




概述
PolarDB-X是MySQL生态下的分布式数据库,对MySQL高度兼容,可以让用户的使用体验和MySQL一样,并且无需在业务侧做过多的修改,就能享受分布式带来的优良特性。
类型系统是数据库的基石之一,往往被用来衡量一款数据库产品的专业性,关乎数据库的兼容性和性能。许多分布式SQL引擎、中间件,为了减轻开发设计难度,其类型系统往往自成一派。而要完全兼容MySQL体系下的类型系统,分布式数据库所面临的设计难度是呈指数级增长的。
本文将介绍MySQL生态下PolarDB-X类型系统的总体设计。虽然本文主要面向数据库内核开发者,但是对于广大用户来说,也许能解答您在使用类型时产生的一些困惑。
类型推导
概述
PolarDB-X是MySQL生态下的分布式数据库,对MySQL高度兼容,可以让用户的使用体验和MySQL一样,并且无需在业务侧做过多的修改,就能享受分布式带来的优良特性。
类型系统是数据库的基石之一,往往被用来衡量一款数据库产品的专业性,关乎数据库的兼容性和性能。许多分布式SQL引擎、中间件,为了减轻开发设计难度,其类型系统往往自成一派。而要完全兼容MySQL体系下的类型系统,分布式数据库所面临的设计难度是呈指数级增长的。
本文将介绍MySQL生态下PolarDB-X类型系统的总体设计。虽然本文主要面向数据库内核开发者,但是对于广大用户来说,也许能解答您在使用类型时产生的一些困惑。
类型推导
类型推导机制,用于对SQL做正确的类型推算,向用户呈现出确切的返回类型;更重要的是,指导算子执行、表达式求值时采取正确的行为。在分布式数据库中,类型推导还需要协调存储层与计算层,约定网络传输时的正确类型。
MySQL数据类型通过DDL语句来定义,一列数据的元信息包括精度与长度信息、character set与collation、default value等。元信息约束着类型的处理行为,类型推导需要自顶向下或自底向上地推算和传递元信息。
理论基础
SQL和其他编程语言一样,本质上也是一种计算机语言,其类型系统和推导可以用Hindley–Milner类型理论来表述。例如应用原理(Application)和实例化(Instantiation)原理:
- [App] 如果在上下文Γ中,表达式e0可以从输入类型τ中推得返回类型τ',并且表达式e1具有类型τ,那么e1表达式应用到e2表达式能得到τ'类型;
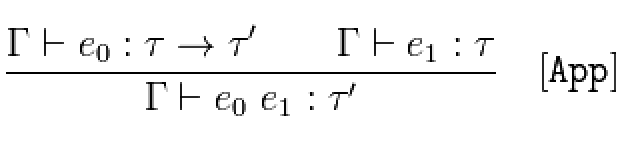
- [Inst] 如果表达式e具有类型σ‘ ,且类型σ’ 是 σ的子类型,我们可以推知e具有类型σ
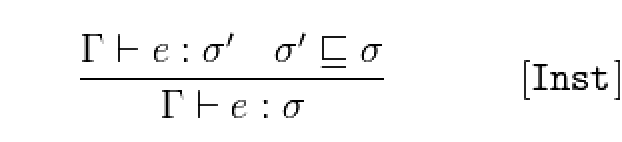
把上述理论应用在数据库的关系代数中,又可以得到一组推论,例如,
- 如果表达式e1和e2分别具有类型τ1和τ2,且两种类型没有公共子类型,则e1和e2的笛卡尔积返回类型是类型τ1和τ2的并集:
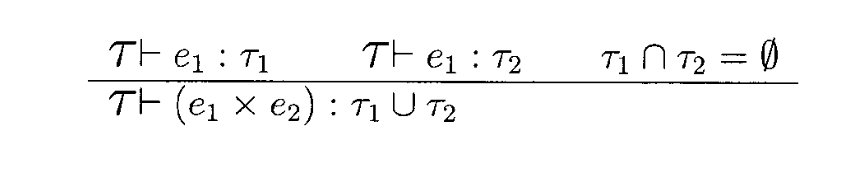
两种流派
