




1. 正确的理解索引膨胀
postgres运维中因为有dead tuple,所以表膨胀是很常见的问题,正确的配置好autovacuum相关参数后,其实不用过多的去干预表膨胀,autovacuum进程会对符合条件的表和索引进行dead tuple的清理。
那么索引膨胀又该怎么定义呢?不能单独的认为表膨胀,这个表的索引也膨胀吧?假设对一个索引进行顺序的数据插入,那么索引分裂应该只会发生在最右边的叶子结点,如果对索引进行无序的插入,那么中间的叶子结点会进行了分裂,多出了很多空闲空间,索引扫描的时候需要扫描更多的页,造成了io和存储空间上的浪费,这样应该能符合索引膨胀的定义。
那么该如何解决呢?也很简单,reindex就可以,而且pg12之后支持CONCURRENTLY能更方便的进行reindex,定期的检查膨胀率过大的索引进行reindex是很有必要的,所以下面就如何确定一个索引是否发生膨胀进行详细说明。
2. 使用扩展查看索引信息
常用的模块就能满足需求,为方便测试创建了一个测试表,int字段创建索引idx_test02_id,插入100w条数据,pgstattuple的pgstatindex()可以查看索引的统计信息:
create extension pgstattuple;
create table test02(id int, name text);
create index idx_test02_id on test02(id);
insert into test02 select n,'a' from generate_series(1, 1000000) n;
select * from pgstatindex('idx_test02_id');
-[ RECORD 1 ]------+---------
version | 4
tree_level | 2
index_size | 22487040
root_block_no | 412
internal_pages | 11
leaf_pages | 2733
empty_pages | 0
deleted_pages | 0
avg_leaf_density | 90.06
leaf_fragmentation | 0
对结果信息进行解释
| column | describe |
|---|---|
| tress_level | 索引的深度,branch层数+leaf层 |
| index_size | 索引的大小,单位byte,所有的page数量 * blocksize |
| root_block_no | root page 页号 |
| internal_pages | root page + branch pages |
| leaf_pages | 叶子结点总量 |
| avg_leaf_density | 索引的密度,索引使用空间/pages可用空间 |
| leaf_fragmentation | 碎片率,用来表示物理上的顺序性,越大表示物理上越不连续,如果都是顺序存储则为0 |
可以通过pgstattuple的源码确认index_size的计算方法: all pages * block size
(1 + /* include the metapage in index_size */
indexStat.leaf_pages +
indexStat.internal_pages +
indexStat.deleted_pages +
indexStat.empty_pages) * BLCKSZ
我们重点关注以下2个指标:
- avg_leaf_density
为实际索引数据占总量的百分比, 越低表示索引浪费空间越多,建议小于30%进行reindex,源码中的计算方式如下
100.0 - (double) indexStat.free_space / (double) indexStat.max_avail * 100.0);
max_avail计算方式为页面大小减去页面中已使用的空间大小和页面头部数据的大小
max_avail = BLCKSZ - (BLCKSZ - ((PageHeader) page)->pd_special + SizeOfPageHeaderData);
free_space = page.pd_upper – page.pd_lower
因为leaf page的fillfactor为90%,所以理想情况下,avg_leaf_density应该为90%
- leaf_fragmentation
表示碎片率,数字越大表示物理上越不连续,源码中解释为它比较下一个叶子页的块号(opaque->btpo_next)与当前块号(blkno)。如果下一个叶子页在较早的块上,表示存在碎片化。索引中的碎片化是指索引的叶子页在磁盘上不是物理上连续的。这可能是由于页面分裂或删除等原因导致的。碎片化可能会影响索引扫描的性能,并可能需要维护操作,如索引重组或重建。
/*
* If the next leaf is on an earlier block, it means a
* fragmentation.
