2-调优步骤:
1 设计调优
2 应用调优 程序员代码
3 内存
4 连接
5 操作系统
2-已有产品的调优
1 定位问题
2 查看操作系统和oracle统计
3 考虑通用系统错误
4 假定问题
5 通过参数修改去调优
3调优方法
1 检查日志和trace file
2 检查参数文件
3 检查 内存 cpu
4 那些sql占用cpu和io
如果相应时间慢;
1分析工作实现和相应时间
2 检查那部分时间长
3 细化问题
3 查看alert log
1 查看位置
Show parameter dump
Name 是 backgroup_dump_dest 所对应的目录是alert log所在的目录
2 检查文件
1 检查 错误是 ORA 的错误和快损坏错误
2 分析这个文件
3 定期移动和清空错误文件
清空文件: cat /dev/null >文件名
改变系统值
Alter system set 参数名=参数值 scope= both 或 spfile
Both 代表同时改变内存和文件
4 查看user trace file(用户操作日志文件)
Show parameter dump
Name 是 user_dump_dest 所对应的目录是user trace file所在的目录
产生trace文件的方法:
1 修改自己的session:alter session set sql _trace=true
2 使用sys用户登录,调用存储过程:将某个用户的session 产生trace文件

3 sql_trace系统参数确定系统中的所有用户产生日志
5-dba的视图
dba_tables,dba_tab_colums,dba_indexes,index_stats
5 重要的动态视图
系统相关视图
V$sysstat 系统统计
V$sgastat SGA统计
V$system_event 系统事件 事件名 v$event_name

session 相关的视图

v$sesstat session统计数据
v$sesstat_event
6 重要视图


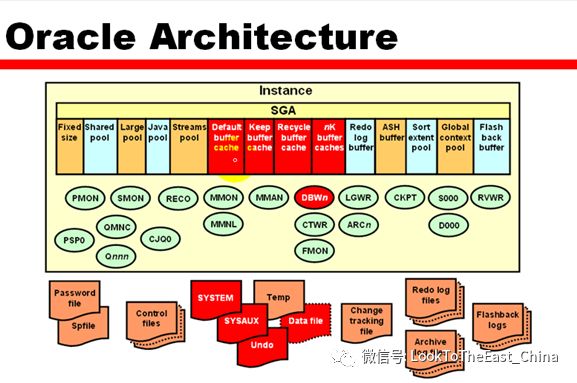
数据库设计
1 不同用途的数据放在不同的tablespace避免资源争用
2 不同的tablespace放在不同的物理驱动器调高I/O并发能力
3 日志文件放在速度快的磁盘上,数据文件可以放在速度慢的磁盘上
4 日志文件的同组中不同成员放在不同的物理磁盘
7通过物理文件的读写次数来调优
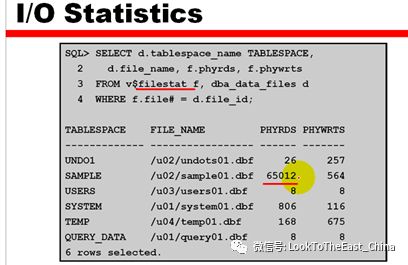
Select d.tablespace_name,d.file_name,f.phyrds,f.phywrts from v$filestat f,dba_data_files d where f.file#=d.file_id;
可以通过设置Oracle读写块的大小提高I/O效率
参数如下:
DB_FILE_MULTIBLOCK_READ_COUNT
8 striping(均匀分布数据)
1 操作系统或文件系统支持striping
2 建表或更改表时使用 allocate 可以达到striping的目的
8 DB_FILE_MULTIBLOCK_READ_COUNT
可以通过设置Oracle读写块的大小提高I/O效率
8 大于6秒的操作查询
V$session_longops
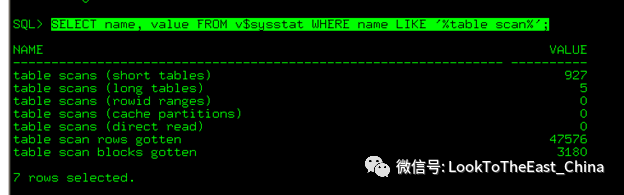
Select name,value from v$sysstat where nane like ‘ %table scan%’
8 监控全表扫描

3监控大表运行情况
大于6秒的全表扫描记录在
v$session_longops
查看全表扫描的记录条数
Show parameter log_ch
9 Oracle启动时间
通过调整 FAST_START_MTTR_TARGET保证Oracle启动时间,Oracle可以根据这个参数调整其他参数

9重做日志文件
如果没有足够重做日志文件,就会造成系统阻塞,
解决办法:
1 加大重做日志文件
2 增加归档进程
设置参数:LOG_ARCHIVE_MAX_PROCESSES
在alert log中出现如下错误说明日志文件已经写满

通过:
V$log_file
V$log
提高sql命中
11查询系统hard parse的次数

V$sysstat 表中的 parse count (hard)是解析sql条数
11 提高sql相似sql在共享池中的命中率

12 使用绑定变量提高共享sql
使用preparedStatement
13 查看共享池信息

13查看v$sgastat中的free memory决定是否要扩大共享内存
13 查看执行少于5次的sql通过查看解析次数与执行次数找到效率低的原因
select sql_text from v$sqlarea where executions<5 order by upper(sql_text)
13 查看sql查看解析次数与执行次数找到效率低的原因
select sql_text, parse_calls,executions from v$sqlarea
14 存储过程的调用着是过程的属主,不是调用者
14 在sql中添加表的用户可以减少访问数据字典的次数
14 在业务高发期使用ddl语句会降低sql的命中,因为sql需要重新解析
14 在业务高发期V$librarycache 中的reloads和invalidations要尽可能小,如果reloads太大说明shared pool太小
14 查看sql命中率:
Select gethitratio from v$librarycache where namespace=’SQL AREA’
调整shared pool
14查看那些sql正在执行:
Select sql_text,users_executing from v$sqlarea
15 查看v$share_pool_advice由Oracle提供共享池优化参数
16 使用下面的sql 估算共享内存
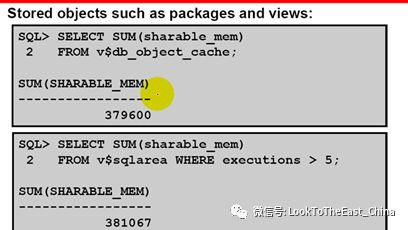
将以上两项值相加基本就是估算的librarycache 的内存大小
查看共享池信息
Show parameter shared
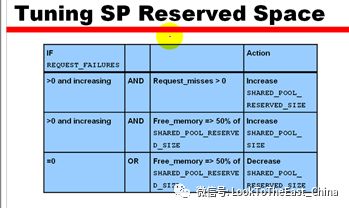
16 设置保留池的大小,以满足大对象和临时对象的使用
Shared_pool_reserved_size

Request_failures持续太大说明保留池太小
需要加大保留池和共享池
16调整共享池大小
Shared_pool_size
不能最大值取决于操作系统的内存
不能太小
17 在共享区,一直保留在内存区,不参与内存淘汰算法

清除shared pool
Alter system flush shared_pool
18 查询匿名块
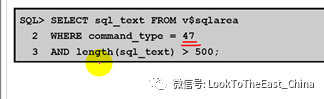
18 调整Data Dictionary cache
通过v$rowcache
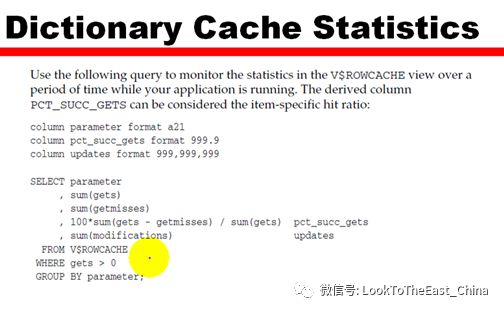
调整共享池来调整DD cache
11 large pool

