前言
| 设置了文字大小与颜色 |

| 设置了文字大小与颜色 |
获取并筛选数据
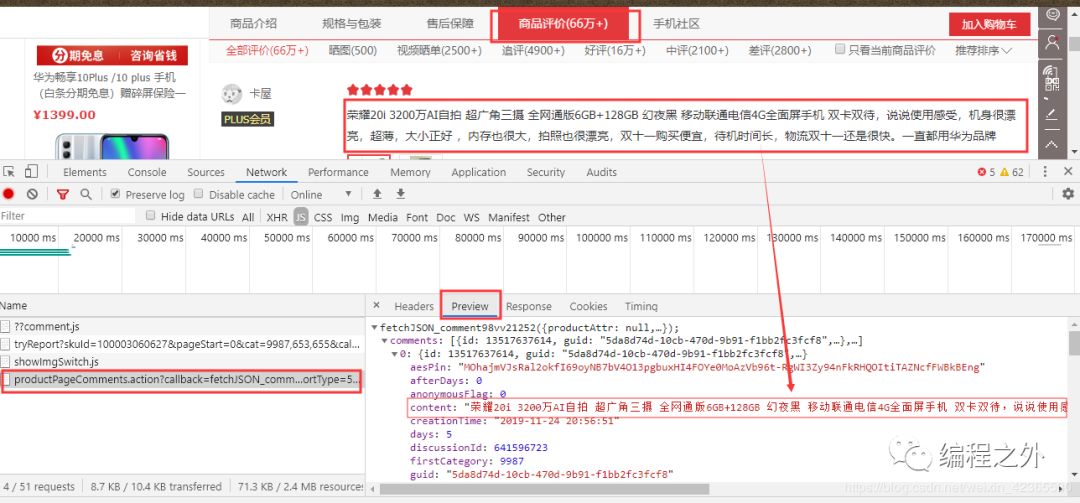
拿到我们需要的url地址和请求头后,先分析一下url地址,主要是它的后半部分,它是由字符串拼接而成的,比如这里的url地址:https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv21252&productId=100003060627&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
在这里page=后面跟的就是第几页评论的信息(数据),不信你点击第二页评论时page=后面就是1&pageSize=10&isShadowSku=0&fold=1,由0变为了1(感觉在侮辱自己的智商(艹皿艹)),由此我们可以将url地址切割为两部分,将变化的数据用变量表示,然后再将两部分拼接得到最终的url地址,我们就可以通过控制变量来获取对应的数据量了,如下为切割和拼接的过程和结果
#切割后第一部分url_header="https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv19450&productId=100003060627&score=0&sortType=5&page="#切割后第二部分url_tail="&pageSize=10&isShadowSku=0&rid=0&fold=1"#拼接得到最终url地址(后面用循环改变page的值,此处加1,即从第二页开始获取数据,也可以不加1)url_mate20=url_header + str(page+1) + url_tail
import requestsimport json
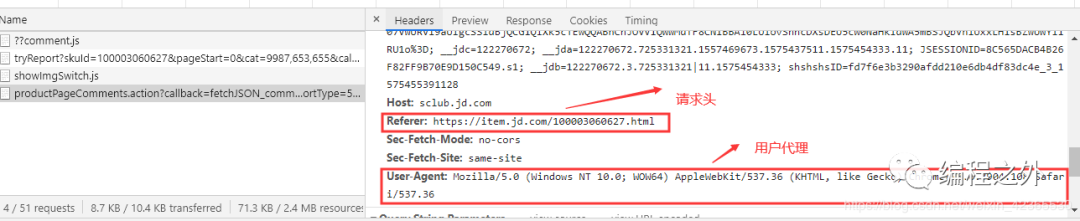
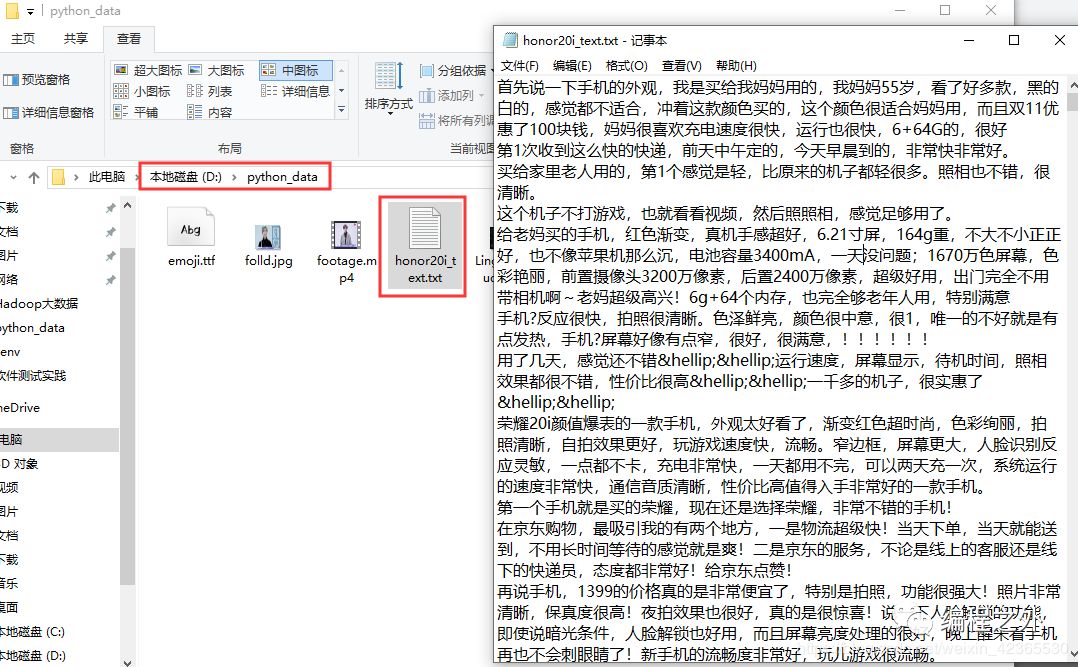
利用请求头和拼接得到的最终url,循环请求每一条评论数据,并将请求到的数据转化格式为json格式保存为本地的txt文件,如下我保存到自己电脑D:\python_data目录下
for page in range(20):url_tail="&pageSize=10&isShadowSku=0&rid=0&fold=1"# 拼接得到最终url,并请求数据(得到键值对格式(字典)的数据)url_mate20=url_header + str(page+1) + url_tailres=requests.get(url_mate20,headers=headers)# 用json.loads将数据转化格式为json格式data=json.loads(res.text[27:-2])comment=(data['comments'])# 将数据遍历保存到本地的.txt文件中,for i in comment:# 注意带参数"a",如果是w就会覆盖原有内容,这样子你只能得一条评论honor20i_text=open('D:\\python_data\\honor20i_text.txt','a')honor20i_text.write('%s\n'%i['content'])honor20i_text.close()
| 设置了文字大小与颜色 |
词云可视化
同样先导包
