2019杭马
一、维表join使用场景
维表Join是流与表的关联操作,为了补全流里的额外字段,通常 这些待补全的维度字段很少发生变化,比如一个提交订单的数据流,只记录了用户ID,但要根据用户手机号所在地区进行数据分析,这就需要将订单数据流和用户维表进行关联,把查询到的手机号归属地填充到流里。在 项目 开发中,维表 一般存在RDBMS,比如mysql、hive,但也有可能存在hbase、redis等NoSql数据库。
二、传统join算法
2.1 归并连接
归并连接的思想类似归并排序,都是要先对两个数据集排序,然后从头开始比较。 join步骤是:1、拿到两张表里的数据,先将他们按照id从小到大排序。2、两张表都从第一个元素开始依次遍历,比较两个元素的大小,一旦遇到相等的id就输出一条join结果。 为了排序、遍历,归并连接需要吧两张表里的数据都加载到内存。 2.2 HASH连接
hash连接的思想和hash查找算法思想类似,要先对Table构建HASH索引:以id作为key、以行作为value。
为了查找效率,用小表简历hash索引。然后遍历另一个大表,并且对遍历到的id进行hash映射,用hash值到HASH索引中查找是否存在对应的记录,一旦找到,就输出一条join结果。
为了创建hash索引,HASH join需要把一张小表加载到内存。 但在流式持续查询的场景里,因为数据流是无穷尽的,数据一直在流入,每当有新的数据到来,可能会产生的新的查询结构,因此无法对表进行全表扫描,传统的join算法无法使用。 三、Temporal table join
Join当前维表数据,即每条处理的消息所关联上的维表数据是处理时刻的维表快照,也就是说,当数据到达时,我们会根据数据上的 key 去查询远程数据库,拿到维表里的当前数据后再关联输出。使用 JOIN 当 前维表功能需要注意的是,JOIN行为只发生在处理时间(processing time),即使维表新插入了一条能关联上左表之前消息的维度数据,或者删除了 维表中的数据 ,都不会对之前join结果流进行更新 。 3.1 语法
维表join只支持Blink查询优化器,可对维表进行inner join或 left join。
创建temporal table的sql和一般Sql 一样,比如 :
CREATE TABLE dim_user ( mobile_city varchar, user_id int ) WITH ('connector.type' = 'jdbc' 'connector.table' ='dim_user' ,'connector.url' = 'jdbc:mysql://ip:port/database' ,'connector.username' = 'username' ,'connector.password' = 'passwd' ,'connector.lookup.cache.max-rows' ='1000' ,'connector.lookup.cache.ttl' ='10s' ) ;流和维表的join :
SELECT u.mobile_city, SUM (o.amount) AS amount FROM Orders as o JOIN dim_user FOR SYSTEM_TIME AS OF o.o_proctime as u ON o.user_id = u.user_id FOR SYSTEM_TIME AS OF o.o_proctime 意味着每当处理左表(Orders表)的一条消息时,都会根据条件到维表 数据库查询数据,ON 语句块指定关联查询条件 ,而o.o_proctime 是左边(Orders表)的处理时间字段,字段名可以随意指定,但必须是processing time,当前不支持event time,也就是说这种方法不支持根据数据流的事件时间去查维度表里的对应时刻的数据 。 3.2 缓存机制
按照上面的处理方式:每处理一条流里的消息,都要到数据库里查询维表,而维表一般存在第三方数据库,这就导致每次都要有远程请求,特别是数据流大的情况下,频繁的维表查询,也会对外部数据库造成很大压力、降低整体吞吐,所以对维度表进行缓存不失为一个好的策略。但是用缓存也有个潜在的风险:缓存里的数据有可能不是最新的,这要在性能和正确性之间做权衡。 维表数据量 大的情况下,可以用LRU算法缓存部分数据。 在上面的create table里,已经开启了缓存: connector.lookup.cache.max-rows :缓存最大的记录条数,默认-1connector.lookup.cache.ttl :缓存失效时间,默认-1如果以上两个参数任意一个设置成-1, 那就会禁用查询缓存。查询缓存底层用google guava cache实现的,感兴趣的同学可以找相关材料进一步了解。创建缓存的代码,CacheBuilder是guava中的cache建造者类:
