




点击蓝字 关注我们
大家下午好,我是来自腾讯音乐的杜延龙,在公司中,主要负责数据中台产品的研发工作。这篇文章主要是基于Apache DolphinScheduler架构,面向TME企业管理域数据的开发、测试、项目管理发布、运维流程一体化实践,希望对你有帮助!
文|杜延龙
编辑整理| 曾辉
讲师介绍

杜延龙
腾讯音乐大数据
需求背景
在使用 Apache DolphinScheduler 之前,我们每天有超过上千任务在运行,数据量也达到了TB级别。

在原有的调度方案中,我们主要使用 Crontab 和 Airflow,任务类型包括自定义程序、数据集成的 DataX 作业和 SQL 任务。
在开发方面,需要基于 Crontab 和 Airflow 具备一定的开发技能,并安装各种集成开发环境(IDE)。
不同开发环境之间的差异需要额外的调整时间,导致开发周期延长,代码维护成本也逐渐增加。
此外,数据源信息都是以代码形式进行维护,这给代码安全和数据源安全带来了挑战。在测试方面,测试人员需要深入代码进行测试,效率相对较低。
运维和监控方面,无论是 Crontab 还是 Airflow,都缺乏全流程的监控能力。

此外,代码管理和团队管理方面也存在困难。在发布过程中,所有的数据开发工作都是基于代码进行的,配置内容增多会导致人为失误和线上 bug 的增加,这是可以避免的。
产品选型
基于这些问题,我们决定构建一个统一的数据开发平台。

在选型过程中,我们考虑了以下几个产品的性能和功能:
Airflow
Oozie
Taier
Azkaban
DolphinScheduler
Airflow 和 Oozie 都需要编码工作,如编写 Python 代码或 XML 配置。
近年来,Azkaban 社区活跃度较低,并存在一些问题。
Taier 是一个新的项目,但稳定性较弱,并且在验证过程中发现了一些业务问题。
最终,我们选择了 Apache DolphinScheduler,因为它具有较为活跃的社区、丰富的功能扩展性和文档支持。
功能拓展与改造
我们选择 Apache DolphinScheduler 之后进行了二次开发,主要集中在以下几个方面。
业务版本管理
首先是业务版本管理,原有的版本管理无法满足我们的业务需求。
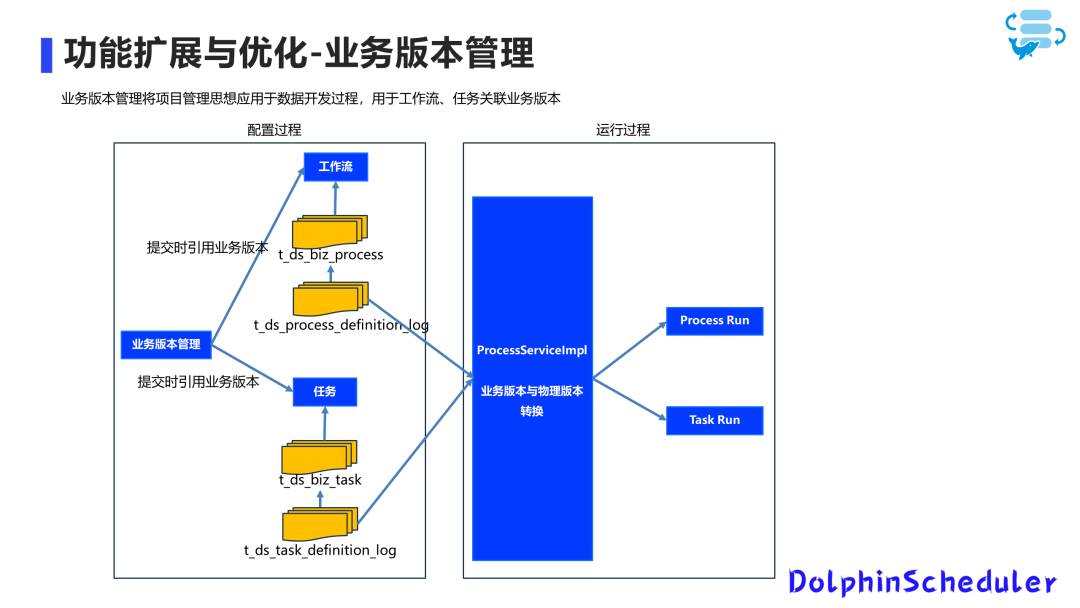
我们建立了一个独立的业务版本管理功能,每次新迭代开发时,在这里维护一个新的业务版本。在创建或编辑任务和工作流时,如果是开发过程中的编辑,我们将其保存在草稿箱中,不会提交到业务版本。
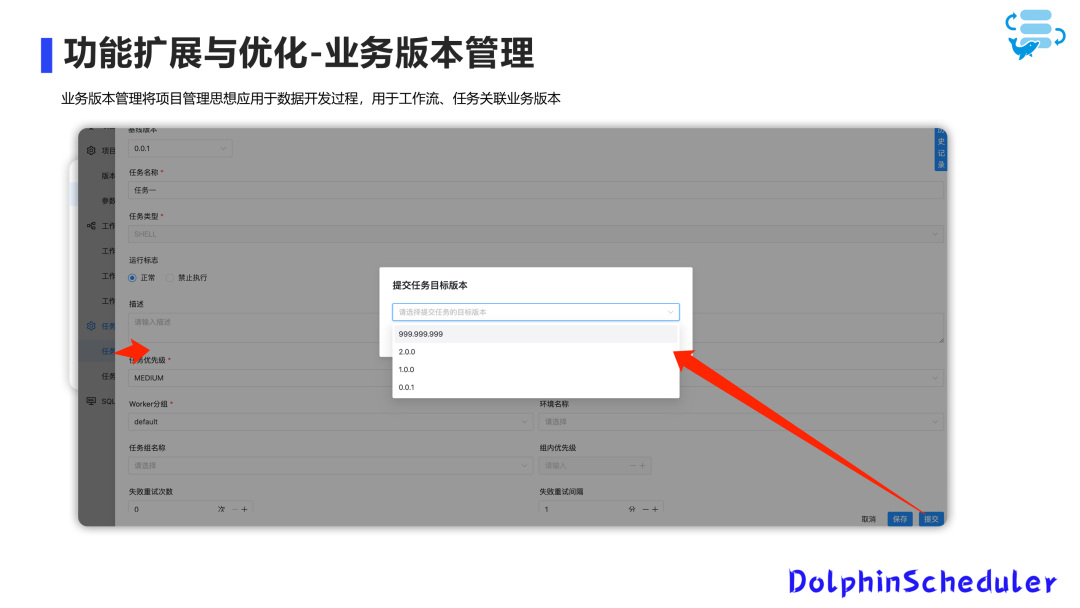
在发布之前,我们可以将工作流或任务提交到具有业务含义的业务版本上,并建立与底层的工作流和任务定义表的映射关系。在运行过程中,我们将业务版本转换为物理版本,并进行执行和展示。
这样,我们在提交时可以选择具有业务含义的版本。
优化发布过程
我们发现原有的导出导入功能在开发、测试和生产环境中的发布过程中存在问题。做了适配之后,将测试环境中的资源ID转换为名称,并在导出的工作流 JSON 中进行导出。
在新环境中进行导入时,再将这些名称适配为新环境的资源ID。
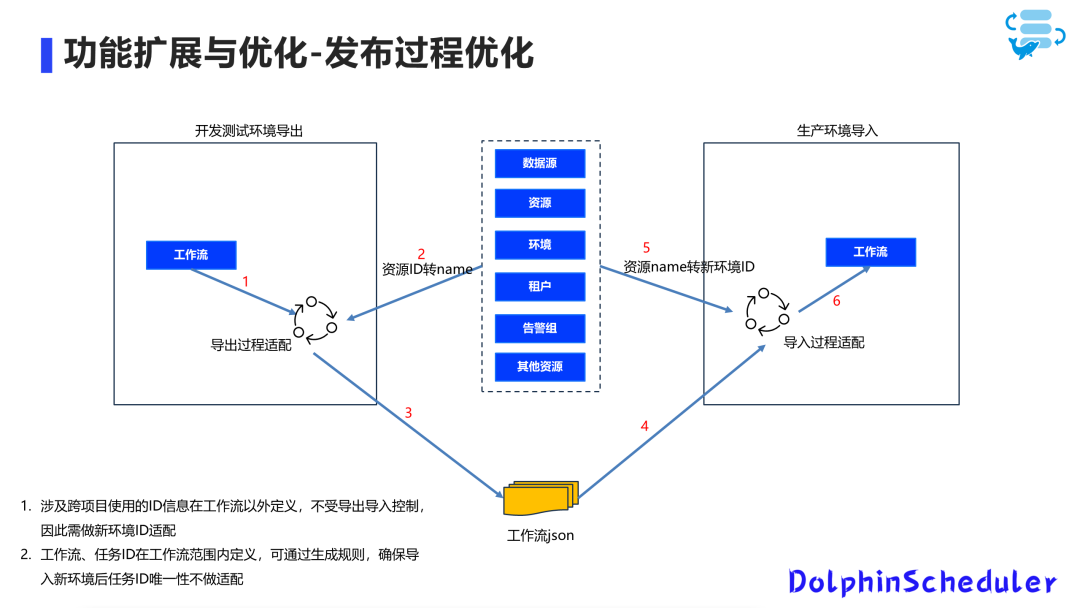
这样,导入后的工作流可以直接使用,避免了跨环境发布后资源无法找到。
数据探索功能
在项目开发和测试过程中,通常需要在不同的数据源和工具之间切换,差异化环境给开发带来了一定负担。为了解决这个问题,我们将数据探索功能集成到 Apache DolphinScheduler 中。
开发人员可以直接在平台上选择数据源类型和对应的数据源信息,并进行 SQL 编辑和测试运行。执行完毕后,结果会进行展示。
未来,我们还计划将 SQL 直接生成作业的功能加入平台。