和学院派的PostgreSQL不同,MySQL对于用户SQL是极其宽容的,函数可以随意堆叠在一起,数据插入也几乎不会进行类型限制。从根源上讲,这种差异是PostgreSQL和MySQL在类型推导上的设计不同所造成的。
PostgreSQL的内部设计以规范和优雅而著称。以PostgreSQL生态下的分布式数据库CockroachDB为例,对于用户传来的一条insert语句
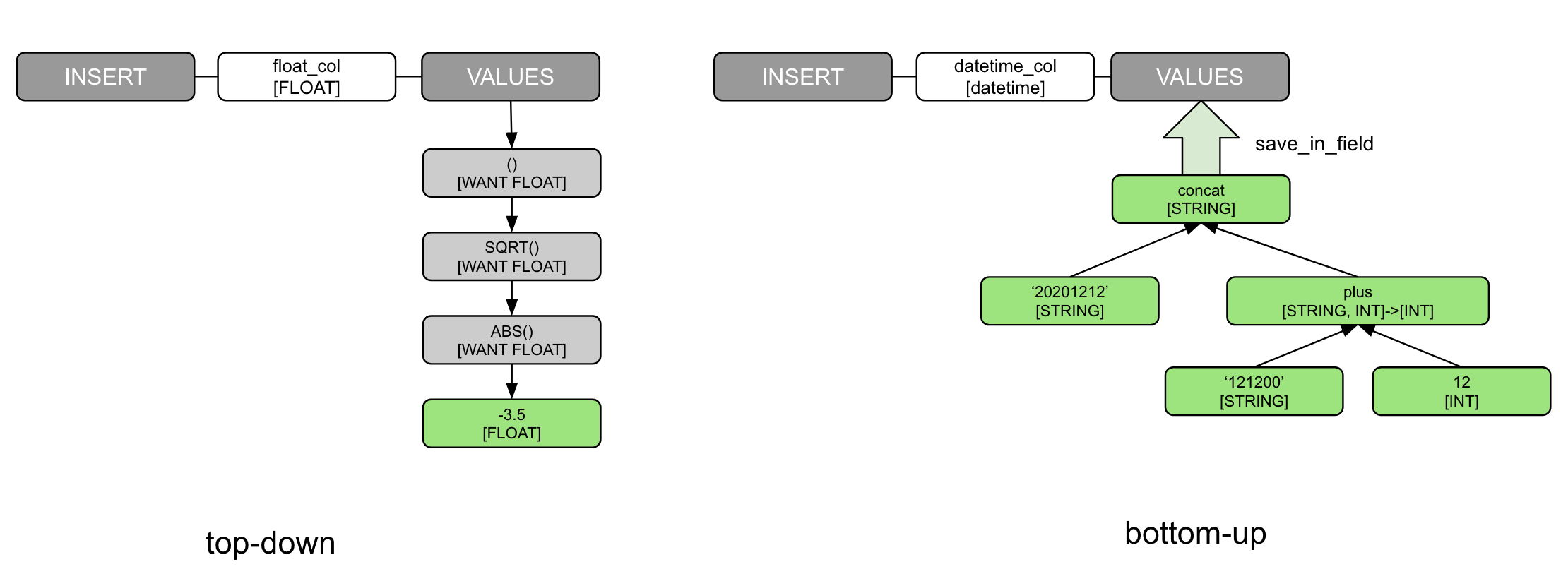
INSERT INTO float_col VALUES (SQRT(ABS(-3.5)));INSERT INTO float_col VALUES (SQRT(ABS(-3.5)));CockroachDB会自顶向下地传递上层算子所需要的数据类型,直到最底部的叶子节点。如果在传递过程中,某些算子、表达式与想要的类型不符,则会报类型推导错误,并拒绝SQL执行。
与CockroachDB的Top-Down推导方式不同,MySQL使用了Bottom-Up(自底向上)的推导方式。下面这条SQL在MySQL里可以正常执行,在PostgreSQL下将会被拒绝:
insert into t (datetime_col) values (concat('20201212', '121200' + 12));insert into t (datetime_col) values (concat('20201212', '121200' + 12));MySQL会从叶节点开始自底向上地推导类型,每个父节点会先确认子节点的类型,来决定自身的返回类型。类型推导的限制是十分宽容的,字符类型可以作为加法的输入,用于拼接字符串的concat表达式也能接受整数类型。甚至对于最终要写入的datetime类型字段,也容许将concat拼接的字符串转换解析为时间类型数值。
MySQL过于宽容的类型推导方式,意味着在实际计算时需要引入大量的隐式类型转换。在MySQL行式执行模式中,每个表达式(Item_func)提供了val_int / val_str / val_date等不同的接口,上层表达式根据自身实现的需求,调用下层表达式相应的接口,从而获取相应的处理类型。隐式类型转换往往就发生在特定类型接口的调用过程中。这种隐式类型转换是非形式化的,它隐藏着函数实现的代码逻辑中,没有明确的规律,并且伴随着表达式执行额外的指令开销。
而在以列式执行为主的分布式数据库中,表达式之间以Chunk或者向量的形式传递数据,多余的操作需要被独立出来进行规范化的处理,从而提升表达式运算效率,也让代码更加简洁和优雅。
PolarDB-X类型推导与隐式类型转换
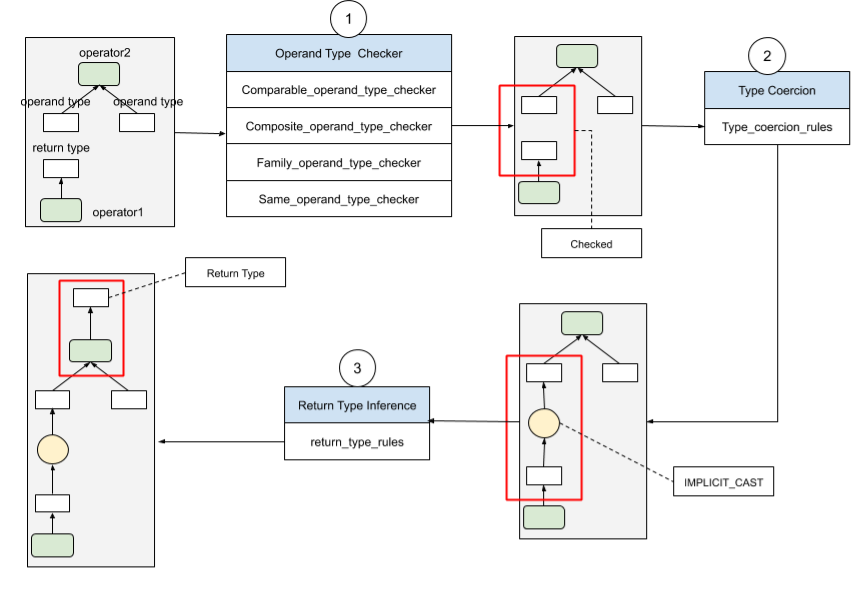
PolarDB-X 用更加模块化、结构化的方式,复现了MySQL类型推导和隐式转换的规则,达到了与MySQL高度兼容的效果,PolarDB-X将用户传来的SQL解析为AST之后,将对每个表达式节点依次进行操作数类型检查、隐式类型转换和返回类型推导,具体过程包括:
- 操作数类型检查(Operand Type Checker)。子表达式的返回类型,会作为父表达式的操作数类型。每个表达式配备有相应的操作数类型检查规则,通过此规则来检查操作数类型是否合法;
- 隐式类型转换(Type Coercion)。当子表达式的返回类型不能成为合法的父表达式操作数类型时,我们需要调用相应的类型转换规则,尝试进行返回值类型return type到操作数类型operand type的转换。办法是,生成一个合法的IMPLICIT_CAST表达式,将return type强制转换为合法的operand type类型。由于此转换对于用户来说是透明的,所以称为隐式类型转换。
- 返回值类型推导(Return Type Inference)。当表达式具备了合法的操作数之后,可以调用相应的返回值推导规则,通过操作数推出正确的返回值类型。
以上三个步骤如下图所示:
类型存储与计算
设计原则
类型的表示决定了数据的存储和运算方式。对于同一种类型,其存储和运算时的表示形式又是有差异的。
- 在设计类型存储时,我们关心如何节省空间、提高存储效率,并且让字节连续、对齐,以便于内存分配,也有利于CPU cache预取;
- 运行时类型表示的设计目标是提升计算性能。特别的,对于大类别下的小类型,如字符类型里的varchar/char/text、时间类型里的datetime/date/time,我们追求数据运行时表示形式的统一,这样做能最大程度地复用标准处理库,避免重复的开发工作,使项目结构更加简洁。
- 综合以上两者,还要设计高效的序列化/反序列化方式,保证存储和运行形式的转换效率。
- 最后,计算层和存储层的数据结构应尽量一致,避免额外的转换开销
时间类型的例子
在PolarDB-X 1.0中,对于时间类型,选取epoch时间(自1970-01-01 00:00:00 UTC的秒数)来统一表示datetime/timestamp/time/date。当需要执行时间处理函数时,需要将epoch时间转换成具体的年月日、时分秒,其中包含时区转换操作,对性能影响比较大;epoch形式无法控制时间精度;另外,时间处理没有考虑sql mode,无法处理一些特殊的时间值。
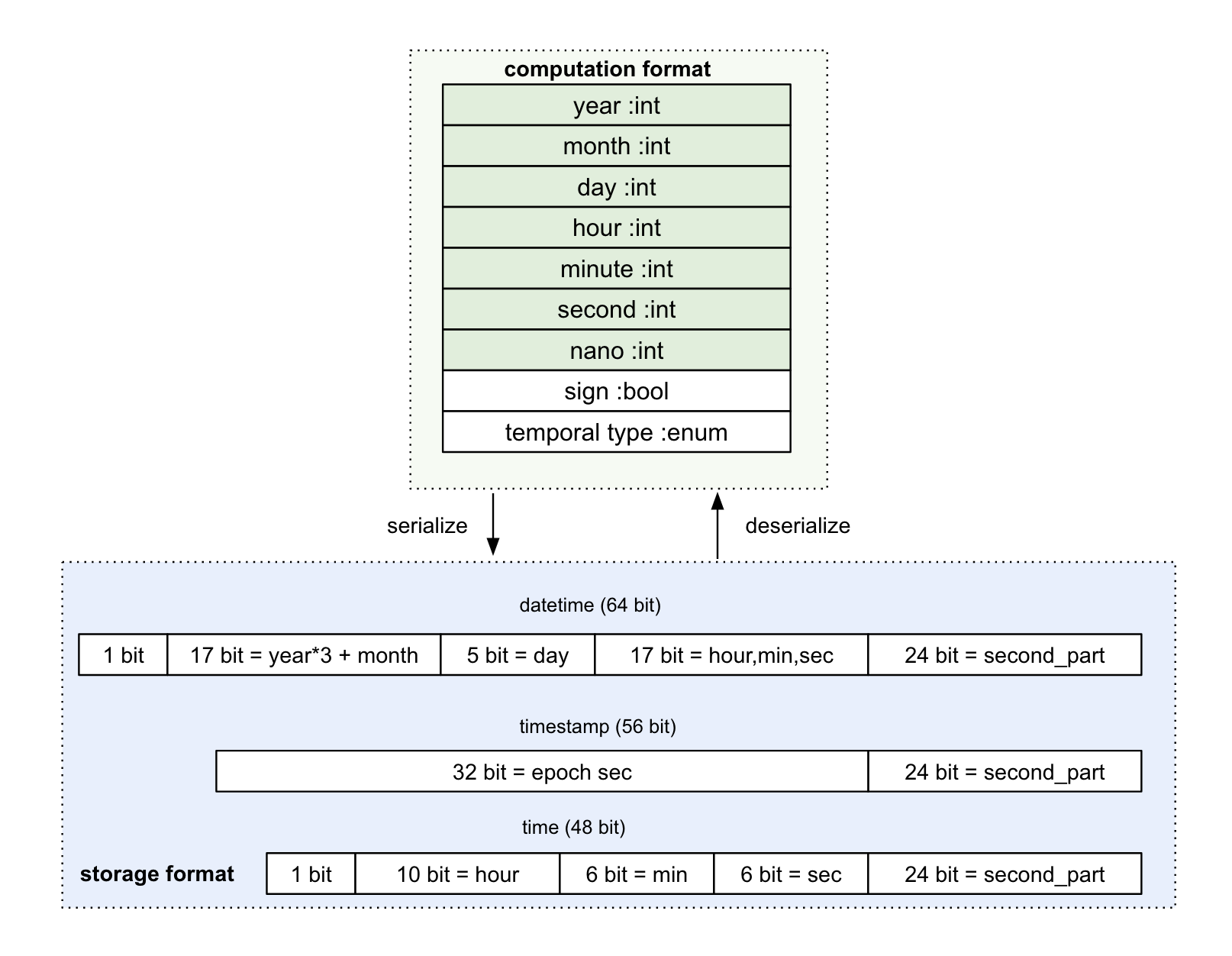
PolarDB-X重构了时间类型,datetime / time / date选取了同样的运行时形式,如下图所示,其中直接包含年月日、时分秒、正负号信息,temporal type用于区分不同的时间类型。对于存储形式,datetime类型采用8字节、time类型采用7字节来存放。而运行时与存储形式间的转换,也可以通过简单的位运算快速进行。
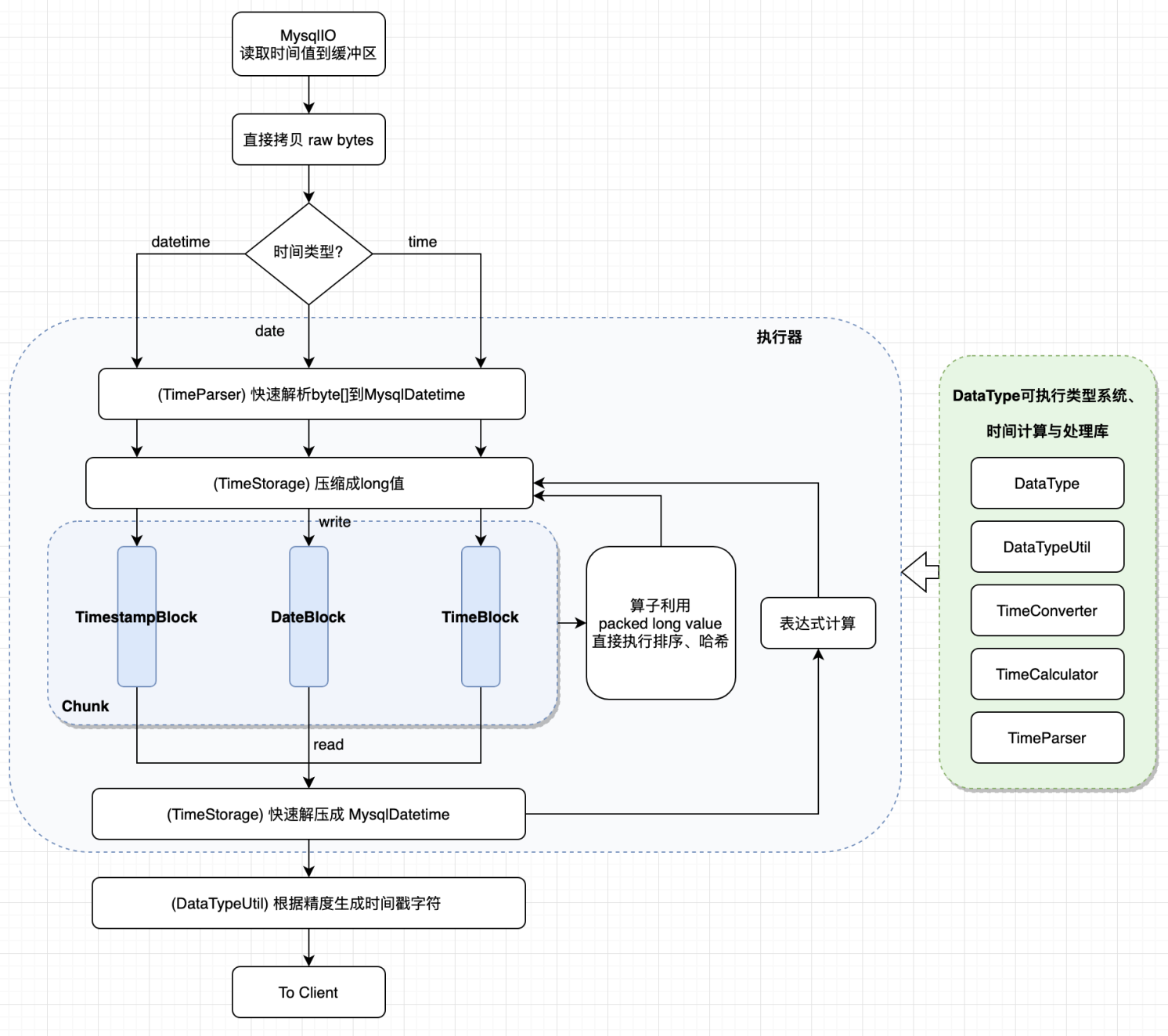
PolarDB-X在上述重构基础之上,设计了新的时间处理库,并重新设计了整个运行链路中时间类型的处理逻辑,包括Chunk存储(下节将会介绍)、算子处理和表达式计算等。
