




FDW的基本概念
什么是SQL/MED?
SQL/MED是为了统一异构数据源的访问方式。2003年SQL/MED加入到ISO/IEC 9075-9标准中,SQL/MED定义为通过foreign-data wrappers(fdw)或datalink(如oracle、pg的dblink)管理外部数据的SQL标准扩展。简而言之,SQL/MED是国际SQL扩展标准。很多库已经支持SQL/MED如DB2、MariaDB、PG等等。
在没用SQL/MED时应用只能自行访问需要的数据源,并在应用层对数据进行处理:
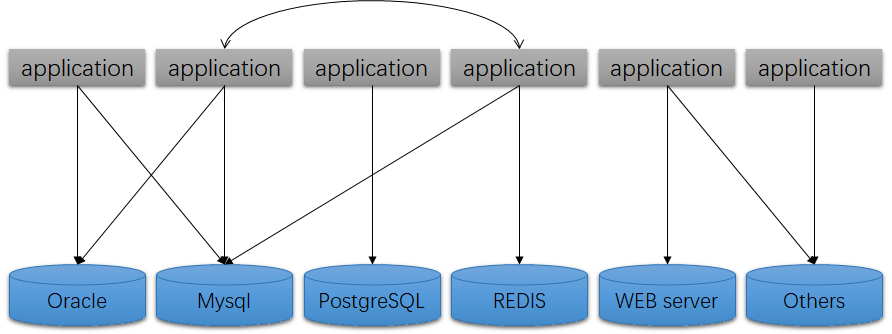
使用SQL/MED后,数据访问架构会更清晰
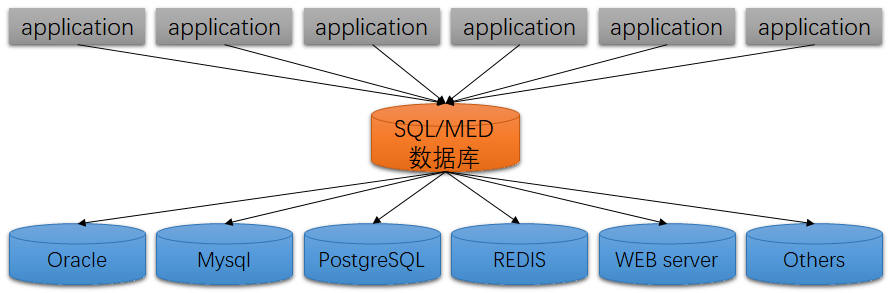
但是,这个架构图看上去是简化了,对于数据库的IO、计算压力却提升了。这跟当今把计算从数据库剥离到应用层的思想是违背的。
当然两种方案各有优劣,有些场景下SQL/MED还是会使用到。
SQL/MED作为一个标准存在,PostgreSQL也通过FDW极好的支持了SQL/MED标准。
什么是FDW?
postgresql从开始9.1支持fdw。用户可以通过常规的SQL语句访问外部数据(foreign data)。foreign data通过foreign data wrapper(fdw)来访问。postgresql数据库中的fdw本身是一个library ,因为不同的外部数据对应这不同的fdw插件,所以我们也常说说它是fdw插件。
pg中的FDW功能十分强大,不仅支持多种数据源,还对数据访问做了优化,甚至可以用来做“超出预期”的事情,比如集群功能的实现。
安装与下载
基本上每种数据库、数据类型都有各自的fdw插件,访问oracle库有oracle_fdw,访问mysql库有mysql_fdw等等。fdw插件可以直接安装或者下载安装:
- 已包含在extension中的fdw。有file_fdw、postgres_fdw、cstore_fdw
- 其他的fdw插件可以在PGXN或者wiki上下载,比如:oralce_fdw、mysql_fdw、json_fdw。注意仔细阅读readme,了解不同fdw的限制和使用规则。
- fdw插件下载地址:https://pgxn.org/tag/fdw/
- 更多的fdw(大部分是beta版):https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- 自行编写fdw。https://www.postgresql.org/docs/current/fdwhandler.html
pg中fdw相对dblink的优势
pg库也有dblink。fdw和dblink在功能上是很类似的都是访问外部表。但是fdw有更多优势
- fdw支持更多的数据源(非常非常多)。dblink只支持postgresql数据库,相当于fdw的其中一个插件postgres_fdw功能(实际上postgres_fdw要强的多)
- 对开发透明。可以像访问普通表一样访问外部表
- 更符合标准SQL语法
- 在很多场景下有更好的性能
The functionality provided by this module overlaps substantially with the functionality of the older dblink module. But
postgres_fdwprovides more transparent and standards-compliant syntax for accessing remote tables, and can give better performance in many cases.
总之,fdw强于dblink插件,基本上可以把dblink遗忘了。
fdw的4个对象
不同的fdw有不同的用法,但基本都需要创建4个对象foreign data wrapper(包装器),server(外部服务),user mapping(用户映射),foreign table(外部表)。其中有些对象不是必须的,比如file_fdw就可以没有user mapping,而关系型数据库的fdw一般都需要创建user mapping。
foreign data wrapper
在CREATE EXTENSION创建好相应的fdw插件后,foreign data wrapper就自动建好了。
比如创建一个file_fdw extension,其对应的foreign data wrapper自动创建好。
=# create extension file_fdw;
CREATE EXTENSION
=# \dx
Name | Version | Schema | Description
--------------------+---------+------------+------------------------------------------------------------------------
file_fdw | 1.0 | public | foreign-data wrapper for flat file access
# select * from information_schema.foreign_data_wrappers;
foreign_data_wrapper_catalog | foreign_data_wrapper_name | authorization_identifier | library_name | foreign_data_wrapper_language
------------------------------+---------------------------+--------------------------+--------------+-------------------------------
postgres | file_fdw | postgres | [null] | c
也可以不使用插件,自行创建一个外部数据包装器,参考CREATE FOREIGN DATA WRAPPER
server
CREATE SERVER可以创建一个外部服务,相当于指定了数据来源。其中OPTIONS的语法因不同的foreign-data wrapper而不同,比如file_fdw,postgres_fdw的OPTION语法肯定是不一样的,这时就要读fdw插件的readme或者官方文档了。例如
创建一个file_fdw的外部服务名叫fileserver:
CREATE SERVER fileserver FOREIGN DATA WRAPPER file_fdw;
创建一个postgres_fdw的外部服务名叫pgserver,服务来自172.0.0.1:5432 pg实例上的lzldb库:
CREATE SERVER pgserver FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '172.0.0.1', dbname 'lzldb', port '5432');
查看server:
=# select * from information_schema.foreign_servers;
foreign_server_catalog | foreign_server_name | foreign_data_wrapper_catalog | foreign_data_wrapper_name | foreign_server_type | foreign_server_version | authorization_identifier
------------------------+---------------------+------------------------------+---------------------------+---------------------+------------------------+--------------------------
postgres | pgserver | postgres | postgres_fdw | [null] | [null] | postgres
postgres | fileserver | postgres | file_fdw | [null] | [null] | postgres
user mapping
user mapping定义了外部服务用户和本地用户的对应关系。所以一般关系型数据库类的fdw都有user mapping,而file这类的fdw没有用户定义就不需要创建这个。
例如用刚才的pgserver创建一个user mapping
CREATE USER MAPPING FOR localuser SERVER pgserver OPTIONS (user 'remoteuser', password 'mypasswd');
查看user mapping
=# select * from information_schema.user_mappings;
authorization_identifier | foreign_server_catalog | foreign_server_name
--------------------------+------------------------+---------------------
localuser | lzldb | pgserver
foreign table
foreign table相当于在本地映射了远程表,然后就可以像普通表一样进行访问。因为涉及本地对象了,OPTION很多,所以全语法有些复杂,可参考CREATE FOREIGN TABLE,简单点那么在本地建一个远程对应的表就可以了。
而因fdw的不同语法也有所不同,此处不多做展示了。
举例两个常见的创建foreign table的方式:创建和导入。
创建一个外部表
CREATE FOREIGN TABLE localtable (
id char(5) NOT NULL,
name varchar(40) NOT NULL
)
SERVER pgserver OPTIONS (table_name 'remotetable');
一个个创建foreign table比较麻烦,可以一次把外部schema下的table全部导入
IMPORT FOREIGN SCHEMA remoteschema FROM SERVER pgserver INTO localschema;
查看foreign table
information_schema.foreign_tables; --能直观看到foreign表
pg_foreign_server; --不太直观,但展示了option选项
fdw的使用
查看外部表信息
psql自带的快捷命令比较清晰,可以简单的查看外部表的4个对象,不过要注意search_path的设置
| psql命令 | 含义 |
|---|---|
| \des | list foreign servers |
| \deu | list uses mappings |
| \det | list foreign tables |
| \dtE | list both local and foreign tables |
外部表对象的视图/表比较乱,稍微梳理一下
| foreign data wrapper 表/视图 | 含义 |
|---|---|
| information_schema._pg_foreign_data_wrappers | 信息较全 |
| information_schema.foreign_data_wrappers | 信息较少 |
| information_schema.foreign_data_wrapper_options | 针对性的查foreign data wrapper的option |
| pg_foreign_data_wrapper | 信息略少,但是有权限信息!权限信息其他几个视图都没有 |
| foreign server 表/视图 | 含义 |
|---|---|
| information_schema._pg_foreign_servers | 信息较全 |
| information_schema.foreign_servers | 信息较少 |
| information_schema.foreign_server_options | 针对性的查option,不是一个server一条记录,而是一个option一个记录 |
| pg_foreign_server | 信息较少,基表 |
| user mapping 表/视图 | 含义 |
|---|---|
| information_schema._pg_user_mappings | 较全的user mapping信息 |
| information_schema.user_mappings | 信息较少 |
| information_schema.user_mapping_options | 针对性的查um的option |
| pg_user_mappings | 信息比information_schema._pg_user_mappings略少一点。这个视图可以被没有权限的用户查看,密码会被展示为null |
| pg_user_mapping | 信息较少,基表,主要是option。没有访问权限的用户是查看不了的 |
| foreign table 表/视图 | 含义 |
|---|---|
| information_schema._pg_foreign_tables | 信息较全,展示所有外部表信息 |
| information_schema._pg_foreign_table_columns | 展示了列与列的对应关系 |
| information_schema.foreign_table_options | 针对性的展示foreign table的option |
| foreign_tables | 信息较少,基表 |
这些视图/表看上去挺乱的,但是实际上结构还比较清楚。4种对象的数据字典基表都基本都是一个逻辑
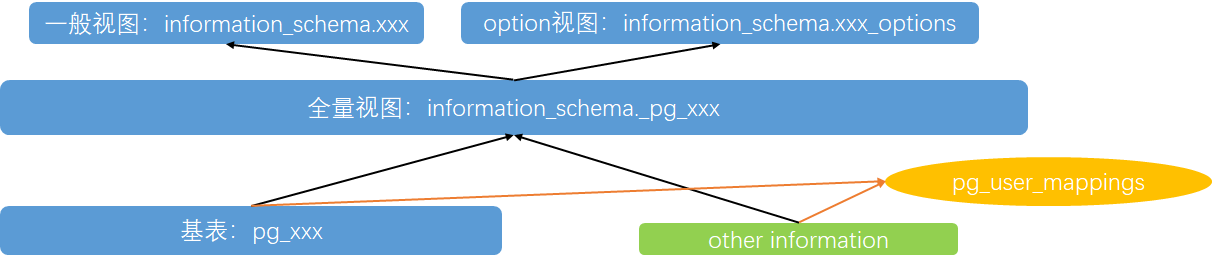
- pg_xxx是基表,是4个对象的基础信息来源
- information_schema._pg_xxx 关联了pg_xxx基表和其他一些信息,information_schema._pg_xxx是一个汇总的视图,信息比较全面
- information_schema.xxx是information_schema._pg_xxx上的视图,信息少一点
- information_schema.xxx_options针对性展示option信息,信息仅来自于全量视图information_schema._pg_xxx
- 一个特殊的视图pg_user_mappings,无权限用户也可以使用
注意权限问题
如果一路使用postgres超级用户去创建外部表,基本上不会遇到什么问题。但是在生产环境中通常应用用户不会是超级用户。所以,权限是非常重要的。它不仅重要而且还比较麻烦,所以使用普通用户做实验很重要(任何实验都是)。pg的权限像闯关打BOSS,缺少任何一环的权限都是不行的。
权限问题需要注意以下几点
- foreign data wrapper,server,user mapping的owner都是创建者,必须各自授权用户usage权限或者是owner本身才可以使用
- 访问远端数据源,需要使用合适权限用户,也就是在user mapping那一步指定合适的远端库登陆用户
- 本地库在创建/导入外部表后,对象被看成本地对象(只有数据字典),所以pg对本地对象的访问权限体系也得合适。
权限可以参考下面postgres_fdw访问外部表的示例
fdw使用示例
全世界已有成百上千种数据源有了相应的FDW实现,各种关系型数据库、nosql数据库、各种类型的文件、Web Service、列式存储、大数据等等。这里介绍几种常见的fdw。
postgres_fdw的使用
这个几乎是最常用也最强大的fdw,可以在本地库中访问外部PostgresSQL数据库。当然也可以用来自我访问,这个功能是很重要的,因为:PGSQL内部不能跨database访问! 如果要解决这个问题,一个比较好的办法就是用fdw实现本地实例跨database访问,通过外部连接实现自己访问自己···
