





今天花点时间整理了些资料,顺便聊聊 SQL Server 中的线程是如何使用的。内容较多,分上下两篇文章。在此前,我们先简单了解几个概念。
请求(Requests),是查询或批处理的逻辑表示形式,请求还表示系统线程所需的操作,如检查点或日志编写器。请求相关信息查看 sys.dm_exec_requests。
任务(Tasks),满足请求所需完成的工作单元,可以向单个请求分配一个或多个任务。任务状态信息参考 sys.dm_os_tasks,挂起任务查看 sys.dm_os_waiting_tasks。
工作线程(Worker Threads),是操作系统线程在 SQL Server 中的逻辑表现形式。数据库引擎通过工作线程协调任务执行。工作线程信息查看 sys.dm_os_workers。
线程(Threads),是操作系统执行的最小处理单元,允许将程序逻辑分为多个并发执行路径。当复杂程序同时执行多个任务时,线程非常有用。线程信息查看 sys.dm_os_threads。
计划程序/调度器(Schedulers),又称为 SOS 计划程序,管理需要工作线程处理的任务,是系统CPU的逻辑体现,与逻辑CPU一一对应。调度器信息参考 sys.dm_os_schedulers。
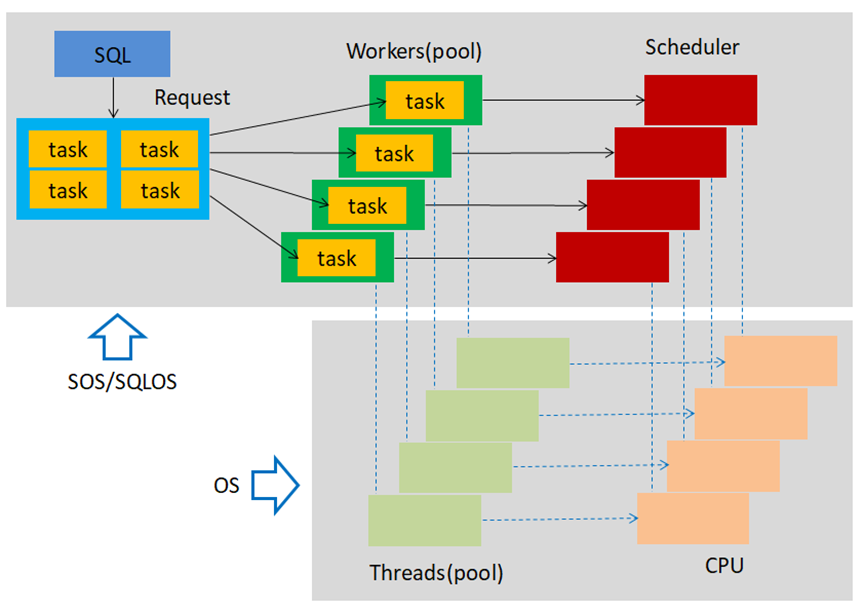
下面,我将通过几个问题来剖析SOS是如何工作的。
单个请求如何触发并行任务处理?
并发使用了多少个调度器(CPU)?
等待类型CXPACKET
等待类型SOS_SCHEDULER_YIELD
首先确认一下,测试的数据库实例中,关联了操作系统所有的逻辑CPU,共16个。
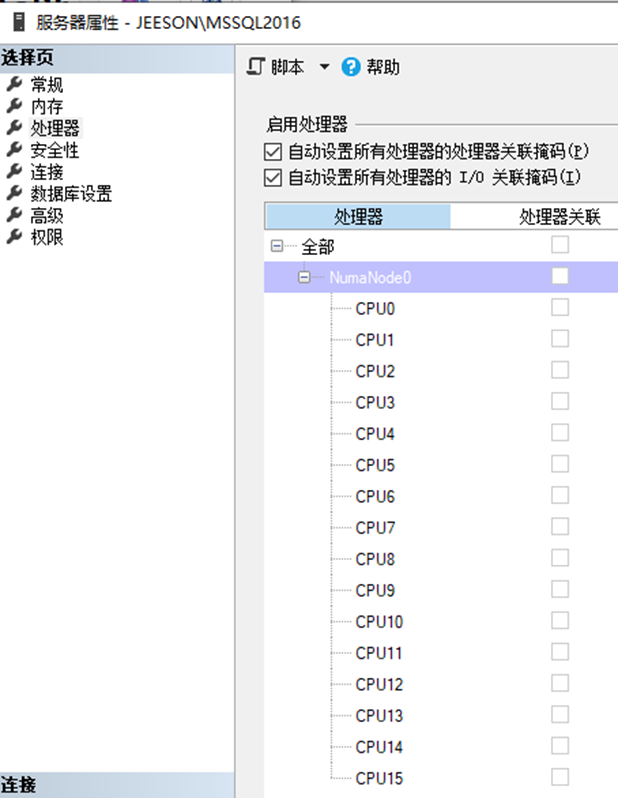
同样,我们先确认几个系统参数,都是系统默认值。
EXEC SP_CONFIGURE 'show advanced options',1RECONFIGUREGOEXEC SP_CONFIGURE 'cost threshold for parallelism'EXEC SP_CONFIGURE 'max degree of parallelism'EXEC SP_CONFIGURE 'max worker threads'GO
接下来,是时候展示真正的技术了!