import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as plt #可视化包
import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as plt #可视化包#读取爬虫保存下载的数据file_text = open('D:\\python_data\\honor20i_text.txt','r').read()#再使用jieba来处理剪切我们爬取文本内容cut_text = jieba.cut(file_text)#继续处理对剪过的文本以空格拼接起来,注意一下这里“”有空格的result = " ".join(cut_text)wc_cloud = WordCloud(font_path='D:\python_data\\pzh.ttf', #字体的路径background_color='black', #背景颜色width=1200,height=600,max_font_size=150, #字体的大小min_font_size=30, #字体的大小max_words=10000)wc_cloud.generate(result)wc_cloud.to_file('D:\\python_data\\LingDucloud.png') #图片保存#图片展示plt.figure('凌度img') #图片显示的名字plt.title('JD_mate20')plt.imshow(wc_cloud)plt.axis('off')plt.show()
font_path='D:\python_data\\pzh.ttf'
如下为运行后的可视化词云效果,字体越大越明显的词汇说明在评论内容中出现的次数就越多,此时在指定的路径目录下也会生成相应的图片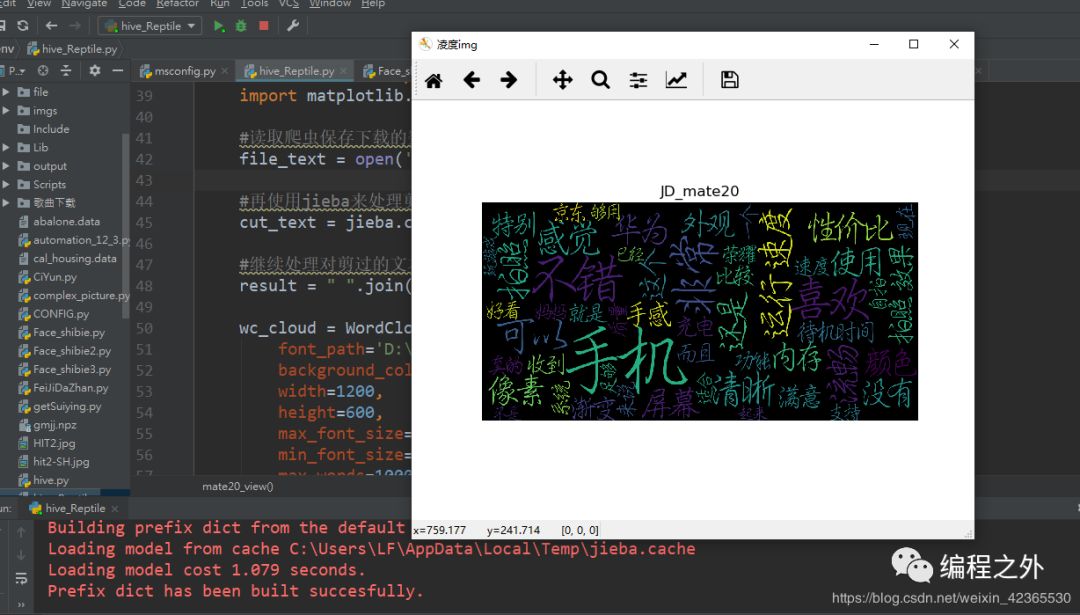
 下面为全部源码,将数据获取和数据可视化分别写成两个方法,在main中分别调用就不用新建两个python文件啦。哪里还不太懂,或者有什么问题欢迎在留言区留下你的脚印哦。
下面为全部源码,将数据获取和数据可视化分别写成两个方法,在main中分别调用就不用新建两个python文件啦。哪里还不太懂,或者有什么问题欢迎在留言区留下你的脚印哦。
import requestsimport json#数据爬取方法def gain_data():#请求头(包括referer:重定向(反爬虫) user-agent:用户代理)headers={'referer':'Referer: https://item.jd.com/100003060627.html','user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ''(KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'}#url地址url_header="https://sclub.jd.com/comment/productPageComments.action?callback=" \"fetchJSON_comment98vv19450&productId=100003060627&score=0&sortType=5&page="for page in