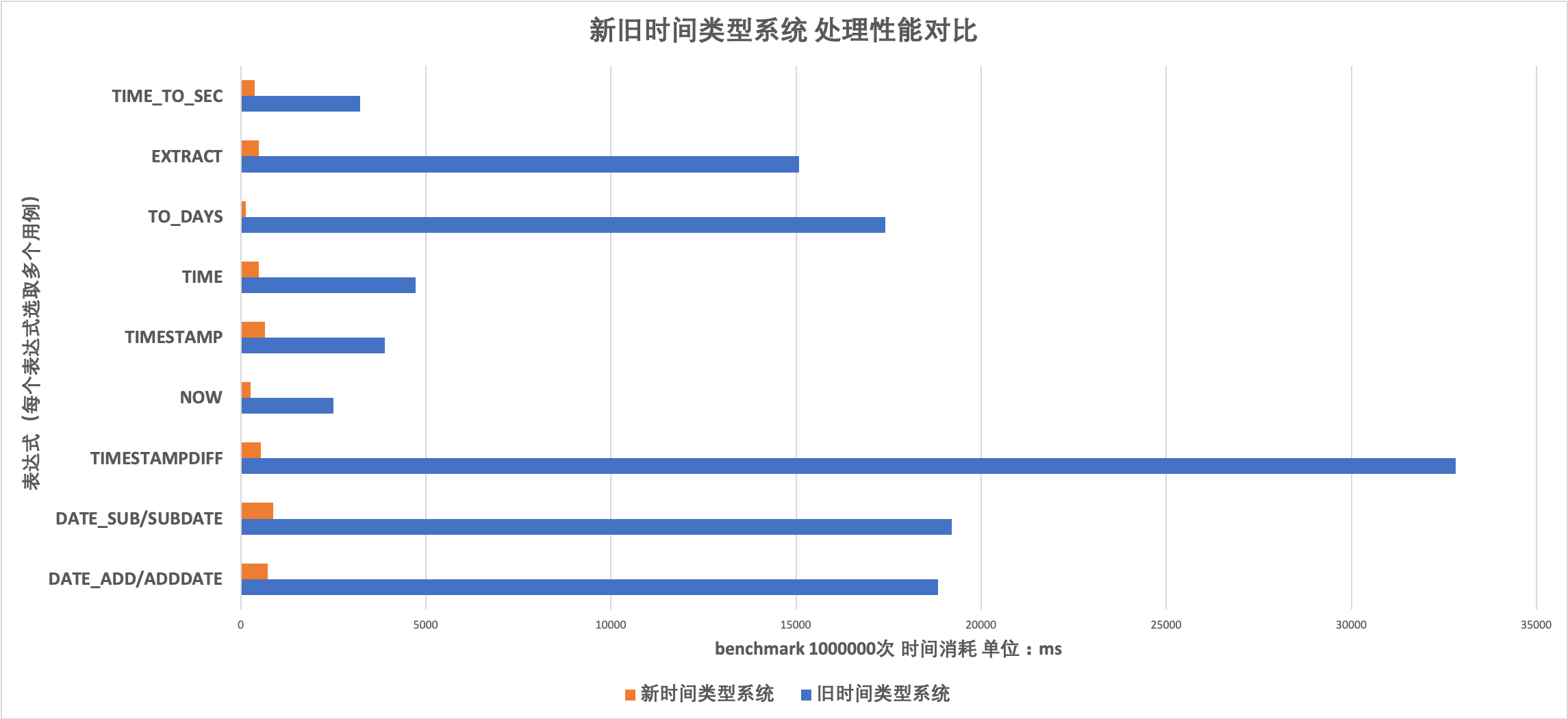
benchmark函数是MySQL提供的一种标准函数,意为将表达式(expr)执行count次。利用benchmark(count, expr)进行时间函数性能对比测试,执行次数count=10^6。性能对比结果如下图所示,其中红色代表新时间类型系统下时间表达式执行的时间,蓝色代表旧时间系统下的执行时间(ms)。
Chunk存储与传输
PolarDB-X利用Chunk在内存中存储数据,供算子和表达式计算使用。在向量化框架中,Chunk会经过简单处理形成向量。Chunk采用列式存储方式将数据组织起来,包含若干个Block,每个Block代表一列数据,支持顺序写入和随机读取。
此外,PolarDB-X还采用私有协议进行计算节点和存储节点间的网络连接,并且利用Chunk传输机制(列存形式)传输数据,避免了行转列的开销;计算层和存储层数据结构几乎一致,进一步避免了类型转换的开销,使得数据传输仅需要简单拷贝。
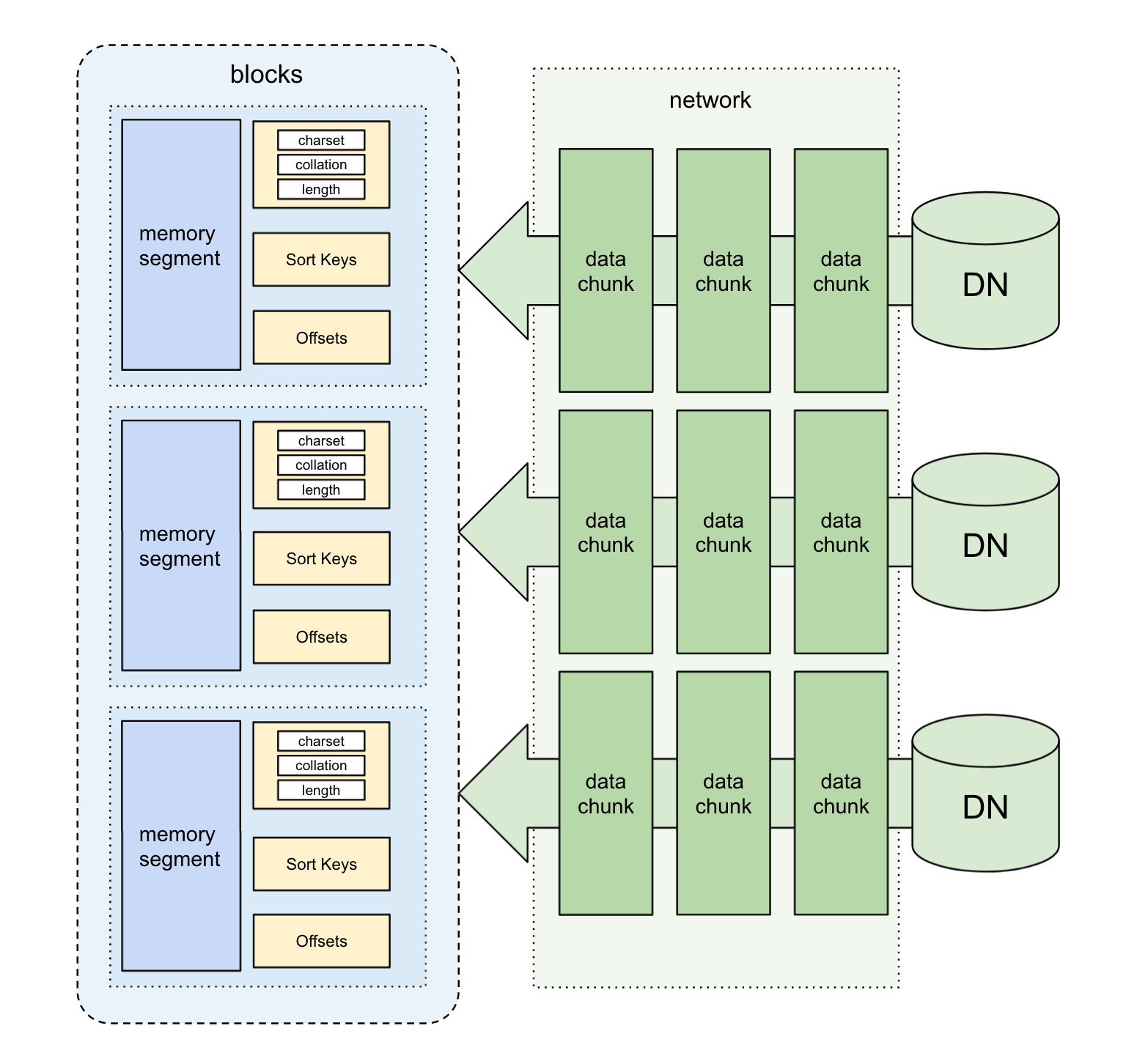
Block基于上文的类型存储形式来组织数据,提供类型特定的hash和compare接口,供Join/Agg/Sort等算子使用。对于定长数据,Block可以直接通过连续的内存区域来存放数据;对于非定长数据,还需要额外的offsets数组记录每个元素的起始位置。
类型的比较运算有时是极其复杂的(见下文Collation章节)。当算子进行频繁的比较操作时(如Sort算子),类型系统提供进一步的优化策略,将数据压缩处理成具有顺序属性的Sort Key(排序键)。排序键是一串等长的字节序列,可以直接通过memcmp进行比较运算。虽然排序键的生成牺牲了一部分时间和空间,但是在排序场景下,能避免比较运算中的复杂逻辑,通过memcmp操作加速比较运算。
在后续的文章中,我们将详细介绍MySQL标准类型数据在PolarDB-X中的存储与运算设计。
Collation
MySQL中的字符类型包括varchar、char、text等,都具有characer set和collation属性。其中characer set(字符集)代表着字符的编码方式,collation代表字符的比较规则。在执行层面,charset和collation会影响到比较、排序、哈希、函数求值的行为。如果类型系统没有完善的collation机制,可以会导致以下后果:
- 排序、比较的结果不符合预期;
- Join运算会出现漏匹配或误匹配的问题;
- Agg运算,没有正确识别相同或者不同的字符串,导致结果错误;
- 函数求值结果错误;
collation在数据库字符处理中处于最核心的地位,一切关于字符串的比较,排序,搜索都依赖collation的处理逻辑。即便一些字符处理不涉及比较操作,也离不开collation ,因为在类型推导时,表达式需要向上层传递准确的collation信息。
UCA算法
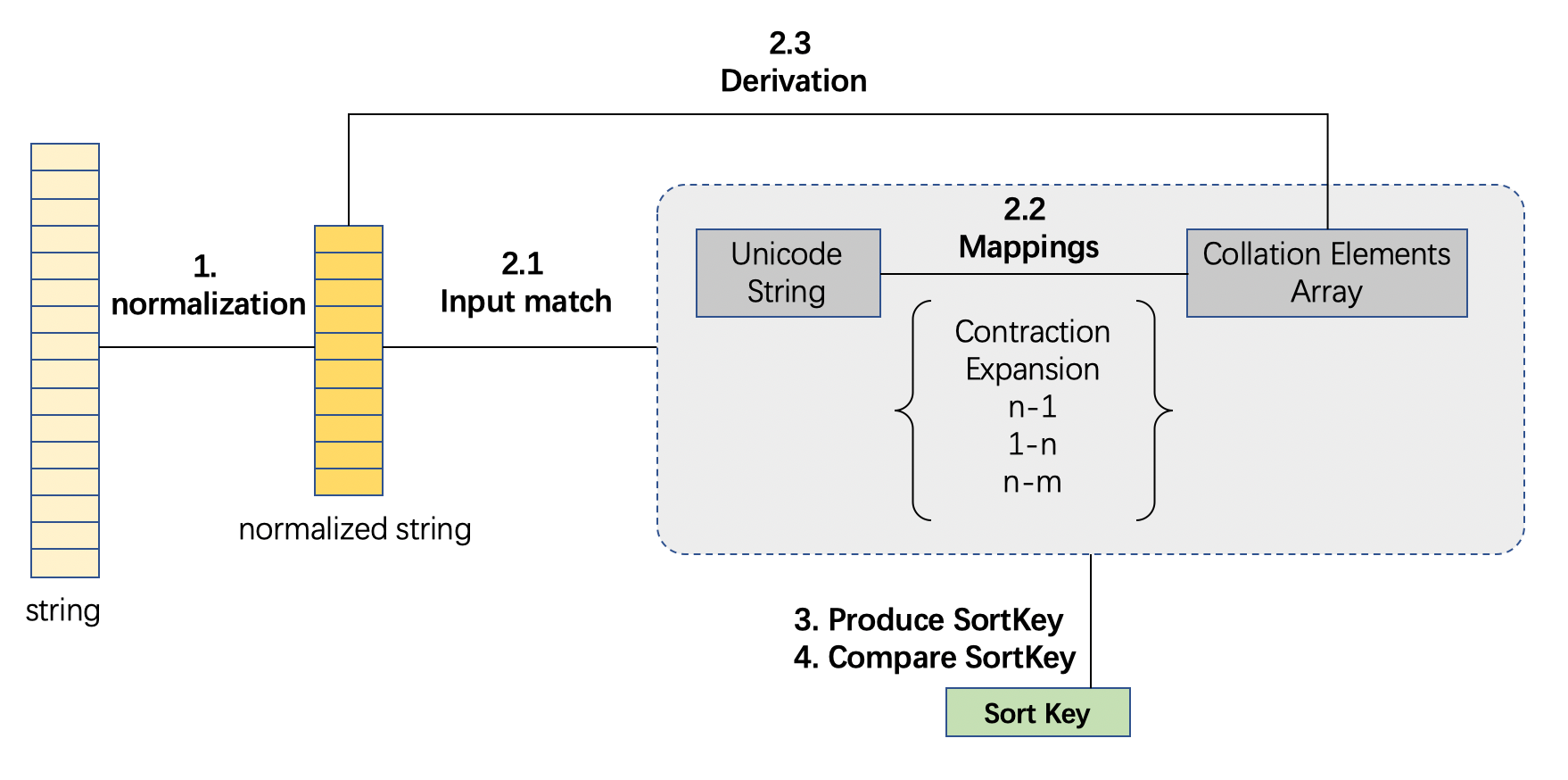
UCA,全称unicode collation algorithm,是unicode编码字符排序的一套算法规范,分为四个部分
- 字符串的规范化处理
- 字符串到collation element array的映射算法
- input match:string piece-by-piece 确定相应的 mapping rule
- mapping rules:unicode - collation elements 映射
- weights derivation 对于无映射存在的字符,需要通过计算获取权重。
- Sort Key生成算法。在上文提到,Sort Key用于应对频繁的比较、排序场景,对比较运算进行加速;
- Sort Key比较算法
各种collation可以依据自己的需要来实现UCA算法规范的各个部分。
PolarDB-X支持20多种collation,并内置了标准的UCA算法实现。例如我们向collation属性为utf8mb4_unicode_ci的列中插入8条字符串(由于明文显示可能会出现乱码,我们这里使用字节的十六进制表示):
insert into test_uca
(pk, v_utf8mb4_unicode_ci)
values
(1, 0x15F19DAAAF4E),
(2, 0xF1AA94A46E1E),
(3, 0xF2BBA4A1F39DB2AFF484B2B60EF0A1AAB7),
(4, 0xF0A98FB5F3A28AB0F2B4AB87F48FB3A6),
(5, 0x6C1F73),
(6, 0x4C000F73111B),
(7, 0x1DF2B998BF04),
(8, 0x02F0A785AD15);
insert into test_uca
(pk, v_utf8mb4_unicode_ci)
values
(1, 0x15F19DAAAF4E),
(2, 0xF1AA94A46E1E),
(3, 0xF2BBA4A1F39DB2AFF484B2B60EF0A1AAB7),
(4, 0xF0A98FB5F3A28AB0F2B4AB87F48FB3A6),
(5, 0x6C1F73),
(6, 0x4C000F73111B),
(7, 0x1DF2B998BF04),
(8, 0x02F0A785AD15);
我们通过hint禁止SQL中部分算子的下推,让collation处理完全在计算层完成,执行一组SQL,得到与MySQL完全一致的结果:
/*+TDDL:ENABLE_PUSH_AGG=false*/select count(distinct v_utf8mb4_unicode_ci) from test_uca;/*+TDDL:ENABLE_PUSH_AGG=false*/select count(distinct v_utf8mb4_unicode_ci) from test_uca;执行count(distinct) 操作,结果为4而非8:

/*+TDDL:ENABLE_PUSH_AGG=false*/select hex(v_utf8mb4_unicode_ci) from test_uca group by v_utf8mb4_unicode_ci order by hex(v_utf8mb4_unicode_ci);/*+TDDL:ENABLE_PUSH_AGG=false*/select hex(v_utf8mb4_unicode_ci) from test_uca group by v_utf8mb4_unicode_ci order by hex(v_utf8mb4_unicode_ci);执行group by + order by 结果显示4条数据,并按collation规则排序:

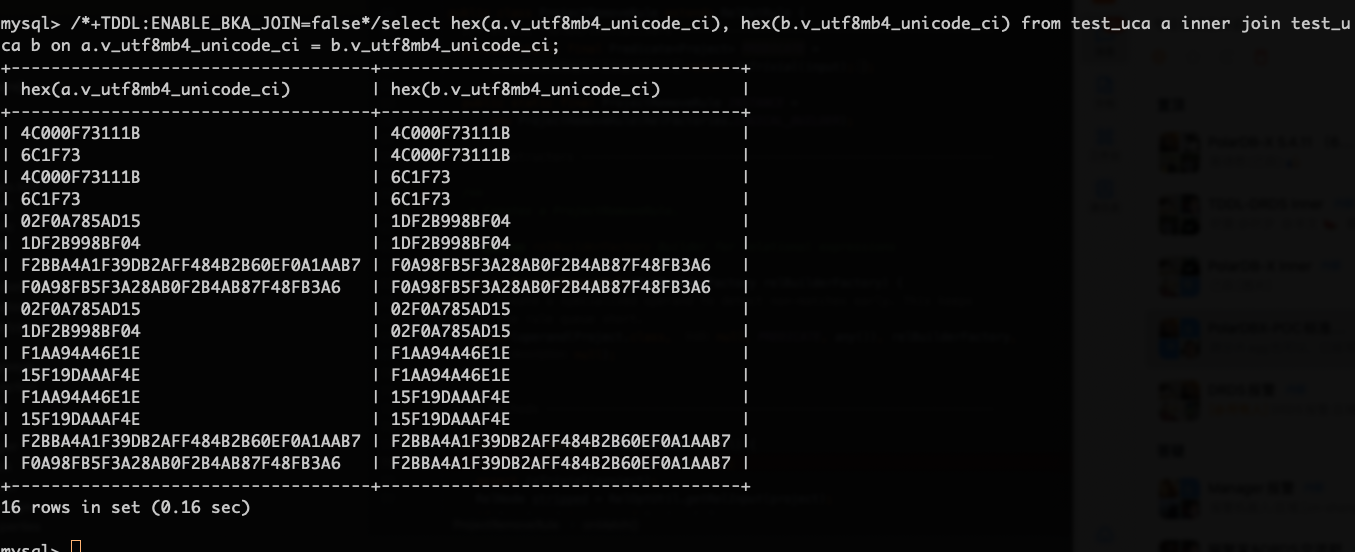
/*+TDDL:ENABLE_BKA_JOIN=false*/select hex(a.v_utf8mb4_unicode_ci), hex(b.v_utf8mb4_unicode_ci) from test_uca a inner join test_uca b on a.v_utf8mb4_unicode_ci = b.v_utf8mb4_unicode_ci;/*+TDDL:ENABLE_BKA_JOIN=false*/select hex(a.v_utf8mb4_unicode_ci), hex(b.v_utf8mb4_unicode_ci) from test_uca a inner join test_uca b on a.v_utf8mb4_unicode_ci = b.v_utf8mb4_unicode_ci;表join自身,可以看到不同字节在语义上相等:
我们会在后续的文章中,继续介绍关于PolarDB-X 字符类型和collation的具体实现。
参考文献
- Type inference in a database programming language.
- A general framework for Hindley/Milner type systems with constraints.
- MySQL Reference, Chapter 10 Character Sets, Collations, Unicode
- UCA(unicode collation algorithm) https://unicode.org/reports/tr10/
- DUCET:https://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt
类型推导机制,用于对SQL做正确的类型推算,向用户呈现出确切的返回类型;更重要的是,指导算子执行、表达式求值时采取正确的行为。在分布式数据库中,类型推导还需要协调存储层与计算层,约定网络传输时的正确类型。
MySQL数据类型通过DDL语句来定义,一列数据的元信息包括精度与长度信息、character set与collation、default value等。元信息约束着类型的处理行为,类型推导需要自顶向下或自底向上地推算和传递元信息。
理论基础
SQL和其他编程语言一样,本质上也是一种计算机语言,其类型系统和推导可以用Hindley–Milner类型理论来表述。例如应用原理(Application)和实例化(Instantiation)原理:
- [App] 如果在上下文Γ中,表达式e0可以从输入类型τ中推得返回类型τ',并且表达式e1具有类型τ,那么e1表达式应用到e2表达式能得到τ'类型;