3.3 实现原理
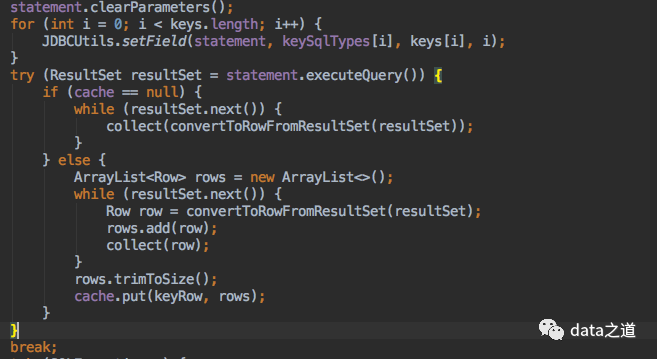
如果要实现维表join,那定义的TableSource必须实现LookupableTableSource接口,当我们执行jdbc类型的create table sql语句时,BLink查询优化器会自动根据sql语句创建JDBCTa bleSource LookupableTableSource 接口,因此我们创建的mysql表才支持维度查询。LookupableTableSource接口定义了三个方法: isAsyncEnabled :是否异步访问,如果异步访问使用异步方法,否则使用同步方法,当前不支持异步访问。JDBCTableSource 只支持同步操作, getAsyncLookupFunction :返回异步TableFunction函数 , 并发地处理多个请求和回复,从而连续的请求之间不需要阻塞等待。getLookupFunction :返回同步TableFunction函数 ,同步访问外部数据库 ,即来一条数据,通过Key去查询外部数据库,等到返回数据输出关联结果,继续处理数据,这会对系统的吞吐率有影响。 JDBCTableSource只支持同步look up模式,而TableFunction本质上是个UDTF (user-defined table function): 输入一条数据可能返回多条数据,也可能返回一条数据。eval则是TableFunction最重要的方法,当程序有一个输入元素时,就会调用eval一次,具体的业务逻辑实现就在这个方法里,最后将查询到的数据用collect()发送到下游。eval的核心代码:
所以对于维度查询的实现逻辑也是在eval函数里,具体来说在 JDBCLookupFunction 类里,该函数实现了根据关键字段查找外部数据库以及数据缓存的功能,也就是说维度查询本质上是用UDTF实现的。 StreamExecLookupJoinRule规则解释器负责把表达式转换成物理执行计划,StreamExecLookupJoin把执行假话转换成Look up join。 Temporal Table Join ,是单流join,本质上是Lookup join: 维表(被Lookup的表)作为被驱动表,左表每来一条消息,就用过滤关键词到数据库查询一次。temporal table join是轻量级的,不会保存状态数据。 四、Temporal table function join
如果流延迟过来的数据要跟之前的维表数据做关联,即根据流的事件时间, 查找某个时间点的维度数据而不是当前维度表数据。比如这样一个场景, user_gps表实时记录了用户的gps地理位置,现在需要根据用户下单时的gps进行地理位置分析,也就是用流的事件时间查找维表里某一时刻的数据。Flink引入了temporal table,Temporal Table是Append Only表(只允许插入记录,而不会修改、删除记录)上的 物化视图 ,它把Append Only的表变化解释为表的Changelog,并提供特定时间版本的表数据、将每个时间点映射到静态关系中,表的版本数据存储在状态里。 在Flink中,通过TemporalTableFunction 实现对temporal table的访问,必须定义主键和时间戳属性,主键确定覆盖哪些行,时间戳确定有效的时间,也就是表的数据版本。 join TemporalTableFunction语法和join UDTF( User-defined table functions )是一样的, TemporalTableFunction本质上是TableFunction的一个实例,当前仅支持对TemporalTableFunction的 inner join。JDBC Connector不支持Temporal Table Function,因为JDBC Source是batch流。 4.1 定义
