




之前介绍过基于循环的ODS快速同步,没有看过的同学可以在这里了解下《通过循环快速全量同步多个表》,其优点是不需要一个表开发一个job,当新增同步表时,只需在配置中增加一行,就可实现自动同步。但其中一个明显的缺点是不能并发的同步多个表,如果一个表因某种原因执行了很久,会导致其他都在等待,整体同步效率就会降低很多;而其中一个优化方案就是用多线程的。
当前我们系统中1千多个表同步都是基于多线程、配置化管理的,本文主要介绍下多线程使用、同步的配置化思路,期望对各位有些帮助。
一、多线程实例之表输出
通过设置步骤的“改变开始复制的数量”属性,可以实现步骤的多线程执行。对于表输出控件,右键选择"Change Nunber of Copies to Start ..",然后在Number of copies的输入框里填写并发的线程数就可以了。
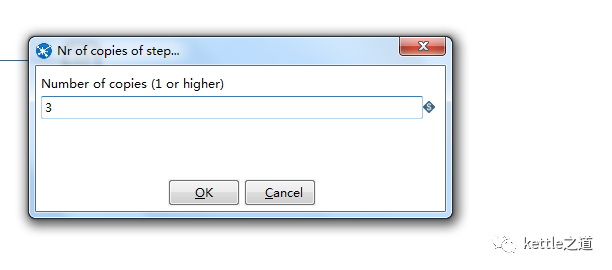
单线程测试:10W的数据量单线程14分钟
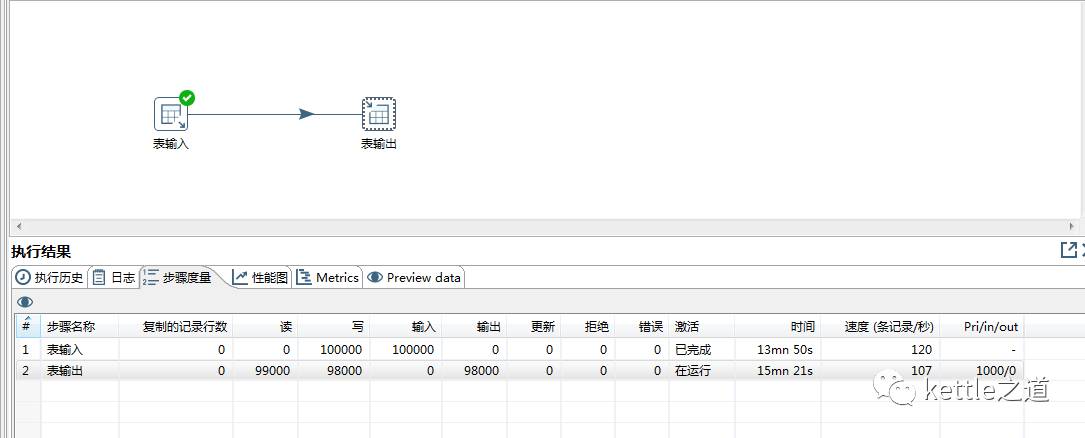
多线程测试:3个线程7分钟跑完,效率提高一倍。“表输出”这个步骤会有3个线程并发执行,而“表输入”将数据流按行通过轮询的方式发送给“表输出”的3个线程
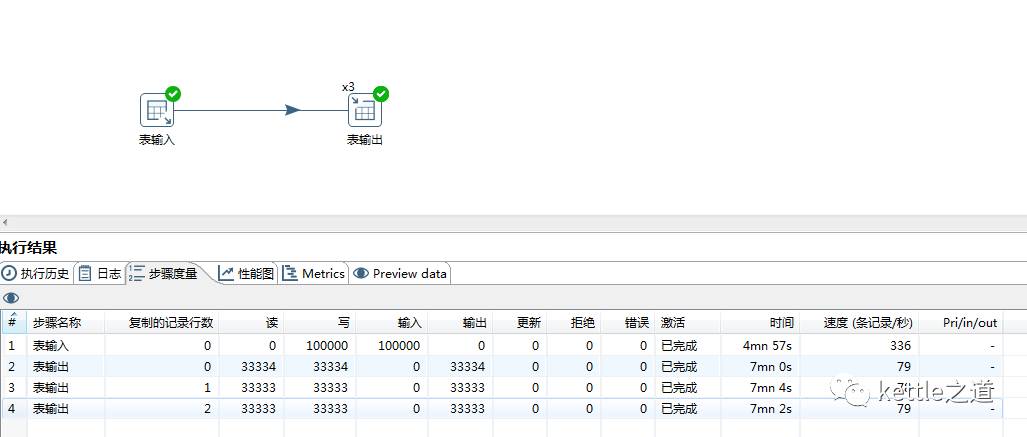
从上面的例子可以明显看到多线程相对于单线程的效率提高的很明显。
但使用多线程时需要注意是否会引起并发问题,如在多线程"插入/更新"的场景下,如果更新的key不是唯一的,有可能会产生死锁(多个线程同时更新同一行的数据)
二、ODS配置表
 同步方式用于是否是全量抽取还是增量抽取,
同步方式用于是否是全量抽取还是增量抽取,
一个配置的例子:

其中第一个表是增量,有抽取的增量条件,第二个表是全量抽取,没有抽取条件。
三、实现步骤
1、从配置表读取待抽取的数据表

2、job_ods_all_exe并发10个线程执行,并接收上个步骤传递的表名、数据库名、抽取类型等参数
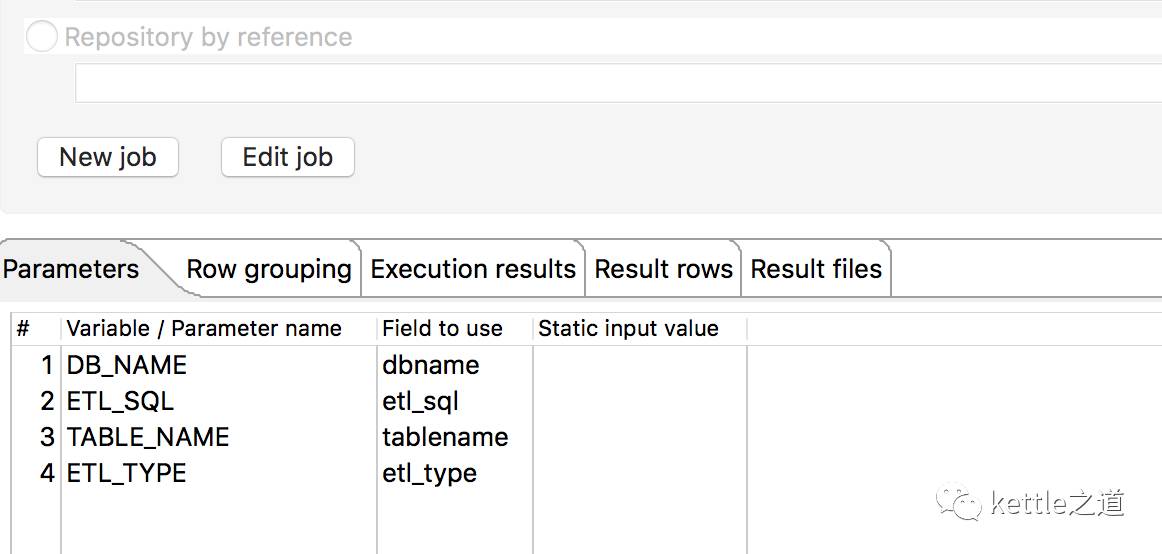
3、job_ods_all_exe的处理逻辑,根据ETL_TYPE分发数据是增量抽取还是全量抽取
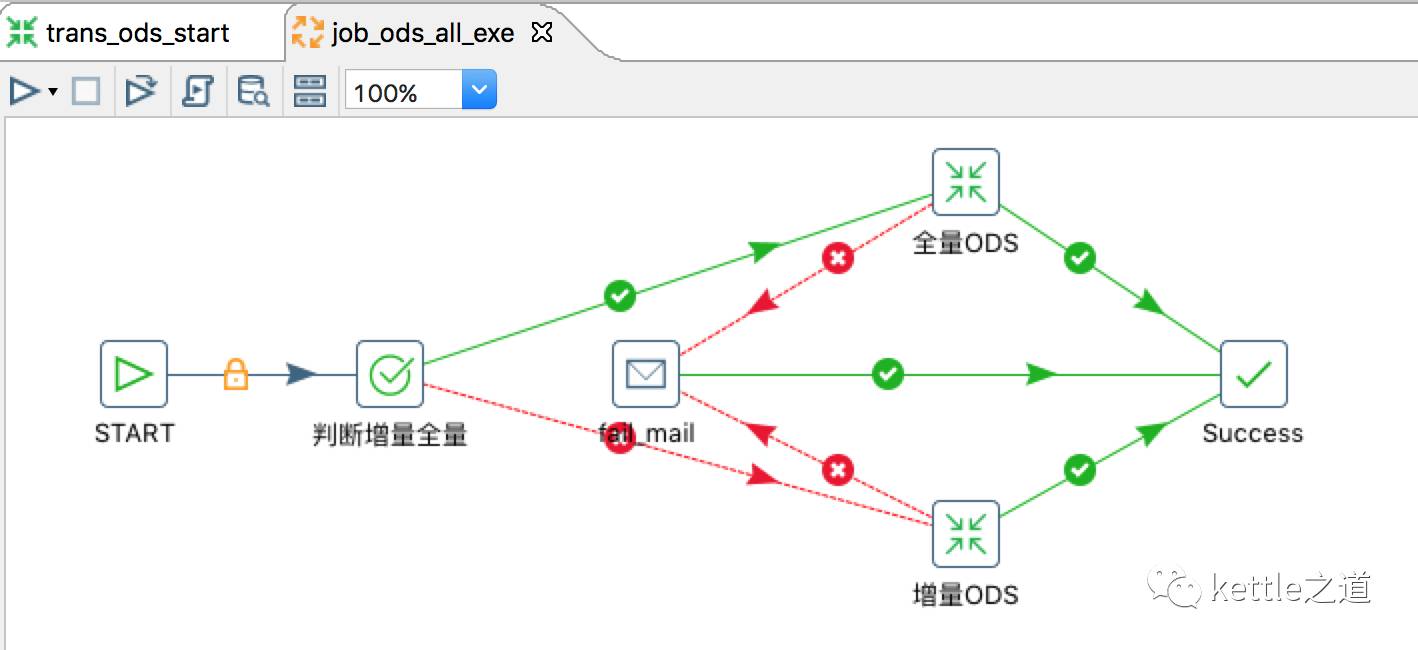
4、全量ODS和增量ODS的实现逻辑:
两个步骤的都是通过“表输入”步骤查询数据,全量是直接用“表输出”先把表truncate,然后插入数据;增量ODS是用插入更新的方式。
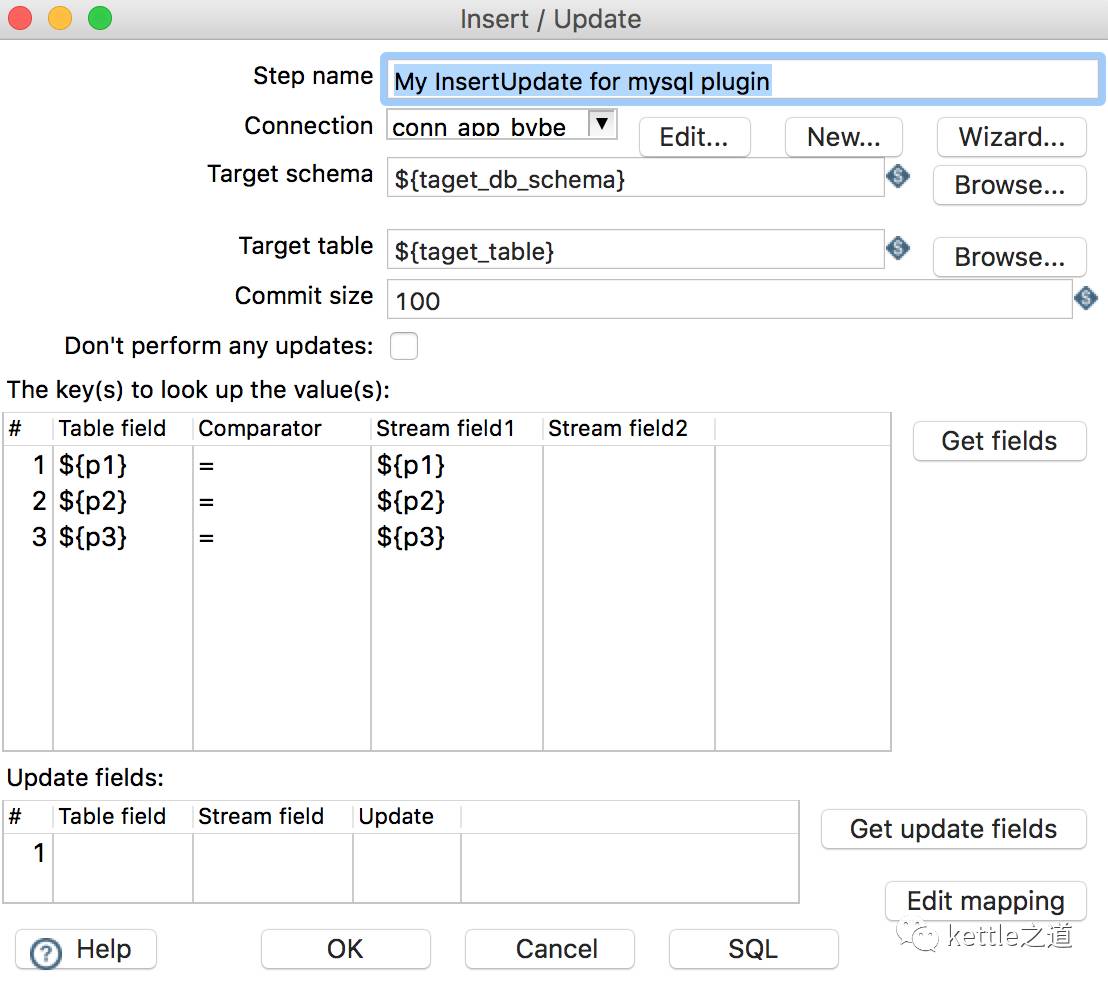
插入更新控件有两个必须条件:key、更新的字段,key可以通过传参的形式把字段传进来,需要扩展etl_ods_table表字段,把源表的key配置进来,一般配置三个key字段就足够;kettle自带的“插入/更新”控件的更新字段是必选项,这样就做不成通用的,因为不可能所有的同步表字段都一样,这就要自定义插件,把更新字段改成非必选项:
四、其它的配置项
1、目标表配置:在etl_ods_table表中配置每个同步表的目标表,目标表用变量表示,即是(三.4)里的${taget_db_schema}、${taget_table_name},这样组件就可以复用,提高整体的灵活性
2、数据库连接:配置源表和目标表使用的数据库连接,通过参数传递的形式,实现数据库连接的动态化,配置表结构:
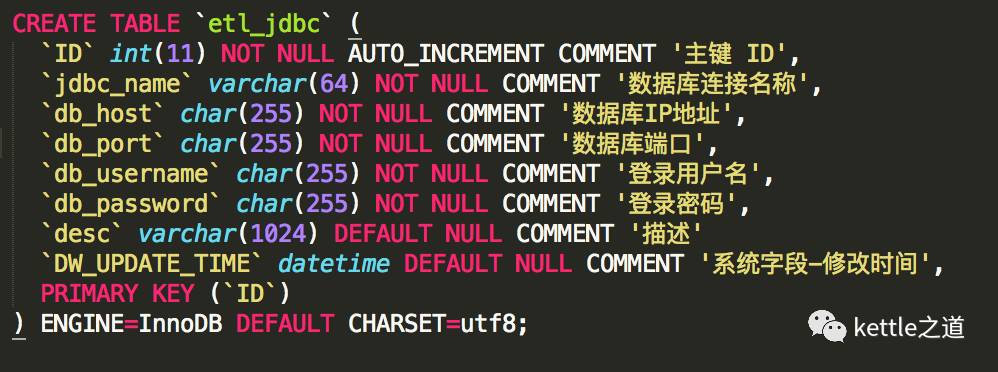
并在etl_ods_table配置表,对于源表和目标表,都增加数据库连接的ID,查询同步表的信息时,数据库连接的也同时通过参数传递。
 加入KETTLE技术交流群,分享学习心得,一起共同进步。
加入KETTLE技术交流群,分享学习心得,一起共同进步。
QQ群:452881901,扫下方二维码快速加群:

点击下方阅读《Hive查询优化》
