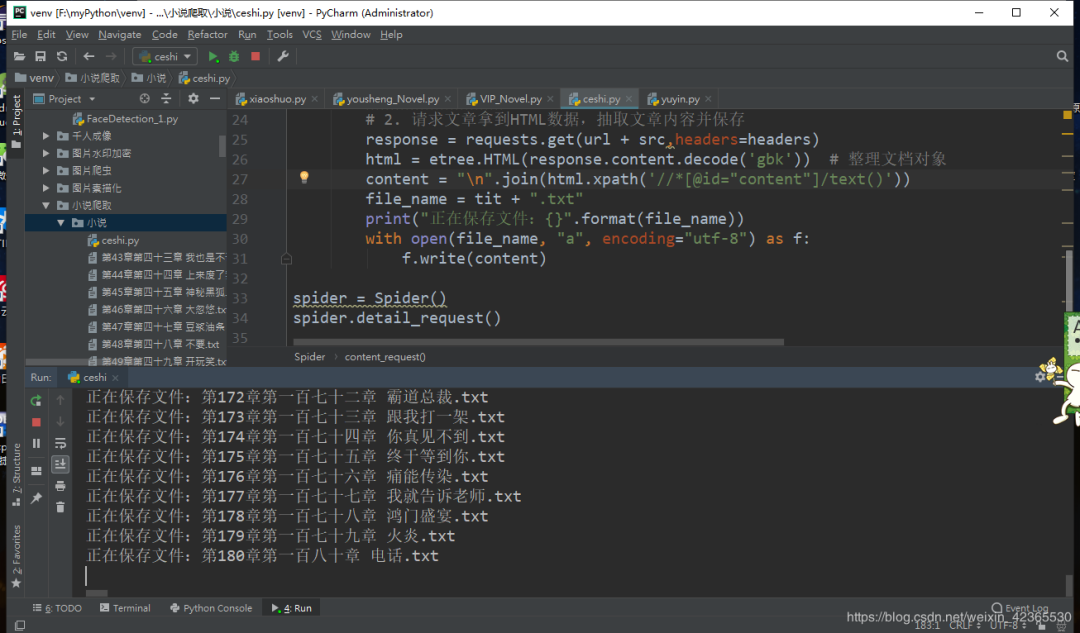
# 2. 请求文章拿到HTML数据,抽取文章内容并保存response = requests.get(url + src,headers=headers)html = etree.HTML(response.content.decode('gbk')) # 整理文档对象content = "\n".join(html.xpath('//*[@id="content"]/text()'))file_name = tit + ".txt"print("正在保存文件:{}".format(file_name))with open(file_name, "a", encoding="utf-8") as f:f.write(content)

CSDN:与世间美好环环相扣
文章转载自遇见0和1,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