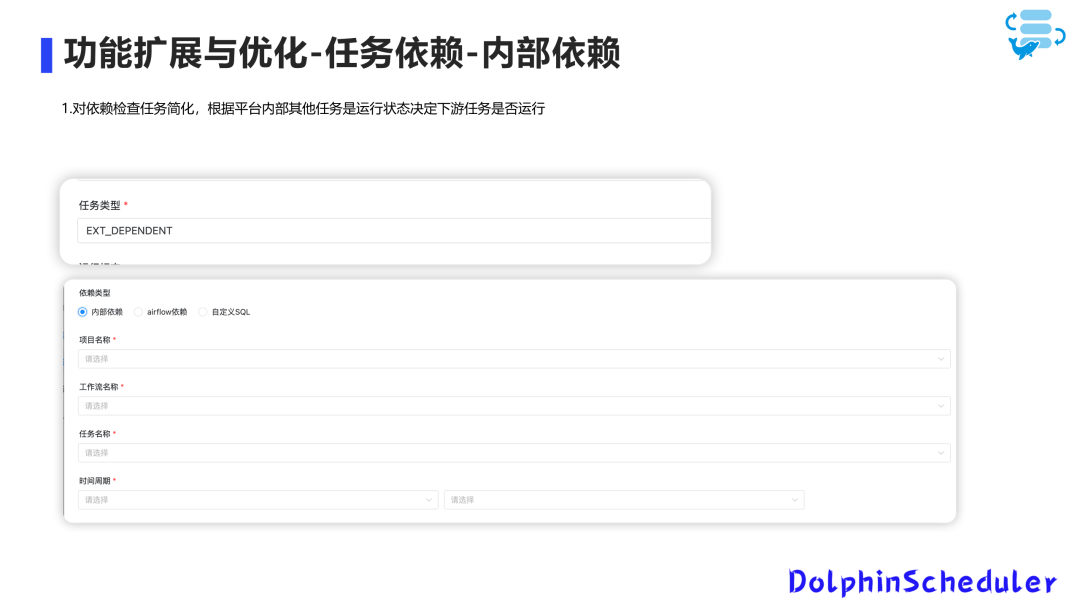
任务依赖
我们对开源版本进行了定制化改造。除了常见的任务依赖,我们加入了三种特定的依赖类型。首先是内部依赖,针对平台内部的跨项目指定工作流任务是否完成。
其次,我们支持检查 Airflow 任务的运行情况,将 Airflow 的数据源注册到平台,并检查同一周期内的任务是否完成。

最后,我们支持数据依赖,可以通过编写 SQL 检查业务系统数据的状态是否满足运行条件。
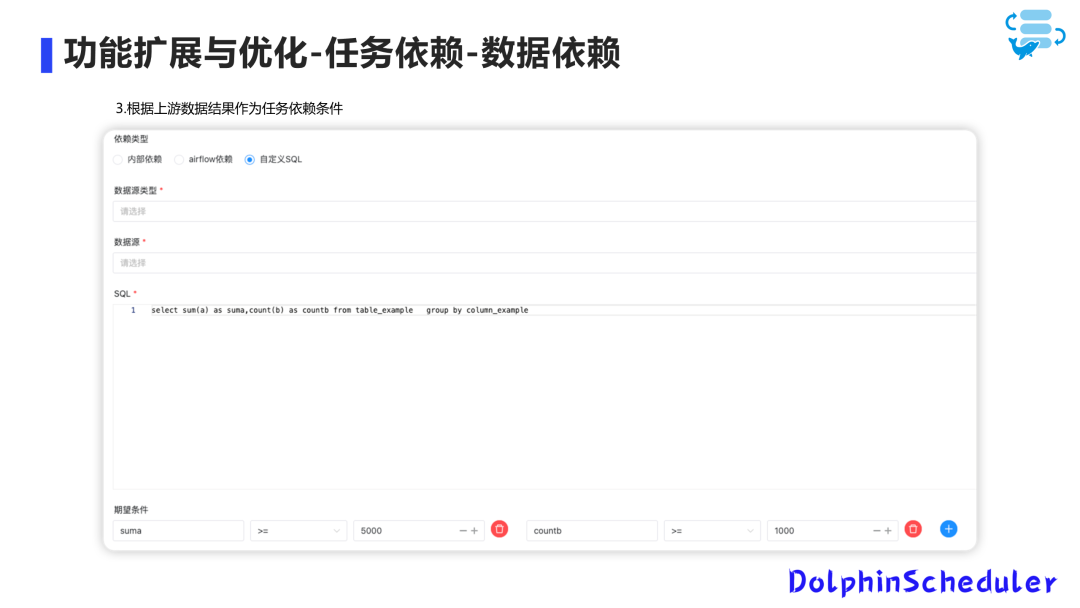
为了满足业务需求,我们将任务的创建从工作流中拆分出来,任务可以脱离工作流单独创建,修改后,任务可以单独创建和编辑,开发人员确认无误后,将其关联到工作流中。
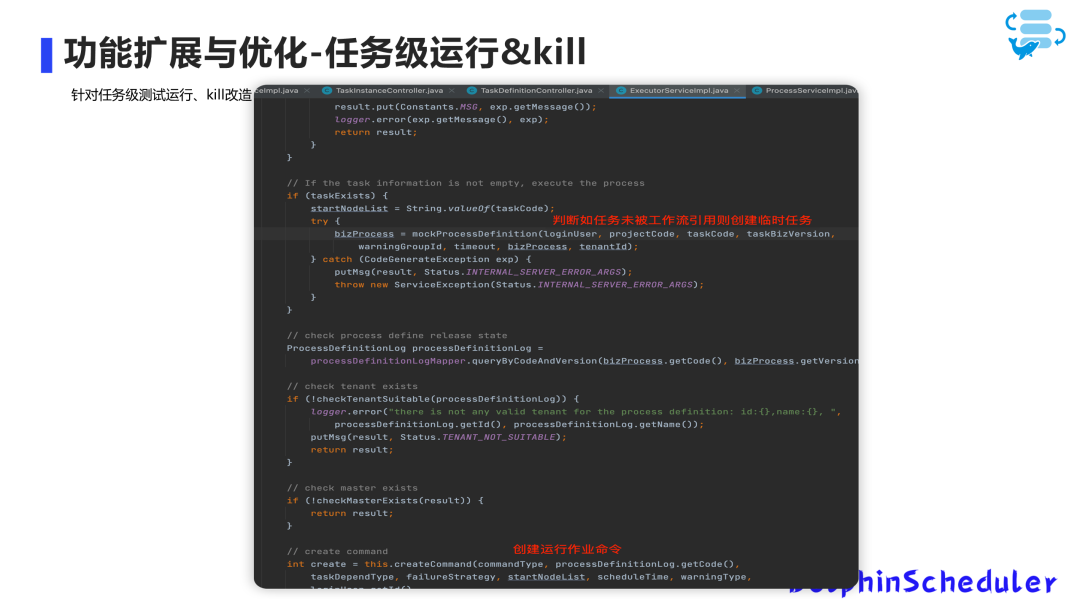
这时因为任务还未加入工作流,无法独立运行,这时会自动创建一个虚拟工作流来运行任务,并在前端展示时做了筛选,避免虚拟工作流实例显示在界面上。
此外,程序会定期清理虚拟工作流实例,避免对性能造成影响。
全链路监控
通过 Apache DolphinScheduler 平台,可以查看工作流和任务实例运行过程的基础监控;
但针对一些特殊场景时监控不到的,如平台挂掉时未及时调起的高优先级任务或执行时间超长的任务。
