




Part 1 任务调度
调度会分为两级调度。一级QC是SQL查询被执行的机器,在并行查询执行中,负责总体执行计划的调度和划分机器级别资源,并且收集和发送全局信息到所有机器。一级QC和各机器的SQC通信,不直接和各机的实际工作线程通信。各机的SQC负责各机内部工作线程的调度工作,接受QC的调度命令,在机器内根据QC提供的机器级别任务进行本机的任务划分,并通过调度消息分配给各个本机工作线程。线程组工作参照下图:
通信机制
如果通道两端位于同一台物理机,单机通道的实现利用共享内存,就是提供一个本地的FIFO队列,此时也不需要DTL提供额外的线程来同步数据的传输。
如果通道两端位于同一台物理机,单机通道的实现利用共享内存,就是提供一个本地的FIFO队列,此时也不需要DTL提供额外的线程来同步数据的传输。如果是跨机通信,初次建立将基于现有的RPC机制,握手过程完成后,所有的QC到SQC,以及各自机器SQC到工作线程的通信将依赖于DTL机制建立通信连接,每一个SQC到每台机器的两组工作线程全部都有通信连接,每一个工作线程除了和SQC的通信之外,还和对端工作组的所有工作线程有通信连接。考虑在大并发度下的通信资源问题,DTL在内部实现中实现一定的共享机制,比如将某个查询的工作线程分成几组,一组采用一个共享的消息暂存和发送队列,由一组消息处理线程提供服务。在接收到发送到某一个线程的消息时,先放入相应组的消息队列中,然后再由该组的消息服务线程进行下一步的分发到对应工作线程。
通道(Channels )数=M(生产者)* N(消费者),每个消费者会预留3个内存槽,如果内存槽占满,当槽位被数据占满时会通知发送端暂停发送数据,当有接收端数据被消费空闲槽位出现时通知发送端继续发送。
切分粒度
对于基表扫描的任务,在进行并行任务切分时,需要考虑选择一个合适的切分粒度。切分粒度过细,将导致任务过多,每次分发占用的额外开销将占整个任务执行时间较高比重,切分粒度过粗,则出现数据倾斜的可能性增加。任务切分在SQC启动相应包含扫描的子树时启动,每个机器的SQC独立进行。对于Query Range类型的并行。基本思路会是按照计算出的最佳任务大小,切分本地宏块组,将每一个均匀切分的宏块组反向映射到Query Range每一个任务在切分时不跨越分区边界。
动态均衡
并行执行框架实现了工作线程向SQC要扫描表任务的功能,功能类似Oracle的GRANULE ITERATOR,实现扫描任务的动态负载均衡。我们实现一个GRANULE ITERATOR的算子,它的功能就是从每台机器每个查询的任务参数队列中去拿到一个或多个任务参数,以用于给TABLE SCAN配置参数,在TABLE SCAN返回扫描结束的时候,它将去拿下一个任务参数然后重新启动TABLE SCAN。这个算子一方面避免了多次序列化整个DFO的算子子树给工作线程,提供动态的负载均衡。
分布式查询流程说明
1. Query发起,所连的Server担当起QC角色
2. QC首先预约足够的线程资源
3. QC将需要并行的计划拆成多个DFO,根据优化器或者用户指定
4. QC按照一定的逻辑顺序将DFO分发到SQC,SQC调度Worker执行
5. 当各个DFO都执行完毕,QC 会串行执行剩余部分的计算。如,一个并行的COUNT 算法,最终需要QC 将各个机器上的计算结果做一个SUM 运算
6. QC所在线程将结果返回给客户端
Part 2 通过执行计划看并发执行
了解了实现逻辑,我们看下在OceanBase中 一条SQL的执行计划是怎样的。
环境准备

建表语句:
- 表PARTSUPP
CREATE TABLE PARTSUPP (
PS_PARTKEY BIGINT NOT NULL,
PS_SUPPKEY BIGINT NOT NULL,
PS_AVAILQTY BIGINT NOT NULL,
PS_SUPPLYCOST DECIMAL(15, 2) NOT NULL,
PS_COMMENT VARCHAR(199) NOT NULL,
PRIMARY KEY (PS_PARTKEY, PS_SUPPKEY),
INDEX INDEX_1(PS_SUPPKEY) LOCAL,
INDEX INDEX_2(PS_PARTKEY) LOCAL
)
PARTITION BY HASH (PS_PARTKEY) PARTITIONS 256;
- 表PART
CREATE TABLE PART (
P_PARTKEY BIGINT NOT NULL,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE BIGINT NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15, 2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL,
PRIMARY KEY (P_PARTKEY)
)
PARTITION BY HASH (P_PARTKEY) PARTITIONS 256;