单个请求如何触发并行任务处理?
我下载了一个官方的案例库AdventureWorks2016,随意执行一个查询操作。
USE AdventureWorks2016GOSELECT *FROM Sales.SalesOrderDetail AINNER JOIN Production.Product B ON A.ProductID = B.ProductIDORDER BY B.Name
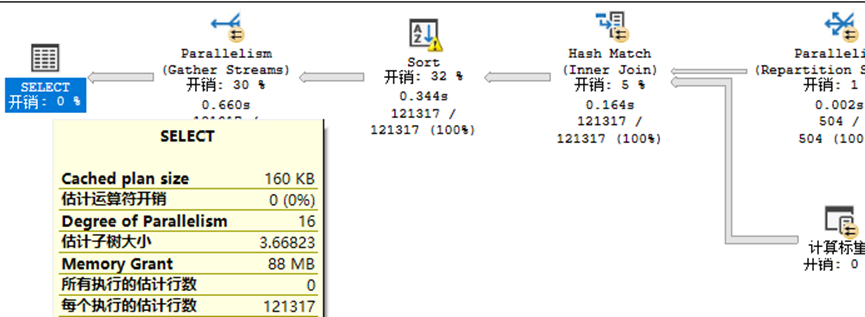
我们可以看到,这个请求启用了并行处理(图纸双箭头图标),使用了16个线程处理任务(Degree of Parallelism=16),也就是每张表、每个步骤都分为16个任务,每个任务使用一个工作线程来处理。
上图中,我们还看到一个名为“估计子树大小”的值为3.66823,该值就是影响并行任务处理的关键。为了方便说明,现在我先对该SQL设置并行度为1运行(MAXDOP=1,即单线程运行)。
USE AdventureWorks2016GOSELECT *FROM Sales.SalesOrderDetail AINNER JOIN Production.Product B ON A.ProductID = B.ProductIDORDER BY B.NameOPTION(MAXDOP 1)
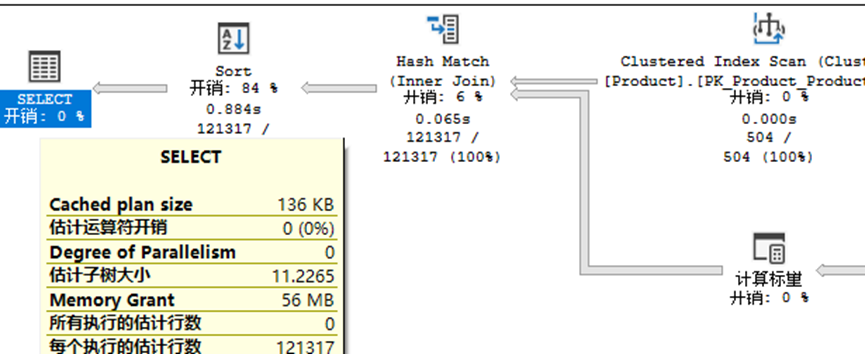
可以看到上图的执行计划并没有启用并行计划,查询的“估计子树大小”为 11.2265。还记得上面提到的系统参数“cost threshold for parallelism”吗,它表示当运行同一查询的串行计划的估计开销高于在“cost threshold for parallelism”中设置的值时,SQL Server 才创建和运行该查询的并行计划。上图“估计子树大小”大于“cost threshold for parallelism”的值,因此该SQL请求启用并行计划!
cost threshold for parallelism 并不是时间单位,网上很多文章说是时间开销是错误的。
现在我把 cost threshold for parallelism 的值改为12,高于串行“估计子树大小”的值 11.2265。
EXEC SP_CONFIGURE 'cost threshold for parallelism',12RECONFIGURE WITH OVERRIDEGOSELECT *FROM Sales.SalesOrderDetail AINNER JOIN Production.Product B ON A.ProductID = B.ProductIDORDER BY B.NameGO
通过查看执行计划,查询并没有启用并行处理!完全符合我们的预期,此处就不截图了。也就说明,串行计划的估计开销高于在“cost threshold for parallelism”中设置的值时才使用并行计划,否则使用单线程处理。
对于OLTP系统来说,简单的SQL与单线程任务基本可以很好地避免对其他请求的影响。对于与OLAP结合,且访问不高的系统,单线程在处理大量数据时将比较慢,并不能有效利用其他CPU资源。我们可以通过设置 cost threshold for parallelism 以满足系统的负载。
并发使用了多少个调度器(CPU)?
前面的并发请求中,使用的是16个逻辑CPU(Degree of Parallelism=16),这是如何控制的呢?前面在查询语句中提供了一种语句级别的设置方法OPTION(MAXDOP 1),我们也可以通过参数 max degree of parallelism在全局范围内设置。
--刚才的测试设置回初始值EXEC SP_CONFIGURE 'cost threshold for parallelism',5RECONFIGURE WITH OVERRIDEGO--此次才是最大并行度的设置EXEC SP_CONFIGURE 'max degree of parallelism',2RECONFIGURE WITH OVERRIDEGO
我将最大并行度设置为2,即允许并行任务最多使用2个CPU处理。
SELECT *FROM Sales.SalesOrderDetail AINNER JOIN Production.Product B ON A.ProductID = B.ProductIDORDER BY B.Name
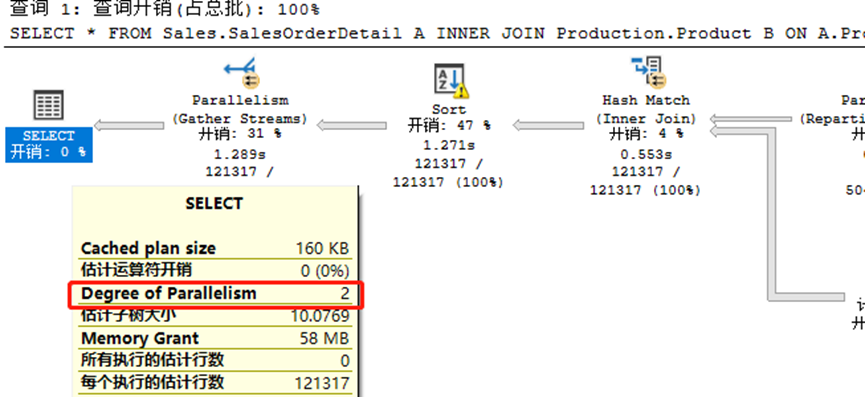
可以看到,该执行计划中,查询使用2个CPU进行处理,每个并行步骤都是使用2个CPU。这里我们就有个疑问,执行处理的各步骤中,使用的是固定的2个CPU,还是在16个CPU中都有使用呢?
当我运行上面的查询语句时,我同时在另一个会话窗口中快速执行以下SQL。
select t.session_id,t.scheduler_id,w.worker_address,t.task_state,wt.wait_type,wt.wait_duration_msfrom sys.dm_os_tasks tleft join sys.dm_os_workers w on t.worker_address=w.worker_addressleft join sys.dm_os_waiting_tasks wt on w.task_address=wt.waiting_task_addresswhere t.session_id=55order by scheduler_id;
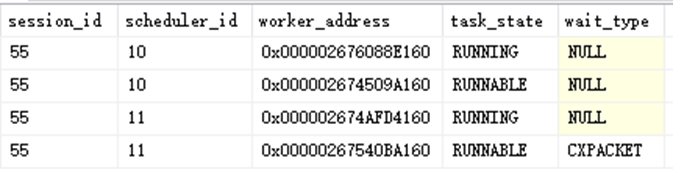
上图为某个时刻截图,我们可以看到,在整个脚本运行期间,执行计划中的各个步骤都只使用了编号为10与11的scheduler(不同时刻/不同步骤也是如此)。也就是说,同一个请求中,各步骤的工作线程固定在相同的2个CPU中运行。这种情况相信大家会有明显的理解,当某个SQL并发执行比较慢的时候,我们发现某几个逻辑CPU使用率较高,而其他CPU并没多大变化。
如果手动设置最大并行度 max degree of parallelism ,官方建议不超过8,大于8带来的回报可能没有那么高。如果你的系统是OLAP类型的,且用户访问非常少,你可以设置更大的值。
下一篇文章,将说明等待类型 CXPACKET 和 SOS_SCHEDULER_YIELD的形成原因。
最近文章推荐:
历史文章推荐:

