






/ 各类存储系统比较
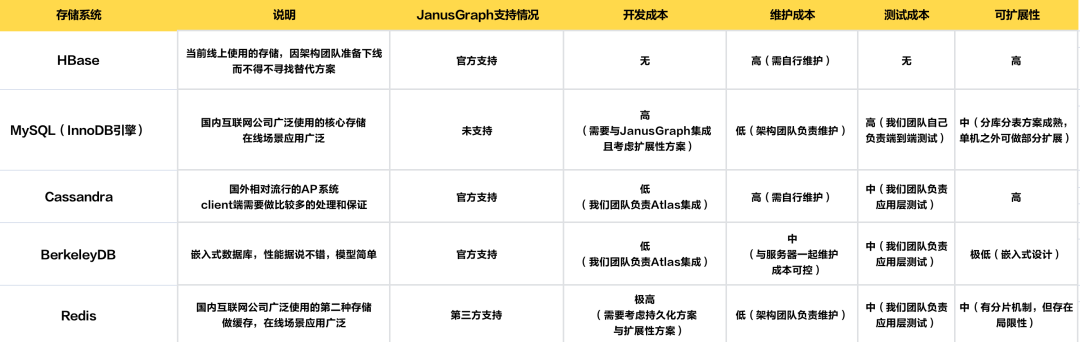
● 因投入成本过高,我们不接受自己运维有状态集群,排除了HBase和Cassandra;
● 从当前数据量与将来的可扩展性考虑,单机方案不可选,排除了BerkeleyDB;
● 同样因为人力成本,需要做极大量开发改造的方案暂时不考虑,排除了Redis。
/ MySQL的理论可行性
● 可以支持Key-Value(后续简称KV模型)或者Key-Column-Value(后续简称KCV模型)的存储模型,聚集索引B+树排序访问,支持基于Key或者Key-Column的Range Query,所有查询都走索引,且避免内存中重排序,效率初步判断可接受。
● 中台内的其他系统,最大的MySQL单表已经到达亿级别,且MySQL有成熟的分库分表解决方案,判断数据量可以支持。
●在具体使用场景中,对于写入的效率要求不高,因为大量的数据都是离线任务完成,判断MySQL在写入上的效率不会成为瓶颈。

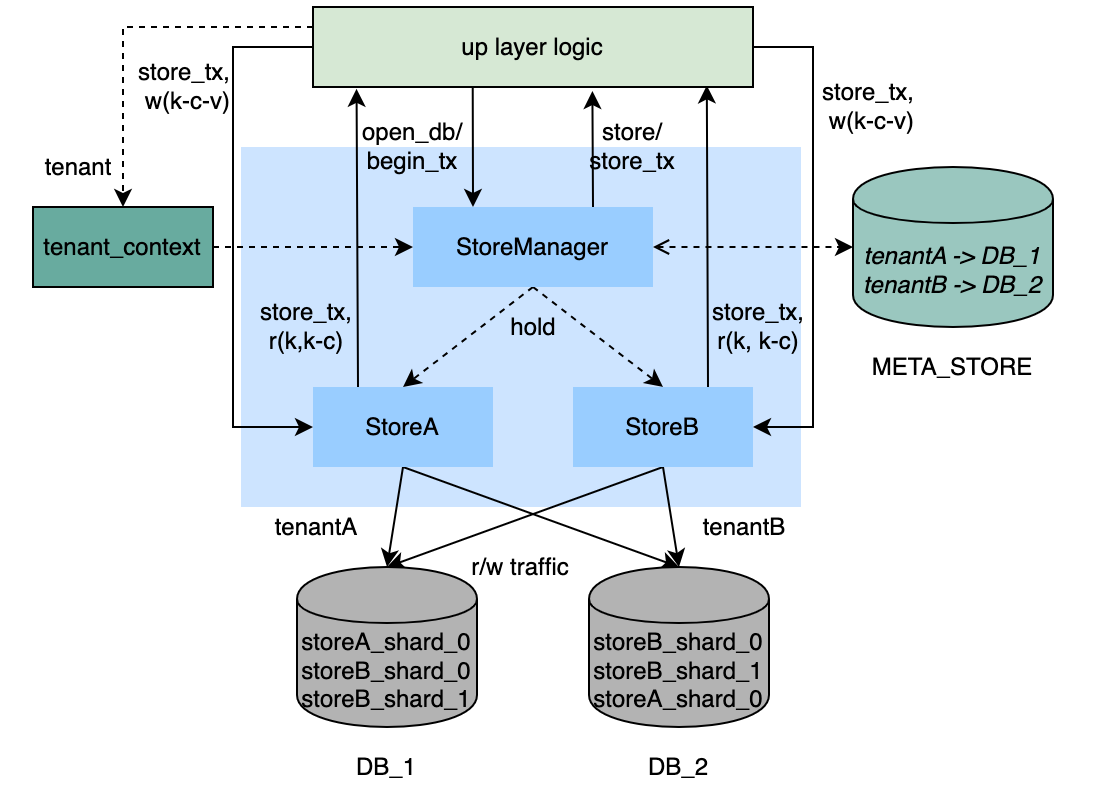
● 维护一张Meta表做lookup用,Meta表中存储租户与DataSource(库)之间的映射关系,以及Shards等租户级别的配置信息。
●StoreManager作为入口,在openTransaction的时候将租户信息注入到StoreTransaction中,并返回租户级别的DataSource。
● StoreManager中以name为Key,维护一组Store,Store与存储的数据类型有关,具有跨租户能力(常见的Store有system_properies,tx_log,graphindex,edgestore等)
●对于MySQL最终的读写,都收敛在Store,方法签名中传入StoreTransaction,Store从中取出租户信息和数据库连接,进行数据读写。
● 对于单租户来说,数据可以分表(shards),对于某个特定的key来说,存储和读取某个shard,是根据ShardManager来决定(典型的ShardManager逻辑,是根据总shard数对key做hash决定,默认单分片。)
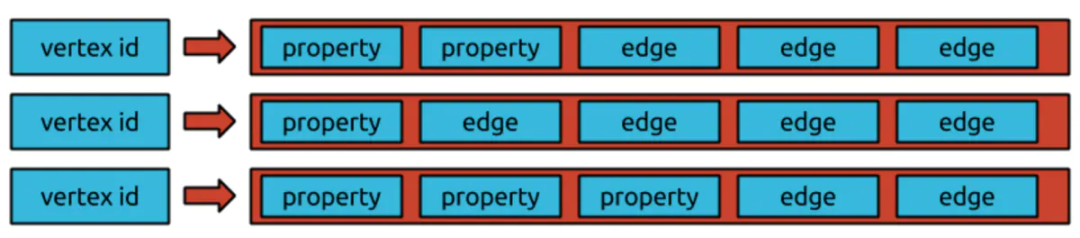
● 对于每个Store,表结构是4列(id, g_key, g_column, g_value),除自增ID外,对应key-column-value model的数据模型,key+column是一个聚集索引。
● Context中的租户信息,需要在操作某个租户数据之前设置,并在操作之后清除掉。

