





接上一篇《SQL Server 线程体系结构(一)》
我们来理解等待类型 CXPACKET 与 SOS_SCHEDULER_YIELD 是如何形成的、有什么影响。
当SQL Servser 实例中设置并行度 max degree of parallelism 不等于1时,SQL请求有可能触发并行任务处理,而等待类型 CXPACKET 将是比较常见的。
CXPACKET(Class eXchange Packets)当触发并行任务运行使用多个线程来执行查询时,就会发生这种等待类型。一般来说,CXPACKET等待类型对于SQL Server来说是正常的,它表明SQL Server在执行查询时使用并行计划,这通常比在串行进程中执行的查询更快。当使用并行计划时,查询在多个线程中执行,只有当所有并行线程都完成时查询才能继续。这意味着影响查询的是最慢的那个线程。
EXEC SP_CONFIGURE 'max degree of parallelism',2RECONFIGURE WITH OVERRIDEGO
上一篇文章,设置的最大并发数为2,当并发线程访问表Sales.SalesOrderDetail时,2个线程将对表进行扫描读取数据,各使用一个CPU进行处理。
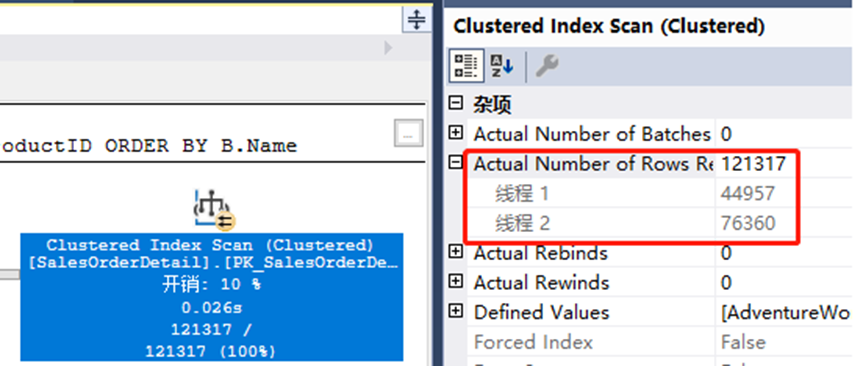
上图可以看到,线程1读取了44957行,线程2读取了776360行。假设线程1处理比较快,当线程1处理完成后,线程2还在继续扫描数据。这时线程1将等待线程2完成,即出现了等待类型 CXPACKET。只有当线程2完成后,当前对该表的查询请求才是真正完成。

出现这种情况,可能是某些资源影响了线程的访问,如堵塞、延迟等,所以也会伴随其他类型的等待。我们可以对当前系统在线访问查看,此时是什么类型(原因)导致CXPACKET出现。
CXPACKET 在并行形成系统中出现并不奇怪,当然也可使用其他方法进行优化。
不要将 MAXDOP 设置为 1,这不是好的解决方案;
跟踪检查CXPACKET出现情况,了解系统是频繁出现还是偶尔出现;
检查并更新统计信息,确保执行计划是最优的;
控制好 cost threshold for parallelism 的值;
优化索引与SQL语句;
关于最大并行度(max degree of parallelism)的设置:
MAXDOP 不建议于大于8,且不能大于单个 NUMA 中的逻辑 CPU 数量,因为CPU 跨 NUMA 节点处理内存数据相对缓慢并可能冲突。同样的,Tempdb 的文件数不建议大于 MAXDOP。
等待类型 SOS_SCHEDULER_YIELD
SOS_SCHEDULER_YIELD,顾名思义,即让出SOS 中的Scheduler,指线程执行其完整线程量(4毫秒),放弃Scheduler,移至其Scheduler中可运行队列的底部处于RUNNABLE状态,系统注册等待类型为SOS_SCHEDULER_YIELD。
等待类型 SOS_SCHEDULER_YIELD 可以说是我们最常见的等待类型了。SQL Server 大部分时间都以非抢占模式运行,这意味着线程是协作的,并且可以通过让出自身来给其他线程运行。当任何线程为另一个线程让出自己占有的 Scheduler 时,它就会创建此等待类型。因此,如果线程过多,也间接表明CPU有压力。
调度程序中的线程为以下三种状态之一:
RUNNING:线程正在处理器上运行,每个处理器同时只能有一个线程处于活动状态。
SUSPENDED:对不可用资源的线程将移至等待列表中,直到资源可用(等待资源)。
RUNNABLE:具有可用资源的线程,但被移至可运行队列,等待CPU变得可用(等待信号)。
不过,等待类型 SOS_SCHEDULER_YIELD 不涉及 SUSPENDED。

上图中,SPID=53在4毫秒内未执行完成,其让出 Scheduler 并进入Runnable 队列中,此时注册为SOS_SCHEDULER_YIELD 等待类型,不会发生资源等待(SUSPENDED)。这时候,SPID=58 则进入 Scheduler 中并执行处于 Running状态。
我以前面并发任务为例:
SELECT *FROM Sales.SalesOrderDetail AINNER JOIN Production.Product B ON A.ProductID = B.ProductIDORDER BY B.Name

这两张表都使用了并发线程,我们设置的最大并发度为2,只能使用2个CPU处理(这里我们不考虑等待类型CXPACKET的情况)。我们假定,此刻数据库引擎正在扫描表获取数据,在4个线程中,也只能有2个线程处于Running状态。同一个CPU中,只能有一个线程正在 Running,如果4毫秒内未处理完,该线程则放入Runnable 队列(出现 SOS_SCHEDULER_YIELD 等待),让其他线程使用CPU。如此反复切换,即为CPU的上下文切换,CPU使用率也将升高。
上面的并发只是同一个连接请求发生的,如果有更多的用户连接请求呢?大家是不是就可能分配到同一个CPU了,CPU处理的任务越多,上下文切换也会越频繁,数据也重复地加载到CPU缓存中。而上下文切换协调各个线程的运行,保证能相对民主地执行用户的请求。
总结:
我们已经基本了解了并发、多线程是如何使用CPU的,但一个系统中如果出现较多工作线程,也将触及 SQL Server 中对线程数的最大限制。线程数的默认大小与逻辑CPU数量相关,有固定的计算公式。更多请搜索参考服务器配置项 max worker threads(系统默认配置为0,表示使用默认的计算值)。
如16个逻辑CPU在64位的数据库系统中默认最大工作线程为704,我们也可以设置高一点的值。对于繁忙的系统,过多的线程数也会使用更多的内存空间(2MB/ Thread Stack),过多的线程数也会使用户的请求处理更慢。类似连接数一样,最大工作线程 max worker threads 也不能太大。
SQL Server 数据库系统中,除了关注配置项 cost threshold for parallelism、max degree of parallelism、max worker threads外,也需要我们监控系统中已创建的线程数、活动线程数的指标值。可以通过性能计数器、扩展事件system_health、自定义扩展事件、系统性能视图查看,这有助于我们排查和优化相关性能问题。同样,我们也可以引入平均活动会话(Average Active Sessions,AAS)的概念,来总体说明各个CPU的使用情况,作为系统的负载情况。
另外,数据库系统估算执行时间是不够准确的,但是估算CPU、IO使用量作为成本开销是可以的。基于成本的开销,过去很多人认为是时间单位,而在 MSSQL 执行计划中,它是“估计子树大小”,有人使用 “Query Bucks”作为其单位来理解。“估计子树大小” 就是整个执行计划中“估计I/O开销”与“估计CPU开销”的总和,通过总开销,数据库引擎才能更好地选择最优的执行计划。
最近文章推荐:
历史文章推荐:

