





导语
窗口算子可以作用在keyed流或nonkeyed流,在keyed流上的窗口会并行化执行,但nonkeyed流上的窗口只会在一个线程里执行。创建窗口算子,需要指定两个窗口组件:
window assigner:窗口分配器,决定输入流的元素怎么进行窗口分配,方法给一个元素分配到一个或多个窗口
window function:窗口函数,窗口函数作用在WindowedStream或AllWindowedStream,对分配到一个窗口里的所有元素进行实际的函数计算
// 定义一个keyedStreamstream.keyBy(...)//指定 windowassigner,window函数返回WindowedStream.window(...)// 可选的,指定触发器,覆盖默认触发器.trigger(...)// 可选的,指定evictor.evictor(...)//指定windowfunction.reduce/aggregate/process(...)// 定义nonkeyed streamstream// 指定windowassigner,window函数返回AllWindowedStream.windowAll(...)// 指定windowfunction.reduce/aggregate/process(...)
水位生成器和窗口分配器作用不一样,水位生成器只影响给流里的元素增加时间属性、生成水位、发射水位这个过程;窗口分配器是将一个元素分配到一个或多个窗口。
Flink实现了多种窗口分配器,比如TumblingEventTimeWindows(事件时间的滚动窗口)、TumblingProcessingTimeWindows(处理时间的滚动窗口)、SlidingEventTimeWindows(事件时间的滑动窗口)、SlidingProcessingTimeWindows(处理时间滑动窗口)、DynamicEventTimeSessionWindows(动态事件时间会话窗口)等,后面会有详细的介绍。
窗口算子在每接收到一个元素后,就会调用窗口分配器,获取到元素分配的时间窗口列表(一个元素可能分配多个时间窗口),时间窗口对象(TimeWindow(long start, long end))只有两个属性:start time、end time,表示这个元素所在时间窗口的上限和下限。Flink根据元素的时间窗口判断这个元素是否迟到,如果元素没有迟到,将其添加到窗口状态,然后触发器判断是否需要触发计算。整个流程如下:
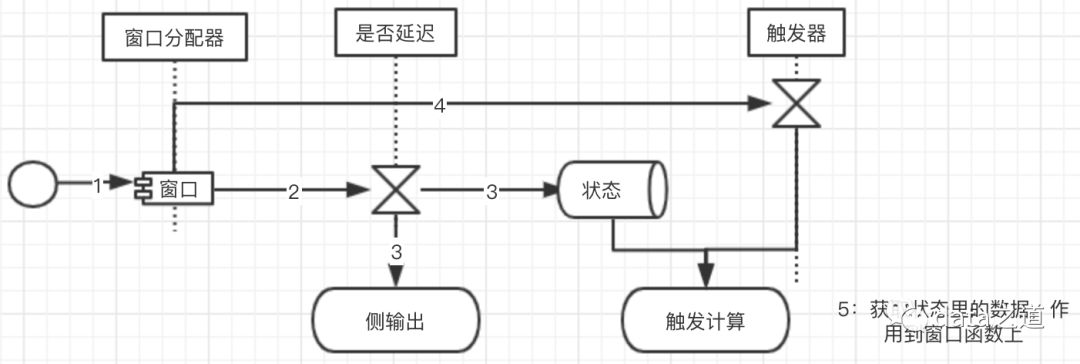
Window Assigners(窗口分配器)
TumblingEventTimeWindows
TumblingProcessingTimeWindows
SlidingEventTimeWindows
Trigger(窗口触发器)
EventTimeTrigger
窗口在接收到一个元素时,会将元素的时间窗口和当前水位比较,一旦水位大于时间窗口的结束时间,就会触发计算。正常到达(时间是在水位之后)的元素不会触发计算,如果是在一定延迟时间(延迟时间默认是0,allowedLateness函数设置)内到达的元素,就会触发计算,被称为延迟触发,因为是由延迟事件触发的。