- [Inst] 如果表达式e具有类型σ‘ ,且类型σ’ 是 σ的子类型,我们可以推知e具有类型σ

把上述理论应用在数据库的关系代数中,又可以得到一组推论,例如,
- 如果表达式e1和e2分别具有类型τ1和τ2,且两种类型没有公共子类型,则e1和e2的笛卡尔积返回类型是类型τ1和τ2的并集:

两种流派
和学院派的PostgreSQL不同,MySQL对于用户SQL是极其宽容的,函数可以随意堆叠在一起,数据插入也几乎不会进行类型限制。从根源上讲,这种差异是PostgreSQL和MySQL在类型推导上的设计不同所造成的。
PostgreSQL的内部设计以规范和优雅而著称。以PostgreSQL生态下的分布式数据库CockroachDB为例,对于用户传来的一条insert语句
INSERT INTO float_col VALUES (SQRT(ABS(-3.5)));INSERT INTO float_col VALUES (SQRT(ABS(-3.5)));CockroachDB会自顶向下地传递上层算子所需要的数据类型,直到最底部的叶子节点。如果在传递过程中,某些算子、表达式与想要的类型不符,则会报类型推导错误,并拒绝SQL执行。
与CockroachDB的Top-Down推导方式不同,MySQL使用了Bottom-Up(自底向上)的推导方式。下面这条SQL在MySQL里可以正常执行,在PostgreSQL下将会被拒绝:
insert into t (datetime_col) values (concat('20201212', '121200' + 12));insert into t (datetime_col) values (concat('20201212', '121200' + 12));MySQL会从叶节点开始自底向上地推导类型,每个父节点会先确认子节点的类型,来决定自身的返回类型。类型推导的限制是十分宽容的,字符类型可以作为加法的输入,用于拼接字符串的concat表达式也能接受整数类型。甚至对于最终要写入的datetime类型字段,也容许将concat拼接的字符串转换解析为时间类型数值。

MySQL过于宽容的类型推导方式,意味着在实际计算时需要引入大量的隐式类型转换。在MySQL行式执行模式中,每个表达式(Item_func)提供了val_int / val_str / val_date等不同的接口,上层表达式根据自身实现的需求,调用下层表达式相应的接口,从而获取相应的处理类型。隐式类型转换往往就发生在特定类型接口的调用过程中。这种隐式类型转换是非形式化的,它隐藏着函数实现的代码逻辑中,没有明确的规律,并且伴随着表达式执行额外的指令开销。
而在以列式执行为主的分布式数据库中,表达式之间以Chunk或者向量的形式传递数据,多余的操作需要被独立出来进行规范化的处理,从而提升表达式运算效率,也让代码更加简洁和优雅。
PolarDB-X类型推导与隐式类型转换
PolarDB-X 用更加模块化、结构化的方式,复现了MySQL类型推导和隐式转换的规则,达到了与MySQL高度兼容的效果,PolarDB-X将用户传来的SQL解析为AST之后,将对每个表达式节点依次进行操作数类型检查、隐式类型转换和返回类型推导,具体过程包括:
- 操作数类型检查(Operand Type Checker)。子表达式的返回类型,会作为父表达式的操作数类型。每个表达式配备有相应的操作数类型检查规则,通过此规则来检查操作数类型是否合法;
- 隐式类型转换(Type Coercion)。当子表达式的返回类型不能成为合法的父表达式操作数类型时,我们需要调用相应的类型转换规则,尝试进行返回值类型return type到操作数类型operand type的转换。办法是,生成一个合法的IMPLICIT_CAST表达式,将return type强制转换为合法的operand type类型。由于此转换对于用户来说是透明的,所以称为隐式类型转换。
- 返回值类型推导(Return Type Inference)。当表达式具备了合法的操作数之后,可以调用相应的返回值推导规则,通过操作数推出正确的返回值类型。
以上三个步骤如下图所示:

类型存储与计算
设计原则
类型的表示决定了数据的存储和运算方式。对于同一种类型,其存储和运算时的表示形式又是有差异的。
- 在设计类型存储时,我们关心如何节省空间、提高存储效率,并且让字节连续、对齐,以便于内存分配,也有利于CPU cache预取;
- 运行时类型表示的设计目标是提升计算性能。特别的,对于大类别下的小类型,如字符类型里的varchar/char/text、时间类型里的datetime/date/time,我们追求数据运行时表示形式的统一,这样做能最大程度地复用标准处理库,避免重复的开发工作,使项目结构更加简洁。
- 综合以上两者,还要设计高效的序列化/反序列化方式,保证存储和运行形式的转换效率。
- 最后,计算层和存储层的数据结构应尽量一致,避免额外的转换开销
时间类型的例子
在PolarDB-X 1.0中,对于时间类型,选取epoch时间(自1970-01-01 00:00:00 UTC的秒数)来统一表示datetime/timestamp/time/date。当需要执行时间处理函数时,需要将epoch时间转换成具体的年月日、时分秒,其中包含时区转换操作,对性能影响比较大;epoch形式无法控制时间精度;另外,时间处理没有考虑sql mode,无法处理一些特殊的时间值。
PolarDB-X重构了时间类型,datetime / time / date选取了同样的运行时形式,如下图所示,其中直接包含年月日、时分秒、正负号信息,temporal type用于区分不同的时间类型。对于存储形式,datetime类型采用8字节、time类型采用7字节来存放。而运行时与存储形式间的转换,也可以通过简单的位运算快速进行。