Large_pool_size
Show parameter size
19Buffer cache 调优

1 降低sql读入buffer数据
2 增大buffer cache
3
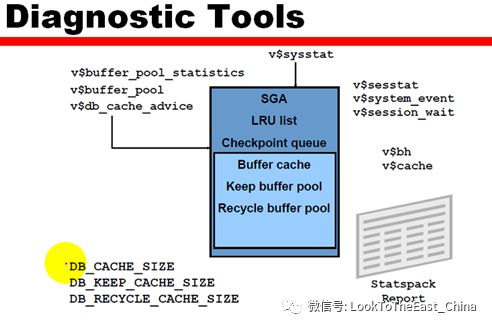
Free buffer inspected :找到空闲块之前做的消耗
Free buffer waits 没有可用的空闲块
Buffer busy waits 块被占用
21 查询等待的事件及等待块信息
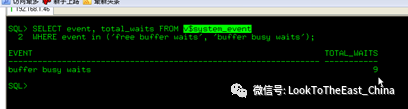

21 计算命中率

1 大表多次扫描会降低命中率
2 好的命中率:命中率高,坏事件少
3 将常用的数据放在中间件层,减轻数据库压力
Cache使用
23增大cache_size
增大cache之前
1 没有3中事件
2 优化了sql
3 防止操作系统将sga放到os的交换区
4 命中率低
使用
增加db_cache_size
增加时这个只不能大于sqa_size
23 Oracle 9i 有三中pool
Reclye pool
Keep pool
Default pool
三个buffer pool大小不一样,算法一样,可以利用这一特性决定吧对象放在那个pool里
使用办法:
1 热块放在 default pool
2 温块放在 keep pool
3 冷快放在 recycle pool
23放对象放在pool中的语法:

24查看对象使用的块


24计算命pool中率:


24创建cache 表
方法一:创建表时

方法2:修改普通表到cache 表
方法3:查询后放在cache表

25自动管理内存
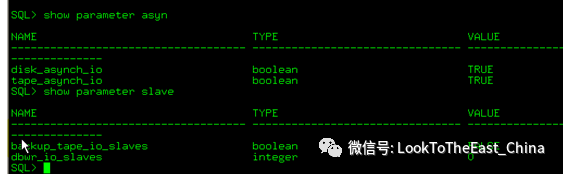
25配置多个DBWn
Alter system db_writer_precesses //操作系统必须支持异步I/O,多cpu使用
1 开启异步I/O
2 在不支持异步I/O的情况下,修改dbwr_io_slaves数量也可以达到增加DBWn的效果
27LGWR是使性能下将

Redo Entries 存在的记录数:
Redo buffer allocation retries: 申请redo buffer 的次数,此值过大说明 redo buffer 太小
28当发生下列事件时会引起性能下降
1 日志文件交换

增大redo log files
2 检查点未完成

解决办法:
a设置Fast_start_mttr_target越小增加checkPoint的次数
b 增加redo log 组和成员
3 归档引起

解决办法:
1 增加redo log 组和成员
2 archive文件太多,没地方写归档文件,可以删除文件
3 增加归档进程 log_archive_max_proceses
28加速数据插入的时间:
使用无log方式,批量插入数据
共享服务器


优化排序
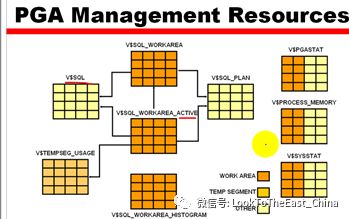
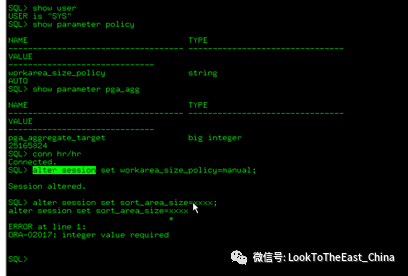
32优化排序-自动管理PGA
设置自动管理PGA:work_size_policy = auto
在自动管理PAG模式下设置PAG大小:pga_aggregate_target