/** 1、是否延迟达到判断:每接收到一个元素时,判断是否在一定延迟时间内到达,如果不是,就直接跳过,不会进行第二步触发器判断**/if (!isWindowLate(window)) {/** 2、触发器判断:水位已经到达窗口的结束时间,就触发计算**/if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {// if the watermark is already past the window fire immediatelyreturn TriggerResult.FIRE;} else {// 水位还未到达窗口结束时间,正常到达的,不触发计算,将其加到事件时间计时器队列ctx.registerEventTimeTimer(window.maxTimestamp());return TriggerResult.CONTINUE;}}
除了延迟触发,还有另一种触发计算的场景,称为主触发,是第一次触发窗口计算,就是在Flink内部接收到一个新的水位时,会触发比它小的所有时间窗口的计算。水位向前推进,触发窗口计算的逻辑实现:
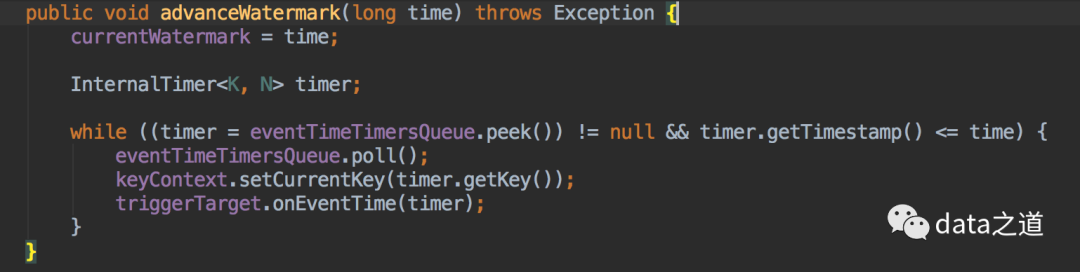
ProcessingTimeTrigger
如果使用的是ProcessingTime类型的窗口分配器,那么就用不到水位,这种情况下怎么触发窗口计算的呢?
注册定时器,在窗口的结束时间定时触发。process time没有数据延迟这一说。
窗口函数
窗口函数分为两种,一种是增量聚合函数(比如ReduceFunction或AggregateFunction),函数会对新接收到的元素立即聚合,并将更新后的结果存储到窗口状态,也就是窗口状态只保留结果值;另一种是全量窗口函数, 将新接收到的元素放到状态里,即在调用窗口函数前,在内部状态缓存窗口所有元素,当进行函数计算时,再对所有元素进行遍历。
显然增量聚会函数会减少状态存储空间。假设要统计每五分钟的访问pv,预测每五分钟的pv是上亿级别的,如个uid是32长度得哈希值,显然如果用全量函数,这个状态存储代价是不菲的。但是增量聚合的场景是受限制的,比如统计每五分钟访问量TOP100的IP。
allowedLateness
windowedStream和AllWindowedStream有个allowedLateness方法:允许窗口里的数据最多延迟多久到达,如果窗口结束时间+allowedLateness<=当前水位,意味着没有在一定的延迟时间内到达,会删除元素、进行侧输出,否则视为一个正常到达的元素,将其放到窗口状态里:
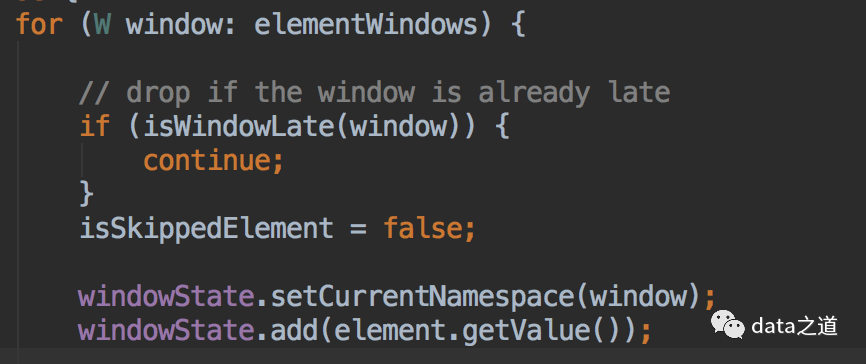 水位标识当前系统处理的时间进度,延迟是相对水位来讲的,所以延迟到达的元素,会再次触发窗口计算,而之前触发的数据,会buffer起来,直到watermark超过end-of-window + allowedLateness的时间,窗口的数据及元数据信息才会被删除。应将延迟触发视为对先前计算结果的更新,应用程序里应该考虑这种计算结果的重复性。
水位标识当前系统处理的时间进度,延迟是相对水位来讲的,所以延迟到达的元素,会再次触发窗口计算,而之前触发的数据,会buffer起来,直到watermark超过end-of-window + allowedLateness的时间,窗口的数据及元数据信息才会被删除。应将延迟触发视为对先前计算结果的更新,应用程序里应该考虑这种计算结果的重复性。
「在一起看」👇