/ 细节设计
1. 存储模型
2. 多租户
public class MysqlKcvStoreManager implements KeyColumnValueStoreManager {@Overridepublic StoreTransaction beginTransaction(BaseTransactionConfig config) throws BackendException {String tenant = TenantContext.getTenant();if (!tenantToDataSourceMap.containsKey(tenant)) {try {初始化单个租户的DataSourceinitSingleDataSource(tenant);} catch (SQLException e) {log.error("init mysql database source failed due to", e);throw new BackendSQLException(String.format("init mysql database source failed due to", e.getMessage()));}}获取数据库连接Connection connection = tenantToDataSourceMap.get(tenant).getConnection(false);return new MysqlKcvTx(config, tenant, connection);}}
public class MysqlKcvTx extends AbstractStoreTransaction {private static final Logger log = LoggerFactory.getLogger(MysqlKcvTx.class);private final Connection connection;@Getterprivate final String tenant;public MysqlKcvTx(BaseTransactionConfig config, String tenant, Connection connection) {super(config);this.tenant = tenant;this.connection = connection;}@Overridepublic synchronized void commit() {try {if (Objects.nonNull(connection)) {connection.commit();connection.close();}if (log.isDebugEnabled()) {log.debug("tx has been committed");}} catch (SQLException e) {log.error("failed to commit transaction", e);}}@Overridepublic synchronized void rollback() {try {if (Objects.nonNull(connection)) {connection.rollback();connection.close();}if (log.isDebugEnabled()) {log.debug("tx has been rollback");}} catch (SQLException e) {log.error("failed to rollback transaction", e);}}public Connection getConnection() {return connection;}}
4.数据库连接池
/ 疑难问题
1. 连接超时
2. 并行写入死锁
[thread-p-3-a-0] ERROR org.janusgraph.diskstorage.mysql.MysqlKcvStore 313 - failed to insert query:INSERT INTO default_edgestore (g_key, g_column, g_value) VALUES (?,?,?) ON DUPLICATE KEY UPDATE g_value=?, params: key=A800000000001500, column=55A0, value=008000017CE616D0DD03674495com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction[thread-p-7-a-0] ERROR org.janusgraph.diskstorage.mysql.MysqlKcvStore 313 - failed to insert query:INSERT INTO default_edgestore (g_key, g_column, g_value) VALUES (?,?,?) ON DUPLICATE KEY UPDATE g_value=?, params: key=A800000000001500, column=55A0, value=008000017CE616D8E1036F3495com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction[thread-p-3-a-0] ERROR org.janusgraph.diskstorage.mysql.MysqlKcvStore 313 - failed to insert query:INSERT INTO default_edgestore (g_key, g_column, g_value) VALUES (?,?,?) ON DUPLICATE KEY UPDATE g_value=?, params: key=5000000000000080, column=55A0, value=008000017CE616F3C10442108Acom.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction[thread-p-7-a-0] ERROR org.janusgraph.diskstorage.mysql.MysqlKcvStore 313 - failed to insert query:INSERT INTO default_edgestore (g_key, g_column, g_value) VALUES (?,?,?) ON DUPLICATE KEY UPDATE g_value=?, params: key=5000000000000080, column=55A0, value=008000017CE61752B50556208Acom.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException: Deadlock found when trying to get lock; try restarting transaction