PolarDB-X在上述重构基础之上,设计了新的时间处理库,并重新设计了整个运行链路中时间类型的处理逻辑,包括Chunk存储(下节将会介绍)、算子处理和表达式计算等。

benchmark函数是MySQL提供的一种标准函数,意为将表达式(expr)执行count次。利用benchmark(count, expr)进行时间函数性能对比测试,执行次数count=10^6。性能对比结果如下图所示,其中红色代表新时间类型系统下时间表达式执行的时间,蓝色代表旧时间系统下的执行时间(ms)。

Chunk存储与传输
PolarDB-X利用Chunk在内存中存储数据,供算子和表达式计算使用。在向量化框架中,Chunk会经过简单处理形成向量。Chunk采用列式存储方式将数据组织起来,包含若干个Block,每个Block代表一列数据,支持顺序写入和随机读取。
此外,PolarDB-X还采用私有协议进行计算节点和存储节点间的网络连接,并且利用Chunk传输机制(列存形式)传输数据,避免了行转列的开销;计算层和存储层数据结构几乎一致,进一步避免了类型转换的开销,使得数据传输仅需要简单拷贝。

Block基于上文的类型存储形式来组织数据,提供类型特定的hash和compare接口,供Join/Agg/Sort等算子使用。对于定长数据,Block可以直接通过连续的内存区域来存放数据;对于非定长数据,还需要额外的offsets数组记录每个元素的起始位置。
类型的比较运算有时是极其复杂的(见下文Collation章节)。当算子进行频繁的比较操作时(如Sort算子),类型系统提供进一步的优化策略,将数据压缩处理成具有顺序属性的Sort Key(排序键)。排序键是一串等长的字节序列,可以直接通过memcmp进行比较运算。虽然排序键的生成牺牲了一部分时间和空间,但是在排序场景下,能避免比较运算中的复杂逻辑,通过memcmp操作加速比较运算。
在后续的文章中,我们将详细介绍MySQL标准类型数据在PolarDB-X中的存储与运算设计。
Collation
MySQL中的字符类型包括varchar、char、text等,都具有characer set和collation属性。其中characer set(字符集)代表着字符的编码方式,collation代表字符的比较规则。在执行层面,charset和collation会影响到比较、排序、哈希、函数求值的行为。如果类型系统没有完善的collation机制,可以会导致以下后果:
- 排序、比较的结果不符合预期;
- Join运算会出现漏匹配或误匹配的问题;
- Agg运算,没有正确识别相同或者不同的字符串,导致结果错误;
- 函数求值结果错误;
collation在数据库字符处理中处于最核心的地位,一切关于字符串的比较,排序,搜索都依赖collation的处理逻辑。即便一些字符处理不涉及比较操作,也离不开collation ,因为在类型推导时,表达式需要向上层传递准确的collation信息。
UCA算法
UCA,全称unicode collation algorithm,是unicode编码字符排序的一套算法规范,分为四个部分
- 字符串的规范化处理
- 字符串到collation element array的映射算法
- input match:string piece-by-piece 确定相应的 mapping rule
- mapping rules:unicode - collation elements 映射
- weights derivation 对于无映射存在的字符,需要通过计算获取权重。
- Sort Key生成算法。在上文提到,Sort Key用于应对频繁的比较、排序场景,对比较运算进行加速;
- Sort Key比较算法
各种collation可以依据自己的需要来实现UCA算法规范的各个部分。

PolarDB-X支持20多种collation,并内置了标准的UCA算法实现。例如我们向collation属性为utf8mb4_unicode_ci的列中插入8条字符串(由于明文显示可能会出现乱码,我们这里使用字节的十六进制表示):
insert into test_uca
(pk, v_utf8mb4_unicode_ci)
values
(1, 0x15F19DAAAF4E),
(2, 0xF1AA94A46E1E),
(3, 0xF2BBA4A1F39DB2AFF484B2B60EF0A1AAB7),
(4, 0xF0A98FB5F3A28AB0F2B4AB87F48FB3A6),
(5, 0x6C1F73),
(6, 0x4C000F73111B),
(7, 0x1DF2B998BF04),
(8, 0x02F0A785AD15);
insert into test_uca
(pk, v_utf8mb4_unicode_ci)
values
(1, 0x15F19DAAAF4E),
(2, 0xF1AA94A46E1E),
(3, 0xF2BBA4A1F39DB2AFF484B2B60EF0A1AAB7),
(4, 0xF0A98FB5F3A28AB0F2B4AB87F48FB3A6),
(5, 0x6C1F73),
(6, 0x4C000F73111B),
(7, 0x1DF2B998BF04),
(8, 0x02F0A785AD15);
我们通过hint禁止SQL中部分算子的下推,让collation处理完全在计算层完成,执行一组SQL,得到与MySQL完全一致的结果:
/*+TDDL:ENABLE_PUSH_AGG=false*/select count(distinct v_utf8mb4_unicode_ci) from test_uca;/*+TDDL:ENABLE_PUSH_AGG=false*/select count(distinct v_utf8mb4_unicode_ci) from test_uca;执行count(distinct) 操作,结果为4而非8:

/*+TDDL:ENABLE_PUSH_AGG=false*/select hex(v_utf8mb4_unicode_ci) from test_uca group by v_utf8mb4_unicode_ci order by hex(v_utf8mb4_unicode_ci);/*+TDDL:ENABLE_PUSH_AGG=false*/select hex(v_utf8mb4_unicode_ci) from test_uca group by v_utf8mb4_unicode_ci order by hex(v_utf8mb4_unicode_ci);执行group by + order by 结果显示4条数据,并按collation规则排序:

/*+TDDL:ENABLE_BKA_JOIN=false*/select hex(a.v_utf8mb4_unicode_ci), hex(b.v_utf8mb4_unicode_ci) from test_uca a inner join test_uca b on a.v_utf8mb4_unicode_ci = b.v_utf8mb4_unicode_ci;/*+TDDL:ENABLE_BKA_JOIN=false*/select hex(a.v_utf8mb4_unicode_ci), hex(b.v_utf8mb4_unicode_ci) from test_uca a inner join test_uca b on a.v_utf8mb4_unicode_ci = b.v_utf8mb4_unicode_ci;表join自身,可以看到不同字节在语义上相等:

我们会在后续的文章中,继续介绍关于PolarDB-X 字符类型和collation的具体实现。
参考文献
- Type inference in a database programming language.
- A general framework for Hindley/Milner type systems with constraints.
- MySQL Reference, Chapter 10 Character Sets, Collations, Unicode
- UCA(unicode collation algorithm) https://unicode.org/reports/tr10/
- DUCET:https://www.unicode.org/Public/UCA/4.0.0/allkeys-4.0.0.txt