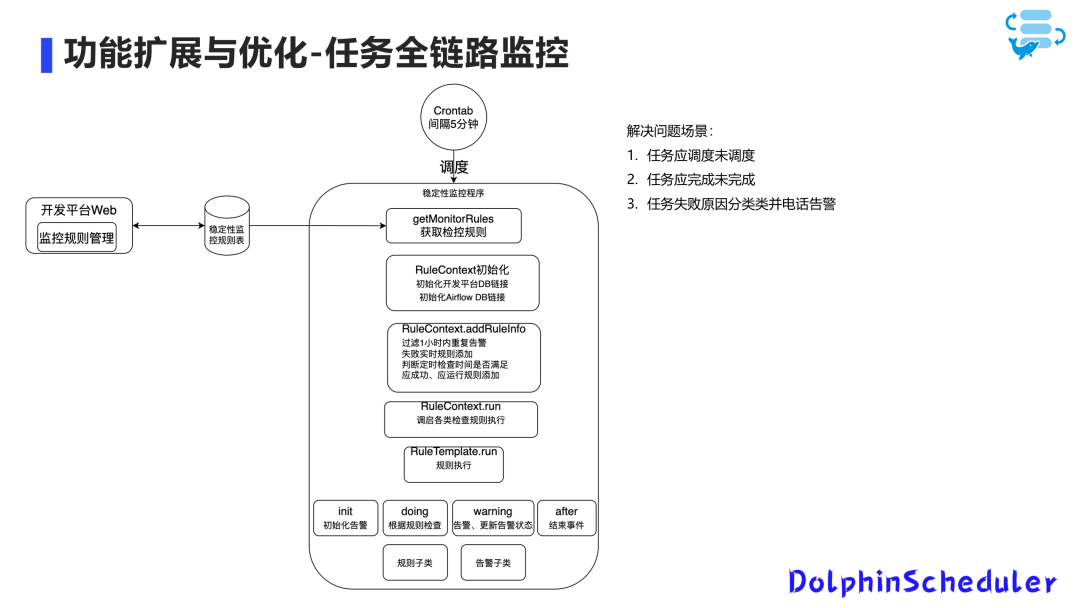
我们开发了一些小工具,对 DS 和 Airflow 进行监控,包括应调度未调度、应完成未完成和失败实时告警等监控场景的补充。
任务异常分类
在开发过程中任务遇到异常时,我们通常需要查看任务运行日志、结合 DolphinScheduler 的日志和其他工具(如 Yarn 和 Starrocks)的日志来排查问题。
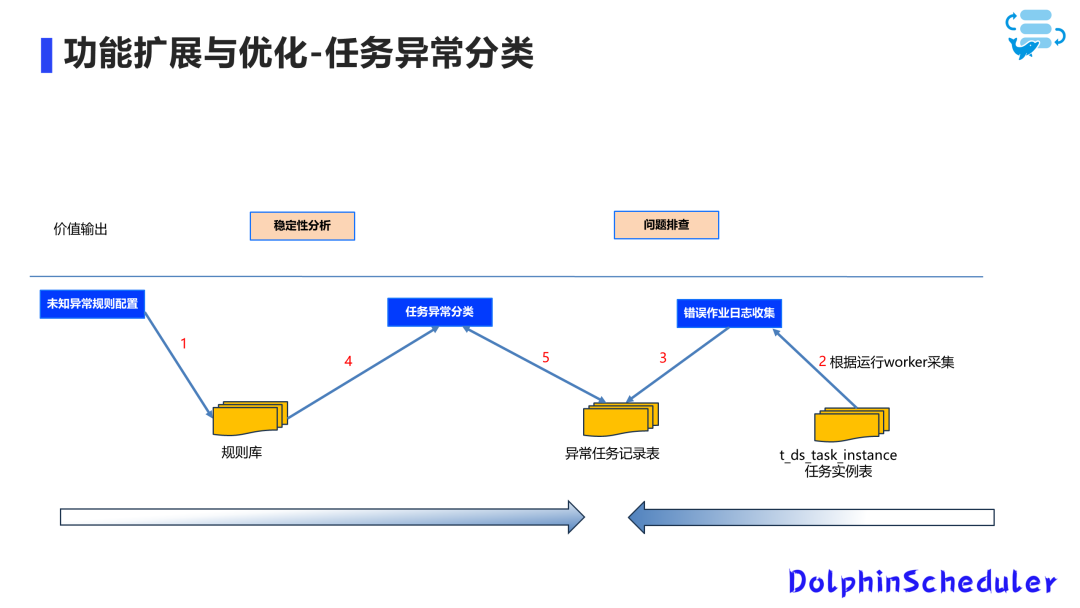
然而,这个过程需要查看大量的日志,并且需要逐个任务进行定位和排查,效率较低。
为了解决这个问题,我们建立了一个规则库,用于记录运行错误的任务日志,并将其分类保存在任务异常表中。通过程序对这些日志按照规则进行分类,为每个任务添加异常原因和分类标记。基于这些数据,我们可以提供相应的异常分析报告、平台运营看板、异常定位等。
此外,针对工作流和任务的多人编辑问题,我们引入了锁机制,确保同一时间只有一个人可以编辑或提交。
另外,我们改进了资源上传编辑的流程,避免了对多个任务逐一修改资源的繁琐操作。
数据源安全管理
我们将数据源的密码放置在密码服务中,而非本地存储,以确保数据源密码的安全性。
此外,我们还进行了其他数据源扩展和元数据采集的工作。
通过元数据采集的 SDK,我们可以创建数据采集作业并指定要采集的数据源和范围,并配置定时周期进行采集。
我们还进行了一些 bug 修复,例如修复了 SQL 文件中逗号分号分割的 SQL 的支持等。
04
未来规划

我们计划进一步改进数据探索功能。
例如,为每个用户提供个性化的 SQL 执行记录和差异展示,并以目录形式进行分类管理。
此外,我们还计划实现一键式生成作业和图标的功能,以及引入 Flink SQL 来支持实时数据开发。

我们还计划引入Git 管理 SQL、针对跨环境的工作流参数替换、数据同步支持按库同步等。
构建数据质量。届时可以将数据质量规则来作为开发任务的前后置检查条件,根据质量规则运行结果熔断下游作业。
同时,我们还将关注运营方面的改进,例如跨环境的发布流程优化,考虑将导出和导入结合成一步直接发布到指定环境。

参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds,好友申请注明“入交流群+姓名+公司+职位信息“,群里是实名制,仅用于验证身份)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。