- 表SUPPLIER
CREATE TABLE SUPPLIER (
S_SUPPKEY BIGINT NOT NULL,
S_NAME CHAR(25) NOT NULL,
S_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY BIGINT NOT NULL,
S_PHONE CHAR(15) NOT NULL,
S_ACCTBAL DECIMAL(15, 2) NOT NULL,
S_COMMENT VARCHAR(101) NOT NULL,
PRIMARY KEY (S_SUPPKEY),
index index_1(S_NATIONKEY) local
)
PARTITION BY HASH (S_SUPPKEY) PARTITIONS 256;
- 表NATION
CREATE TABLE NATION (
N_NATIONKEY BIGINT NOT NULL,
N_NAME CHAR(25) NOT NULL,
N_REGIONKEY BIGINT NOT NULL,
N_COMMENT VARCHAR(152),
PRIMARY KEY (N_NATIONKEY),
INDEX INDEX1(N_REGIONKEY) LOCAL
);
- 表REGION
CREATE TABLE REGION (
R_REGIONKEY BIGINT NOT NULL,
R_NAME CHAR(25) NOT NULL,
R_COMMENT VARCHAR(152),
PRIMARY KEY (R_REGIONKEY)
);
- SQL
SELECT *
FROM (
SELECT /*+ parallel(256) */ s_acctbal, s_name, n_name, p_partkey, p_mfgr
, s_address, s_phone, s_comment
FROM part, supplier, partsupp, nation, region
WHERE p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND p_size = 30
AND p_type LIKE '%STEEL'
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
AND ps_supplycost = (
SELECT MIN(ps_supplycost)
FROM partsupp, supplier, nation, region
WHERE p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'ASIA'
)
ORDER BY s_acctbal DESC, n_name, s_name, p_partkey
) WHERE rownum <= 100
执行计划
PX计划树:
- 通过HINT将DOP设置为256
- QC将查询切分成多个DFO ,处理REGION表的DFO通过多Worker并行扫描,获得到相应数据,作为生产者将数据Broadcast通知到其他SQC节点
- 同上,查询NATION的WORKER作为生产者将数据Broadcast通知到其他SQC节点
- PART和PARTSUPP是分区表,Worker是在各分区并行做全表扫描。将结果集NLJ后向上传递
- 处理SUPPLIER表的DFO 全表扫描,与其他DFO的结果集做HASH JOIN
- 各个DFO的HASH JOIN、聚合、排序都执行完成
- QC生成最终结果,并将结果返回给请求方
Part 3并行执行使用场景和操作指南
并行执行相关系统变量
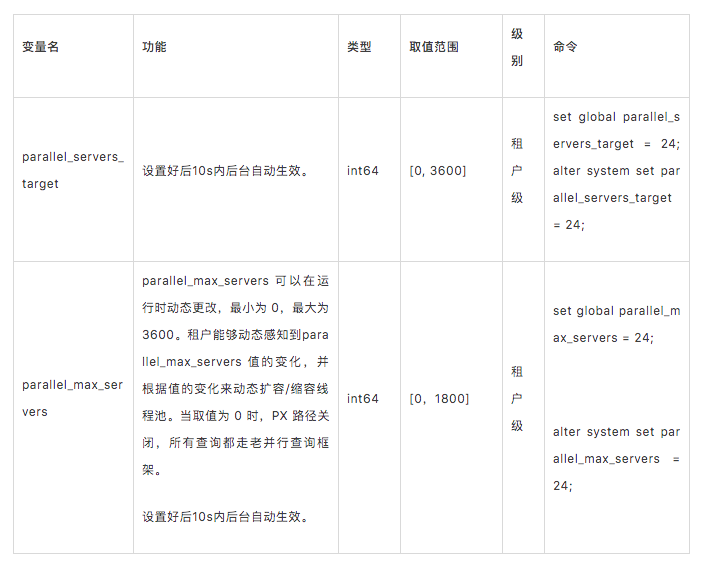
可以使用并行查询的操作
下述各种查询操作都可以使用并行查询:
- 各种Access Methods
全表扫描(包括分区间并行和分区内并行扫描),索引表扫描
- 各种表连接操作
包括NESTED LOOP JOIN,MERGE JOIN和HASH JOIN
- 其他一些SQL操作
包括一些聚合操作,例如GROUP BY,DISTINCT,SUM等,LIMIT算子的下压等
建议使用并行查询的场景
并行查询对于以下情况有显著效果
- 充足的IO带宽
- 系统CPU负载较低
- 充足的内存资源以满足并行查询的需要
如果系统没有充足的资源进行额外的并行处理,使用并行查询或者提高并行度并不能提高执行性能。相反,在系统过载的情况下,操作系统被迫进行更多的调度,上下文切换或者页面交换,可能会导致性能的进一步下降。通常在D(ecision)S(upport)S(ystem)系统,大量分区需要被访问和数据仓库环境下,并行执行能够提升执行响应时间。OLTP系统通常在批量DML操作或者进行SCHEMA维护操作时能够受益,例如进行INDEX的创建等。对于简单的DML操作或者分区内查询以及涉及分区数比较小的查询来说,使用并行查询并不能很明显的提高查询响应时间。