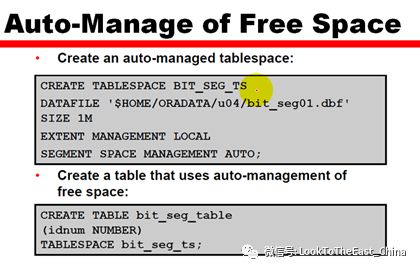
32设置PGA建议:

32设置PGA的例子

32 oracle的内存设置:
Oracle的内存由SGA和PGA 之和 决定

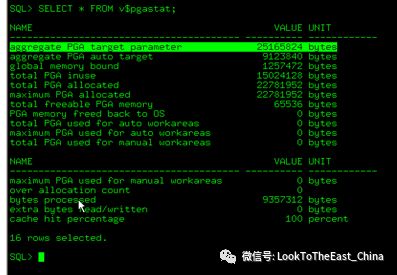
Over allocation count增大说明 aggregate pga target 太小
34 查询建议的PGA内存

Select round(pga_target_for_estimate/1024/1024) as target_mb,round(BYTES_PROCESSED/1024/1024) as process_mb,ESTD_PGA_CACHE_HIT_PERCENTAGE hit_ratio,ESTD_OVERALLOC_COUNT from v$pga_target_advice;
34 查看 sesstat

35单个用户的排序内存
36 统计排序
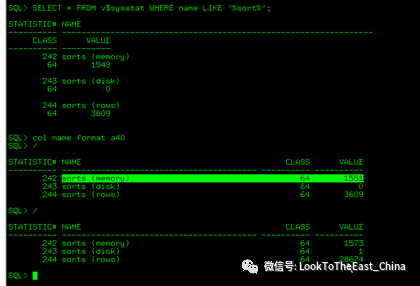
36避免排序:

36当磁盘排序/内存排序比值大于5%,需要增大排序内存

Sql调优
42 设置sql优化模式

Choose:9i的默认值
All_rows:最大吞吐率 11的默认值
First_rows_n:最快相应时间,可以设定
First_rows: 10g后不要用
43稳定执行计划
Optimizer_features_enable=数据库版本号
44 获得sql 的执行计划
1 创建plan表
@?/目录/ultxplan.sql
@?代表oracle home目录
2 获得

3 查看执行计划
A Select * from table_plan
B select * from table(dbms_xplan.display);
44 生成trace文件及查看
1 开启trace功能

2 使用tkprof格式化文件

44 自动trace
1 创建table_plan表
@?/目录/ultxplan.sql
@?代表oracle home目录
2创建同义词并授权

3 执行脚本、授权
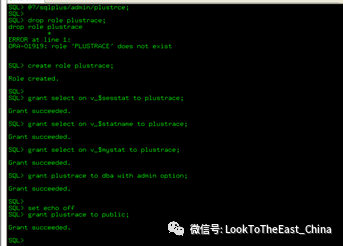
4 设置自动trace,并得到结果
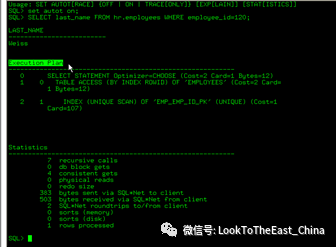
统计信息
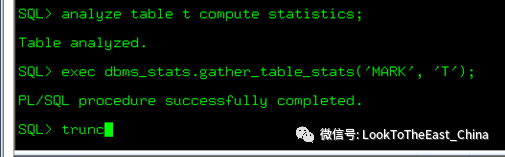
47获得表的统计信息
1 获得对象id

