




本文介绍如何在Flink中配置程序的并发执行。Flink应由多个transform任务(Source、Sink、算子/Operators)组成,一个任务又可以被分成几个并行的实例来执行,每个并行实例处理任务输入数据的一部分;同时也详细探讨下Hive Table Source的并发原理。
并发设置
1.Flink配置文件里的parallelism.default参数,配置全局默认值
2.DataStream API里,可以更详细的在不同粒度设置:
StreamExecutionEnvironment.setParallelism()配置全局默认并发度,会覆盖配置文件里的parallelism.default参数
source、sink、operator上都可以通过setParallelism()设置每个Task的并行度,Task上设置的优先级比Environment上高
3.Table API,可以通过TableConfig对象的table.exec.resource.default-parallelism配置项,为所有算子设置默认并行度,此配置比StreamExecutionEnvironment的并行性具有更高的优先级,实际上会用该配置项覆盖StreamExecutionEnvironment的并行度。使用方式:
tEnv.getConfig().getConfiguration().setInteger(ExecutionConfigOptions.TABLE_EXEC_RESOURCE_DEFAULT_PARALLELISM, 2);
Hive Table Source
在用Hive Table Source时,有一个table.exec.hive.infer-source-parallelism参数,如果为false,则Source的并行度由config设置,如果为true,Flink将根据文件数和每个文件中的block数推断读取hive的最佳并行度,即根据hive表对应的hdfs文件splits number推断。默认是true,我们可以更改默认值:
tEnv.getConfig().getConfiguration().setBoolean(HiveOptions.TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM, false);
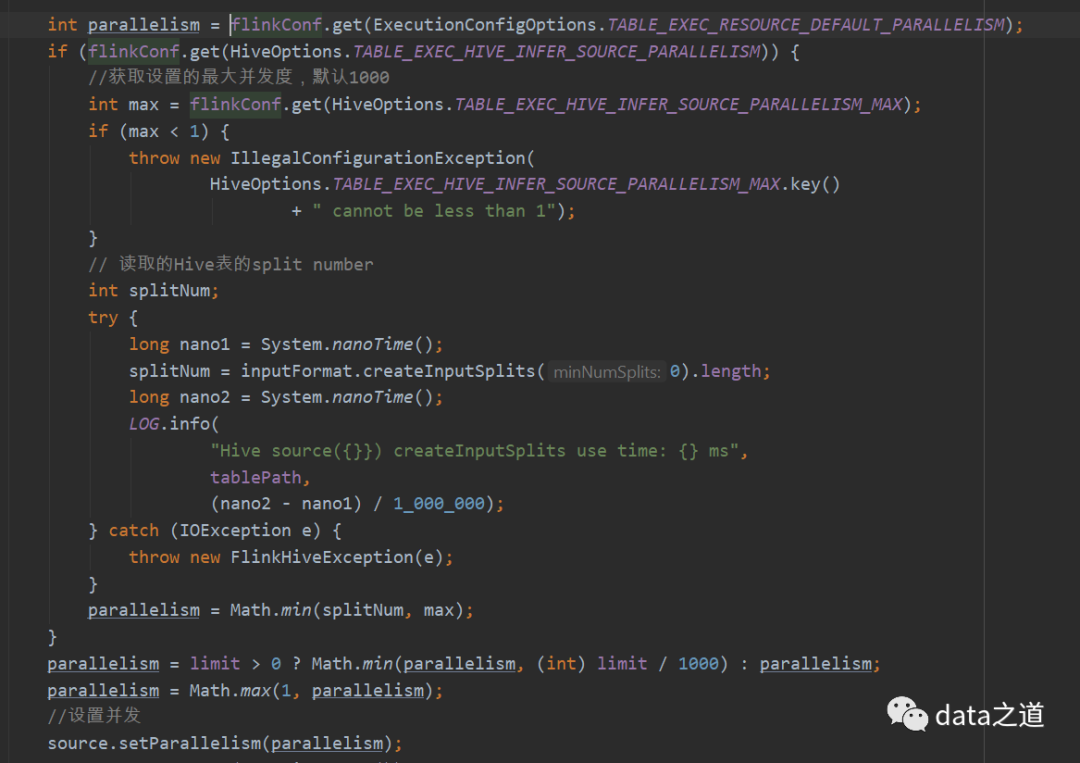
从Hive MetaStore获取表的分区,如果不是分区表,当成一个分区 遍历每个分区下面的文件,获取每个文件的splits 汇总所有splits,得到splits number,作为source table的并发度依据之一
为了避免在自动推断时,并发过度,特别的如果一个表里的文件很多,得到的splits number可能很大,可以用table.exec.hive.infer-source-parallelism.max控制并发上限,默认是1000:
tEnv.getConfig().getConfiguration().setInteger(HiveOptions.TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM_MAX, 50);
小结下就是在用Flink SQL时,有两种方法设置Hive Table Source并发:table.exec.hive.infer-source-parallelism参数或者让程序自动推断,我们不能明确指定每一个table source的并发;当然,可以改下源码,比如在DDL里增加一个parallelism参数,当框架拿到这个参数时,调用sourceStream.setParallelism()方法设置,强制为我们指定的数值。
Hive Table Sink的并发度是和inputstream的并发数保持一致的,现在还不能实现自定义。