时态表函数是Flink TableFunction的扩展,可以通过与Table API或SQL解析器相同的简单方式进行定义。调用Table对象的createTemporalTableFunction 函数,创建Temporal Table Function,然后将函数注册到table environment里,这样在sql里就可以用这个函数,换句话说,temporal table function只能在Table里使用:TemporalTableFunction ttf = tab.createTemporalTableFunction(String timeAttribute, String primaryKey); tEnv.registerFunction("ttf" , ttf); createTemporalTableFunction 方法接收两个参数,用来跟踪一段时间内发生的更改:
timeAttribute:时间属性,版本控制字段,事件时间或处理时间。 不会直接对TemporalTableFunction进行求值操作,而是重写为其他运算。 Flink中使用 LATERAL TABLE(TemporalTableFunction)的语法进行join查询:
SELECT *FROM A,LATERAL TABLE (B(A.t))WHERE A.id=B.ida、A表是一个append-only(不能更新记录)表, b、B表是一个Temporal Table Function,A表的时间属性作为参数传入 对表A里的每一条记录,B表都会返回和A表记录行的时间相对应时间版本的数据,然后A表行和B表返回的行根据连接条件进行连接。
4.3 Processing-time
用处理时间时,向temporal table function传递的时间参数总是当前时间,所以temporal table function返回的是底层表最新数据,底层表的最新更新也会立即覆盖状态里的当前值,对于每个primaryKey,状态里只保留最新版本的一行数据 。temporal table更新不会影响之前已经发送 的join结果。 可以简单的把processing-time temporal table function join看作一个HashMap,map存储了temporal table表的所有数据,而且temporal table表里的新记录会覆盖hashmap的value,查询流里的每一条消息总是和状态里的Hashmap进行关联。 如果要传入TemporalTableFunction事件时间属性,那么定义TemporalTableFunction时,也需要定义成事件时间,否则会报错: Caused by : org .apache .flink .table .api .ValidationException : Non rowtime timeAttribute [TIME ATTRIBUTE(PROCTIME)] passed as the argument to TemporalTableFunction
4.4 Event-time
用event-time属性时,可能向 temporal table function里传递一个过去的时间戳,因此状态里不但要保留最新数据,还要保留所有版本(版本是根据时间标识的)的数据。 比如一个处理一个事件时间是12:30:00的消息,消息会和12:30:00版本的temporal tables进行join,即输入的行只会和时间戳<=12:30:00的行进行关联。而且左 表里在当前event-time之后的数据会临时缓存在状态里。
4.5 实现原理
Flink Sql引擎把逻辑计划转成底层的物理执行算子,对于temporal table function执行计划的转换是在StreamExecTemporalJoin类里:负责把表达式转换成物理执行计划;row time、process time不同时间类型的join,分别用TemporalRowTim eJoinOperator、TemporalProcessTimeJoinOperator实现的。这里 介绍一下StreamOperator,StreamOperator 是Streaming里所有operator 的基本接口,几个核心的方法: 如果要创建算子处理数据,需要实现OneInputStreamOperator 或TwoInputStreamOperator ,分别声明处理单个输入流、处理两个输入流,很明显我们的Temporal Table Function Join是双流联接, 需要处理两个输入流的数据,所以我们还要关注下处理两个流的算子 的核心方法:
4.5.1 Processing-time实现
右边接收到数据后,会更新状态,即只保留最新的状态数据。 rightState .update (rightElement .getValue ());左边接收到数据后,不会把消息放到状态里,因为是消息处理时关联的,左边消息放到状态没有意义;然后拿到右表状态数据,根据右表最新状态数据和左边流里的消息进行条件判断,关联上后,再把这两条消息发送出去,算子实现在TemporalProcessTimeJoinOperator 。
//leftSideRow:接收到的左边流里的消息 //rightSideRow:右表最新状态里的数据 // 进行关联条件判断 joinCondition.apply(leftSideRow, rightSideRow) 4.5.2 Event-time实现
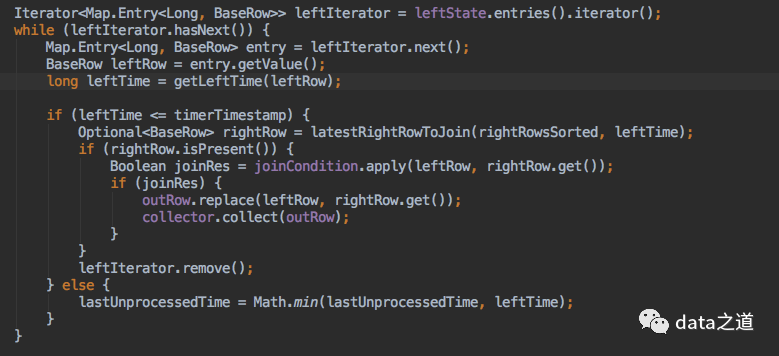
在处理左边和右边数据时,都会接收到消息放到状态中,但是两者状态索引的key格式不一样:左表是元素在数据流中的自增index作为key、右表是元素的event time作为key,这样设计的好处是方便在状态里删除左边历史数据、并从状态里查找特定时间点的数据,算子实现在TemporalRowTimeJoinOperator 。 // 左边元素放到状态里,自增id 作为key BaseRow leftRow = leftElement .getValue ();leftState .put (getNextLeftIndex (), leftRow );// 右边元素放到状态里,时间作为key ,即保留了多版本数据 BaseRow rightRow = rightElement .getValue ();Long rightEventTime =rightRow .getLong (rightTimeAttribute );rightState .put (rightEventTime , rightRow );event time有个触发器概念,触发器会触发数据实际计算:遍历左边状态数据,并根据元素的时间到右表状态数据里查找该时间点的数据。刚才提到过,时间作为右表状态的key,为了提高效率,先根据时间对状态数据进行排序,然后再用二分查找算法查找特定时间点数据。
右边表数据一旦找到,下一步就可以进行join条件判断,然后把符合条件的左边和右边数据发送到下游:
五、普通join
普通连接是最通用的连接类型,任何新记录或对join两侧的任何更改都是可见的,并且会影响整个连接结果。两侧所有数据都会存到状态里。 当用JDBC Table Source读取数据 时,比如从mysql读数据, 如果查询的表后面不加FOR SYSTEM_TIME AS OF ,也不加LATERAL TABLE ,那么就是普通连接。SELECT u.mobile_city, SUM (o.amount) AS amount FROM Orders as o JOIN dim_user u ON o.user_id = u.user_id 5.2 JDBC Source实现原理
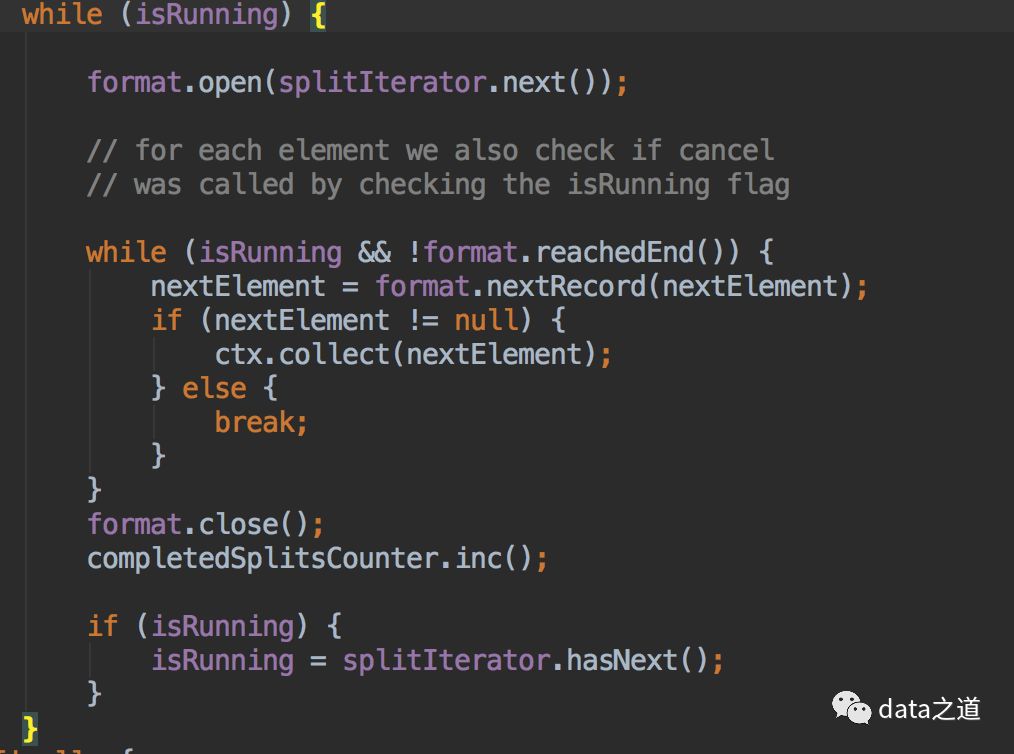
SourceFunction用InputFormat实现数据源的读取,SourceFunction是Stream data source的基本接口:应保持run方法长时间允许、响应cancel方法终止方法执行、生成消息并发送到下游。具体来讲实现思路就是在run的while循环内调用format类对应的方法,获取format生成的消息,并emit:
format的实现就是用jdbc的方式从mysql query数据,每次format的nextRecord都是从resultSet里get操作。
5.3 Join实现原理
StreamExecJoinRule规则引擎把join转换成StreamExecJoin,left join关联用StreamingJoinOperator实现、semi join关联用StreamingSemiAntiJoinOperator实现的。普通join两侧流都作为驱动表,即当一侧的流进来后,这个数据会和另一侧流里的状态进行关联join。
相关阅读: 「在一起看」 👇