*/
if (opaque->btpo_next != P_NONE && opaque->btpo_next < blkno)
indexStat.fragments++;
综上信息给出一个大致结论:avg_leaf_density越小表示浪费空间越多,结合实际索引大小进行reindex,reindex后avg_leaf_density应很接近90;leaf_fragmentation越大表示物理上的连续行很差,扫描该索引会产生很多随机io影响性能,reindex后会应该为0。
这种方法大致能评估出一个index是否需要进行reindex,好不好用呢?好,但是还不够好;因为得一个个索引去执行,不够敏捷,过于被动,有没有方法可以一下统计出所有的索引膨胀信息并进行排序呢?后面我们进行尝试。
3. 评估索引空间
当我们知道一个表有多少条记录,索引字段的平均长度,就可以大致算出这个存储该index需要多少个page,后面我们称这个数字为iotta,也就是我们需要计算出膨胀前的pages,理论上说一个无重复字段顺序插入的索引iotta应该等于pg_class中的relpages,或者说一个无重复字段的索引进行reindex后,iotta应该等于pg_class中的relpages,也和pgstatindex结果中的leaf pages + internal_pages + 1个meta page的结果相等。
用iotta去除以索引当前的pg_class.relpages,得出的比率值,就相当于这个索引的膨胀率,那么如何计算出iotta呢?
大致思路为:计算一个page能存多少个index tuple, tuples总数除以这个数字大致就是leaf pages的数量,再通过leaf pages的数量来倒推branch pages的数量,最后leaf pages + branch pages + 1 root page + 1 meta page,就是我们需要得到的结果。
后面我们进行实验验证,先来一起学习一些知识点,方便后面的计算。
3.1 index fillfactor
我们知道heap page默认fillfactor是100,那么索引的fillfactor是否跟heap page一致呢?从源码的注解中能找到答案,src/include/access/nbtree.h写到了,leaf page的fillfactor是90,非leaf page的fillfactor是70,这个在我们后面的计算中非常有用,重点记录下!
/*
* The leaf-page fillfactor defaults to 90% but is user-adjustable.
* For pages above the leaf level, we use a fixed 70% fillfactor.
* The fillfactor is applied during index build and when splitting
* a rightmost page; when splitting non-rightmost pages we try to
* divide the data equally. When splitting a page that's entirely
* filled with a single value (duplicates), the effective leaf-page
* fillfactor is 96%, regardless of whether the page is a rightmost
* page.
*/
#define BTREE_MIN_FILLFACTOR 10
#define BTREE_DEFAULT_FILLFACTOR 90
#define BTREE_NONLEAF_FILLFACTOR 70
#define BTREE_SINGLEVAL_FILLFACTOR 96
3.2 high key
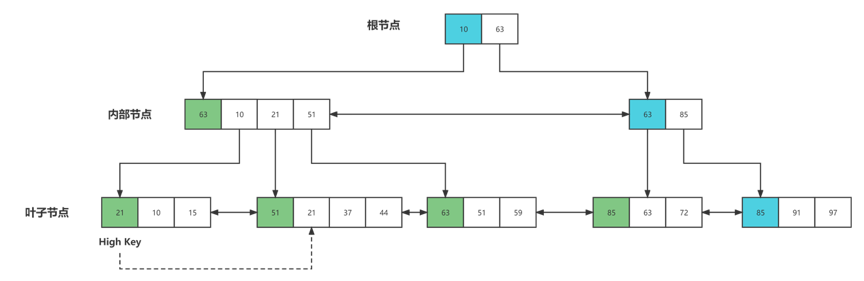
high key这个是不是感觉很陌生,因为它是PostgreSQL中使用的B+树的一个变种,B link Tree,high key是B link tree里的一个特性,具体带来什么优点在这里不详细介绍了。
每层的非最右结点,该结点上都会有一个high key,high key表示一个节点的upper bound,即节点所能存放key的最大值,一个节点中的high key必须等于其右兄弟的最小值,PostgreSQL在分裂时就是将右节点的最小key作为左节点的high key。
每层的最右节点不存在high key,因为最右节点的最大key应该是无穷大。high key位于节点中的第一个元素,只是用于表示节点的upper bound。所以对于非最右节点来说,节点内的第一个data key应该是high key之后的那个key(即第二个key),对于最右节点来说,第一个data key才是节点内的第一个key。