/ 环境搭建
接口逻辑有所裁剪,在不影响核心读写流程的情况下,屏蔽掉对其他服务的依赖。

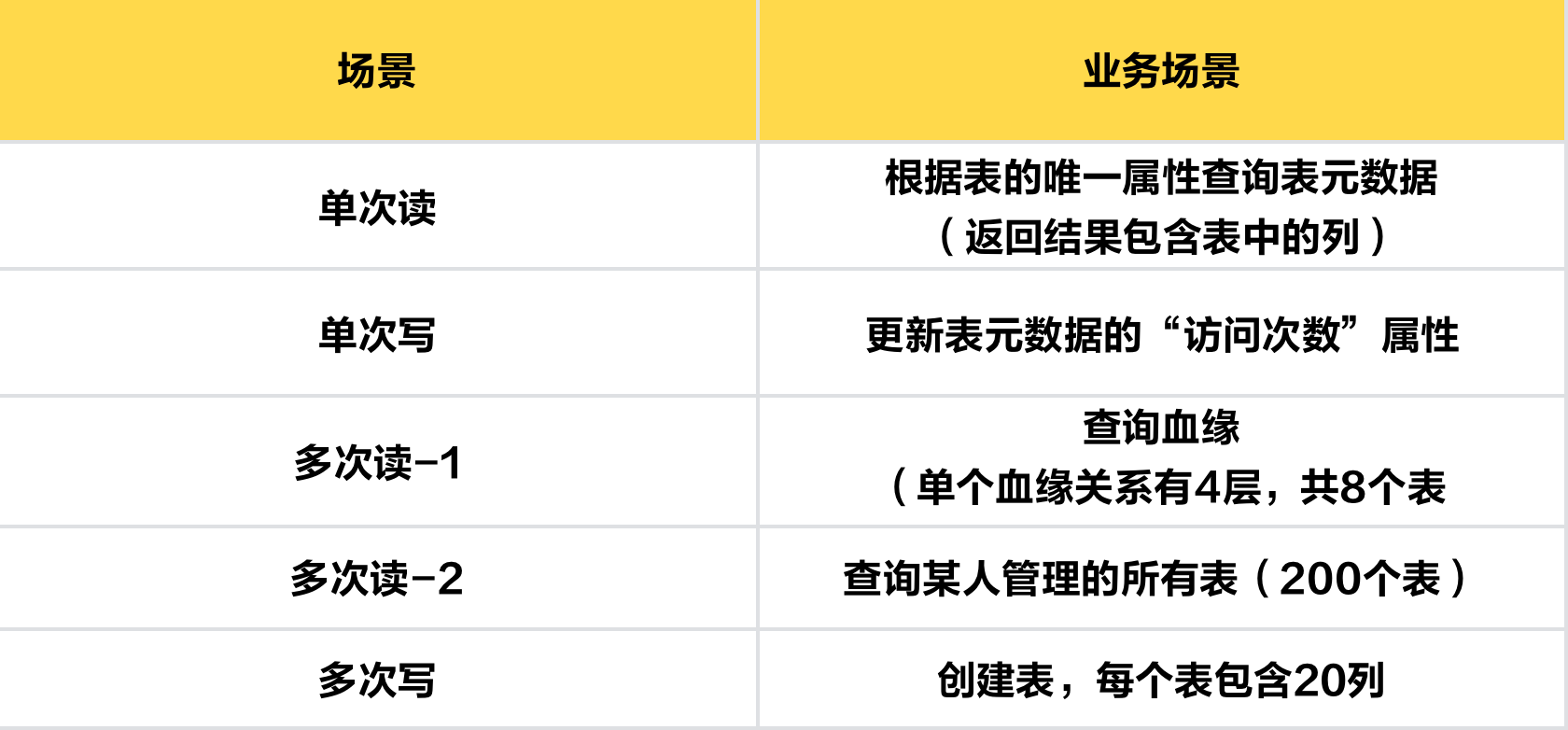
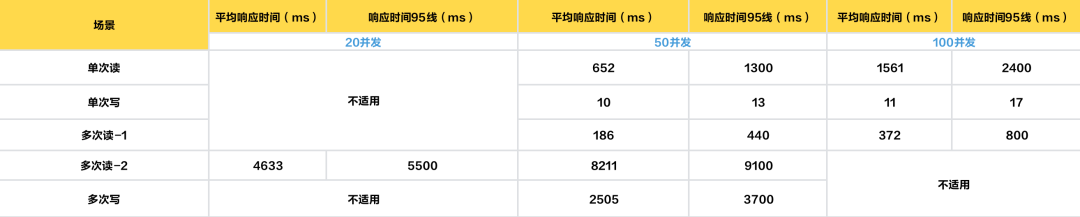
/ 测试结论

产品介绍






文章转载自字节跳动数据平台,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