2 获得表的统计信息
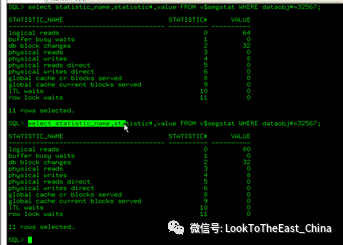

52 查询表块使用情况
1 分析表

2 查看表

52扩展和取消块
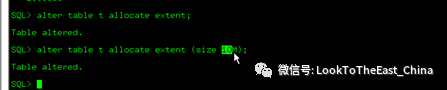


OLTP系统使用小块4k到8k
OLAP系统使用16k到64k
索引管理
54 监控索引空间
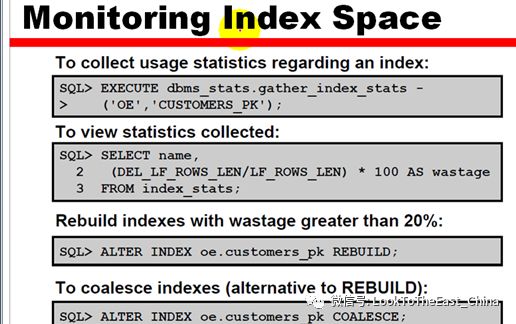
Rebuild:会重建索引 ,代价高
Coalesce:修补索引
54查看索引使用情况:
查询表object_usage
Oracle数据块架构
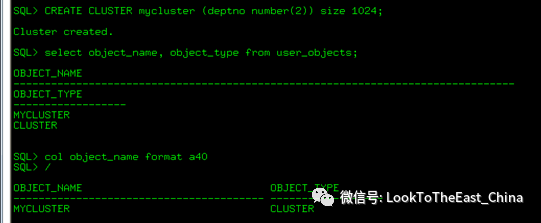
55创建集群表:
将两张表放在一个segment上
58创建索引集群表:
1 创建集群
Create cluster mycluster (deptno number(2)) size 1024
Deptno 集群的key,
1024 一个block的大小,决定可以放几条记录。
默认是放一条记录
2 创建索引
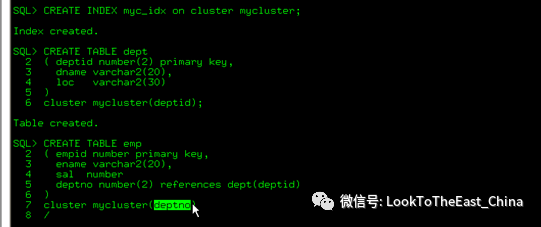
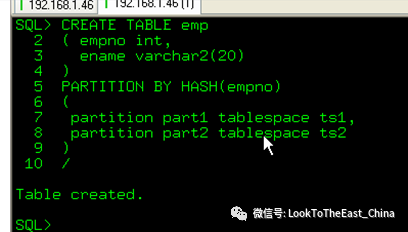
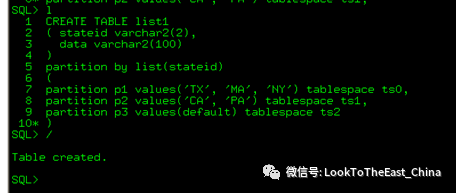
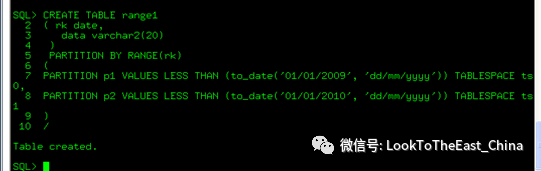
59分区表
时间分区表:
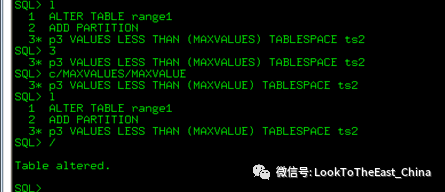
Hash分区表