为什么high key是节点内的第一个key作为而非最后一个key?这是为了防止插入时频繁移动high key。high key是节点中最大的一个key,由于节点内部需要保持key的有序性,所以如果high key放在节点最后,那么不论插入什么值,都需要后移high key。所以为了防止这样移动,将high key放在节点开始位置。由于high key只在节点分裂时产生,所以不必担心high key发生变化导致key的大小顺序发生变化。
说到这里,high key到底对我们的计算有什么影响呢?假如leaf page有100个,那么就有99个非最右结点,就会额外产生99个high key,所以leaf page需要存储的tuples总量需要加上99。
3.3 index page 数据结构

上面提到需要知道索引字段的平均长度,才能计算leaf pages,那么就需要了解一下index page的数据结构,上源码。
* Index tuple header structure
*
* All index tuples start with IndexTupleData. If the HasNulls bit is set,
* this is followed by an IndexAttributeBitMapData. The index attribute
* values follow, beginning at a MAXALIGN boundary.
typedef struct IndexTupleData
{
ItemPointerData t_tid; /* reference TID to heap tuple */
/* ---------------
* t_info is laid out in the following fashion:
*
* 15th (high) bit: has nulls
* 14th bit: has var-width attributes
* 13th bit: unused
* 12-0 bit: size of tuple
* ---------------
*/
unsigned short t_info; /* various info about tuple */
} IndexTupleData; /* MORE DATA FOLLOWS AT END OF STRUCT */
索引页头部与数据页头部一样( 24个字节 ),ItemIds占用4个字节,索引entries:结构为IndexTupleData + tupledata,indextupledata为index tuple的header,占用8字节(t_tid 6字节, t_info2字节),然后加上实际的数据长度,index tuple还会因为数据对齐进行部位,经过测试一个int字段虽然是4字节,一个entries最小为16字节。
4.实验验证
沿用上面的测试数据表
-
计算leaf page的数量
已经知道有100w条数据,index的tuple长度为 indextupledata 8字节 + int数据长度4 = 12, 不足16字节按16字节算。
单个leaf page的可用空间 = 8192 - 24(header) -16(special) )* 0.9 = 7336
单个leaf page可存储的index tuples = ceil(7336 / (16(index entries) + 4(指针)))=367
leaf page需要个数= ceil(1000000 / 367) = 2725
是不是离上面pgstatindex查出来的leaf_page 2733有些差距,因为我们还没吧high key给算进去。 -
算上high key 再算leaf page
leaf page个数2725,那么high key个数为2724,tuples总量变为1002724
leaf page需要个数= ceil(1002724 / 367) = 2733
与pgstatindex查出来的leaf_page 2733一致! -
计算branch page
branch page存储的是到leaf page的指向信息,换句话说有多少个leaf page,branch里就会存多少条tuples。
单个leaf page的可用空间 = 8192 - 24(header) -16(special) )* 0.7 = 5706
单个leaf page可存储的index tuples = ceil(5706 / (16(index entries) + 4(指针)))=286
branch page需要个数=ceil(2733/286)=10
加上1个root page,internal page就是11,与pgstatindex计算出来的一致!
