




使用 python 批量移动文件夹下的文件
前言与需求分析
之前用 yolov5 做了一个飞行器的检测,本来 yolo 应该是一个分类器,但是我把它当作一个单个种类的检测器,本来以外我做错了,但是后来我用我的数据跑起来还是效果不错的(单纯指的是识别,精度效果还有待商榷),CSDN 了一番发现国内关于使用 yolo 检测单一种类众说纷纭,所以去 stackflow 去查了一下,就是单纯检测一类做训练是可以的,甚至有专门的攻略,真就 CSDN 是 2 咯?
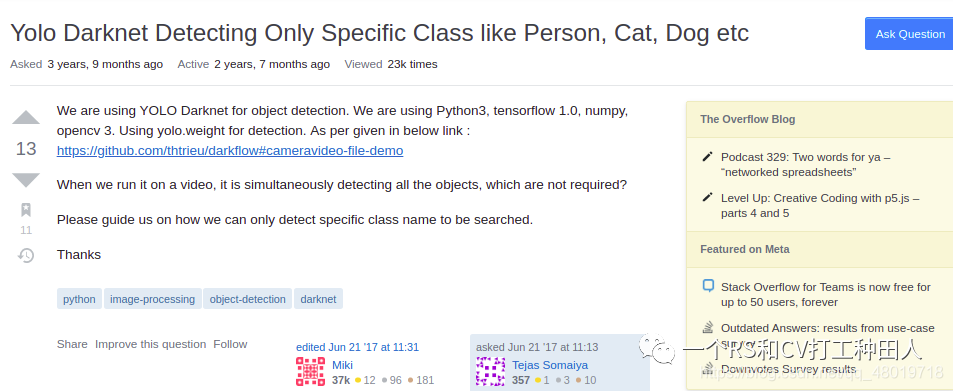
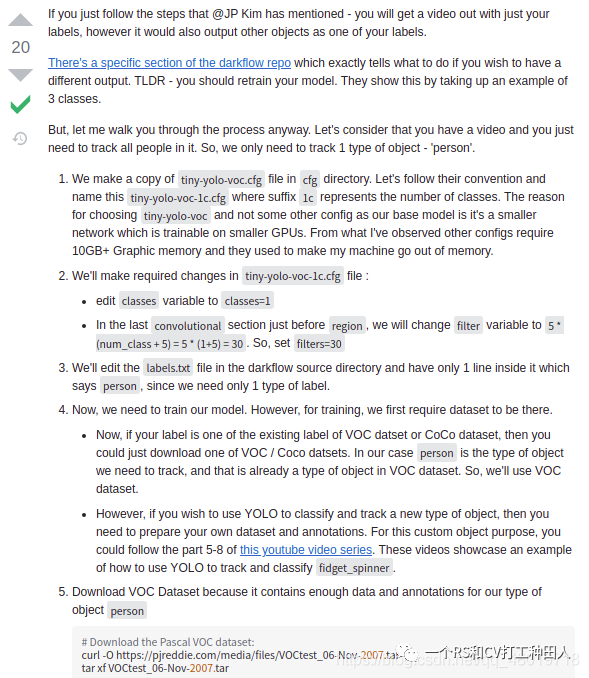
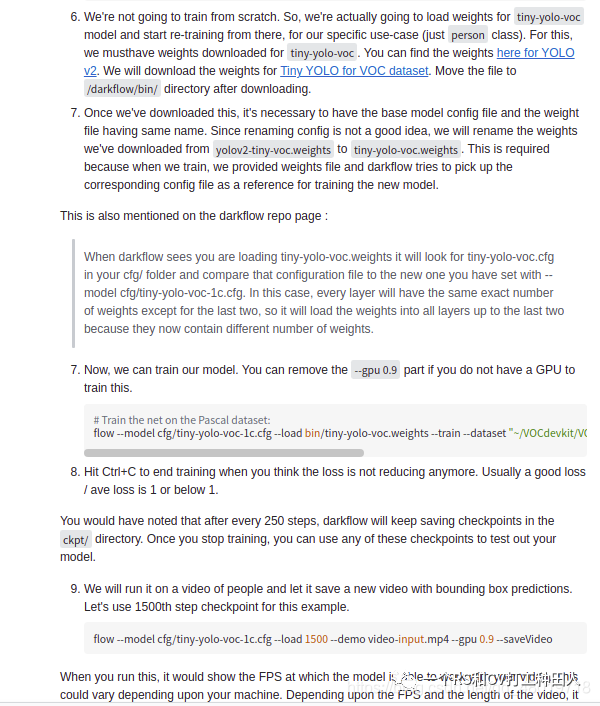

一开始做毕设的设想是 Yolov4,Yolov3做个对比,水一下就划过去了.但是在 B 乎上发现某大神说他用 yolov4 做 DOTA 数据的检测用不了,后来发现他的数据裁剪的大小是 640 x 640 的,而 yolov4 要求 608 x 608 的,而且 Yolov4,Yolov3 不大好配置,而且标签的格式不大一样,恰好昨天和一位群友交流的时候,他用 Retinanet 做了DOTA 的识别,再一查,好家伙,这标注的格式和知乎大神给的数据格式差不多,所以就突发奇想,能不能把我原来 yolov5 的同名 txt 从另一个 Labeltxt 中给拿出来并且处理一下然后批量复制到另一个文件夹中去.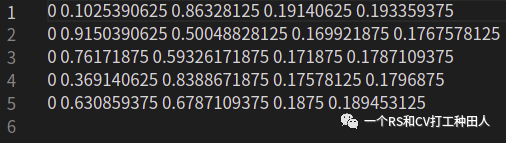
这张图是 yolov5 的标注格式,如果要训练单一种类的话要从 0 开始,并且标签的格式是 class 四个归一化坐标
而 yolov4,Retinanet 分别用的是 image_path,坐标,种类名,种类标签
,image_path,坐标,种类名