range(20):url_tail="&pageSize=10&isShadowSku=0&rid=0&fold=1"# 拼接得到最终url,并请求数据(得到键值对格式(字典)的数据)url_mate20=url_header + str(page+1) + url_tailres=requests.get(url_mate20,headers=headers)# 用json.loads将数据转化格式为json格式data=json.loads(res.text[27:-2])comment=(data['comments'])# 将数据遍历保存到本地的.txt文件中,for i in comment:# 注意带参数"a",如果是w就会覆盖原有内容,这样子你只能得一条评论honor20i_text=open('D:\\python_data\\honor20i_text.txt','a')honor20i_text.write('%s\n'%i['content'])honor20i_text.close()#词云可视化方法def mate20_view():import jiebafrom wordcloud import WordCloudimport matplotlib.pyplot as plt #可视化包#读取爬虫保存下载的数据file_text = open('D:\\python_data\\honor20i_text.txt','r').read()#再使用jieba来处理剪切我们爬取文本内容cut_text = jieba.cut(file_text)#继续处理对剪过的文本以空格拼接起来,注意一下这里“”有空格的result = " ".join(cut_text)wc_cloud = WordCloud(font_path='D:\python_data\\pzh.ttf', #字体包的路径background_color='black', #背景颜色width=1200,height=600,max_font_size=150, #字体的大小min_font_size=30, #字体的大小max_words=10000)wc_cloud.generate(result)wc_cloud.to_file('D:\\python_data\\LingDucloud.png') #图片保存#图片展示plt.figure('凌度img') #图片显示的名字plt.title('JD_mate20')plt.imshow(wc_cloud)plt.axis('off')plt.show()if __name__ == '__main__':mate20_view()
至此,文章到这里就结束啦!
| 设置了文字大小与颜色 |
编程之外
这是一篇很基础的关于python爬虫的文章,大二的时候就学习过Python这方面的知识了,那时候没什么兴趣,就没有好好学┭┮﹏┭┮,现在也是还在自学中,也看了很多大佬的文章,受益匪浅。最后告诉一下小伙伴,如果是计算机类、编程类专业并且要走专业路线的话,一定要好好学习数学,今后的人工智能、大数据、数据建模你将会感受到数学的重要性,说到这里真想给自己两jiao(つД`)过去两年怎么不好好学高数、线性代数、概率论、离散数学和算法,精神上再给自己一jio!
o _______________
/\_ _| |
_\__`[_______________|
] [ \, ][ ][