所以最后1000w条int字段的index需要pages = leaf 2733 + internal 11 + 1 meta = 2745,对应上了pg_class的relpages
select relpages from pg_class where relname='idx_test02_id';
relpages
----------
2745
(1 row)
5.索引膨胀监控sql
上面啰嗦了那么多,来点实际的,实际运维过程中咱们不能挨个索引去用pgstatindex检查吧,而且pgstatindex会扫描index block产生io,越大的索引返回越慢,那么是否可以通过一些系统试图信息来计算出来呢?可以的,但是有些情况下数据可能不太精准,比如有不定长字段、索引数据重复率过高、复合索引字段太多、数据量太小等,但要啥自行车,已经适用于绝大部分情况,而且效率还不错
SELECT schemaname,
tablename,
iname,
cols,
ind_avg_len,
ituples::bigint,
ipages::bigint,
iotta,
internal,
leaf,
ROUND(CASE WHEN iotta=0
OR ipages=0 THEN 0.0 ELSE ipages/iotta::numeric END,1) AS ibloat,
CASE
WHEN ipages < iotta THEN 0
ELSE ipages::bigint - iotta
END AS wastedipages,
CASE
WHEN ipages < iotta THEN pg_size_pretty(0::bigint)
ELSE pg_size_pretty((bs*(ipages-iotta))::bigint)
END AS wastedisize
FROM
(SELECT schemaname,
tablename,
bs,
iname,
cols,
ind_avg_len,
ituples,
ipages,
leaf + round(leaf/((bs::float-40)*0.9/(ind_avg_len+4))) AS leaf,
round(leaf/((bs::float-40)*0.9/(ind_avg_len+4))) AS hk,
ceil (leaf / ceil((bs::float-40)*0.7/(ind_avg_len + 4))) + 1 AS internal,
leaf + round(leaf/((bs::float-40)*0.9/(ind_avg_len+4))) + ceil (leaf / ceil((bs::float-40)*0.7/(ind_avg_len + 4))) + 2 AS iotta
FROM
(SELECT schemaname,
tablename,
bs,
iname,
cols,
ind_avg_len,
ituples,
ipages,
CEIL((ituples*(ind_avg_len + 4))/((bs::float-40)*0.9)) AS leaf
FROM
(SELECT bs,
rs.schemaname,
rs.tablename,
COALESCE(c2.relname,'?') AS iname,
COALESCE(c2.reltuples,0) AS ituples,
COALESCE(c2.relpages,0) AS ipages,
rs.cols,
CASE WHEN sum(s.avg_width+ma-s.avg_width%ma) < 16 THEN 16 ELSE sum(s.avg_width+ma-s.avg_width%ma) +8 END AS ind_avg_len
FROM
(SELECT
(SELECT current_setting('block_size')::numeric) AS bs,
4 AS ma,
nn.nspname AS schemaname,
c1.relname AS tablename,
i.indexrelid,
array_agg(a.attname
ORDER BY s.i) AS cols
FROM pg_index i
LEFT JOIN pg_class c1 ON i.indrelid = c1.oid
JOIN LATERAL unnest(i.indkey) WITH
ORDINALITY AS s(attnum, i) ON TRUE
LEFT JOIN pg_attribute a ON a.attnum = s.attnum
AND a.attrelid = i.indrelid
LEFT JOIN pg_namespace nn ON c1.relnamespace = nn.oid
WHERE i.indisvalid = TRUE
AND nn.nspname NOT IN ('pg_toast',
'pg_catalog')
GROUP BY bs,
ma,
nn.nspname,
c1.relname,
i.indexrelid) AS rs
LEFT JOIN pg_class c2 ON c2.oid = rs.indexrelid
JOIN pg_stats s ON s.tablename = rs.tablename
AND s.attname = any(rs.cols)
GROUP BY bs,
rs.schemaname,
rs.tablename,
c2.relname,
c2.reltuples,
c2.relpages,
rs.cols) AS smx) AS sml) RESULT
ORDER BY wastedipages DESC;
测试结果 如下,iotta即理论情况下需要的pages数量,ibloat为膨胀率,过大则建议进行reindex
-[ RECORD 1 ]+--------------
schemaname | public
tablename | test02
iname | idx_test02_id
cols | {id}
ind_avg_len | 16
ituples | 1000000
ipages | 2745
iotta | 2745
internal | 11
leaf | 2733
ibloat | 1.0
wastedipages | 0
wastedisize | 0 bytes