这是 Retinanet 的数据格式的介绍,而下面数具体的数据的格式的例子.
由于 DOTA 数据集有原始的标注格式,所以我就想直接把那个复制过来,然后放进来,但是在 yolov5 中,我的仅有飞机的种类是训练数据集有 1823 个 txt 数据,而验证集合有 498 txt 数据,而原始的 DOTA 数据集合中有 10000+ 个 txt 数据,所以我不可能从 DOTA 数据集那里面一个一个对应找到仅包含飞机的 txt 文件. 所以我的需求就是这样的,
/home/neverland/桌面/yolov5/coco/data/train/labels
这个文件夹中有 1823 个 txt 文件. 而我需要在
'/home/neverland/桌面/毕业论文测试/DOTA_split/trainsplit/labelTxt
找到同名的文件夹,并且将它们移动到另外一个文件夹,目标文件夹为
/home/neverland/桌面/毕业论文测试/DOTA_test/trainsplit
之前其实做过一个类似的批量操作,当时的需求是把标签为 2 的文件和它对应同名的 jpg 文件给它移动到另一个文件夹内,主要用的模块就是 os
模块和shutil
模块. 先把总体的代码列出来,如果有类似的需求可以类似的改,至于我弄的飞机的数据集,没什么开源精神了.
# coding = UTF8
# 让标签符合 VOC 格式,将正常的标签与其一样.将有飞机的图片给取出
# Author: Neverland!
# Date:Apr 11th
# version 1.0
import os
import shutil
import os.path
#训练集中的文件
tran_file_dir = '/home/neverland/桌面/yolov5/coco/data/train/labels'
train_file_name = os.listdir(tran_file_dir)
#验证集中的文件
val_file_dir = '/home/neverland/桌面/yolov5/coco/data/val/labels'
val_file_name = os.listdir(val_file_dir)
move_file_dir = '/home/neverland/桌面/毕业论文测试/DOTA_split/trainsplit/labelTxt' #train的文件夹
move_file_dir2 = '/home/neverland/桌面/毕业论文测试/DOTA_split/valsplit/labelTxt' #val 文件夹
dst_trainfile_dir = '/home/neverland/桌面/毕业论文测试/DOTA_test/trainsplit' #train目标文件夹
dst_valfile_dir = '/home/neverland/桌面/毕业论文测试/DOTA_test/valsplit' #val 目标文件夹
for i in range(len(train_file_name)):
files = train_file_name.pop()
#分割路径
pre_name,aft_name = os.path.splitext(files)
#源文件的路径
source_file_name = os.path.join(move_file_dir,files)
#目标文件的路径
dst_file_name = os.path.join(dst_trainfile_dir,files)
shutil.copy(source_file_name,dst_file_name)
print('训练数据的文本文件拷贝成功')
for j in range(len(val_file_name)):
files1 = val_file_name.pop()
#分割路径名
pre_name1,aft_name1 = os.path.split(files1)
#源文件的文件夹
source_file_name1 = os.path.join(move_file_dir2 ,files1)
#目标文件的文件夹
dst_file_name1 = os.path.join(dst_valfile_dir,files1)
shutil.copy(source_file_name1,dst_file_name1)
print('验证数据文本文件拷贝成功')
1.前面几行首先列出的是我的源文件的路径,和它文件夹下的子文件,train_file_name = os.listdir(tran_file_dir)
会返回一个列表,将文件夹下所有的文件的文件名放在列表下,然后我可以用len(train_file_name)
返回一共有几个文件.2.也可以一个一个使用 pop 将它们拿出来,也就是我下面所做的事情,一个一个 pop (提取)出来.3.然后继续进行操作.即,首先我将它的文件名分为前缀和后缀,使用os.path.split
将文件名给分为前缀和后缀,但是需要注意的是,由于操作系统在处理的时候并不会自动给它作为绝对路径,那么,我就需要加目录和文件名给合并起来,即os.path.join(dir,filename)
才能让操作系统找到文件,否则系统会报错,并且很可能会将你的文件给操作没了,由于是自己写的很熟悉,并且每次都会 os.path.exists()
检查一下路径是否存在,所以就没用 try catch
语法.4.当找到了文件之后,我就可以使用 shutil
将其拷贝过去.
在这里稍微解释一下绝对路径和相对路径,所谓的绝对路径就是文件夹所在位置加文件名,而相对路径一般只要文件名,比如下面的两个例子.
/home/neverland/桌面/yolov5/coco/data/val/labels/read.md #绝对路径
read.md #相对路径
对于 mac 和 Linux
系统而言,一般在文件夹所在的位置打开终端之后,在终端输入 pwd
命令,会将你所在的位置告诉你,即所谓的文件夹的路径,这时候,你所在的目录就是文件夹的路径名,后续可以操作该文件夹下的所有文件而不需要加入文件夹的路径,如下图所示:
当然,一般写代码的时候你可以使用打开文件夹的功能,然后就会在所在的文件夹下,例如:
这时候你就可以直接操作文件名了,我一般写博客的时候会切过去,然后在CSDN 上传,然后再用富文本工具转过去再复制到微信公众号里面.这个代码还是相对比较简单的,回顾一下就主要是拿出文件名,然后再 copy 一下,对于做深度学习的人来说,很多时候数据量是 10k+起步的,所以你不可能一个一个命名或者各种操作过去,这样批量操作会简单很多.