这里是一个用postgres_fdw实现跨database访问的例子
一个实例里面有两个database,aka和bkb。你不能通过一个sql同时查询aka和bkb库,database在pg中是逻辑隔绝的,有点像oracle 12c的pdb
[lzl@postgres]=# \l
aka | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/postgres +
| | | | | postgres=CTc/postgres
bkb | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/postgres +
| | | | | postgres=CTc/postgres
虽然2个库都是本地库,但是在使用fdw的时候还是需要本地库远程库的概念。这里我们把aka当作本地库,bkb当作远程库,实现在aka库中访问bkb库的表,并处理权限问题。
1.安装fdw插件
\c aka
create extension postgres_fdw;
注意:插件是库级别的,需要切到本地库上
2.用户授权
grant usage on foreign data wrapper postgres_fdw to akadata;
3.创建server
\c aka akadata
CREATE SERVER bkb_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '127.0.0.1', port '5432', dbname 'bkb');
4.创建user mapper
CREATE USER MAPPING FOR akadata SERVER bkb_server OPTIONS (user 'bkbdata', password 'bkbpasswd');
5.aka库下创建schema,schema授权给akadata用户
因为担心有重复的表名,导入到另一个schema里
\c aka postgres
create schema bkb;
grant usage on schema bkb TO akadata;
--GRANT select ON ALL TABLES IN SCHEMA bkb TO akadata;
grant all privileges on schema bkb TO akadata;
6.导入bkb表
\c aka akadata
导入整个schema
IMPORT FOREIGN SCHEMA public FROM SERVER bkb_server INTO bkb;
导入单个表
IMPORT FOREIGN SCHEMA public LIMIT TO (tab1) FROM SERVER bkb_server INTO bkb
7.查看外部表
*注意 search_path,导入完成后\d可能看不到外部表
select * from bkb.tab1直接查询可以查到外部表数据,或者基表或视图查看所有的外部表信息
=# select * from information_schema.foreign_tables;
foreign_table_catalog | foreign_table_schema | foreign_table_name | foreign_server_catalog | foreign_server_name
-----------------------+----------------------+-------------------------------------+------------------------+---------------------
aka | bkb | tab1 | aka | bkb_server
file_fdw的使用
file_fdw插件为pg提供了访问外部文件的能力,目前只提供了只读能力。file_fdw已经在contrib中,可以直接CREATE EXTESION安装使用。外部文件必须是符合COPY规则的。
来个经典的把pg的输出日志映射成外部表的例子,脚本来自官方文档 (注意官方文档和pgsql库的版本,pgsql的版本不同日志输出略有不同,所以建的外部表字段有一点不一样)
1.创建file_fdw插件
CREATE EXTENSION file_fdw;
2.创建外部服务
CREATE SERVER fileserver FOREIGN DATA WRAPPER file_fdw;
3.创建外部表
CREATE FOREIGN TABLE pglog (
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text
) SERVER fileserver
OPTIONS ( filename 'pg_log/postgresql-07-06.csv', format 'csv' );
4.查看日志表
直接在库中查看映射的日志表,很方便查到报错信息
=# select user_name,database_name,process_id,error_severity,message from pglog where error_severity<>'LOG';
user_name | database_name | process_id | error_severity | message
-----------+---------------+------------+----------------+-----------------------------------------------
appuser1 | db1 | 102349 | ERROR | value too long for type character varying(20)
appuser1 | db1 | 55378 | ERROR | value too long for type character varying(20)
appuser2 | db2 | 219377 | ERROR | relation "dual" does not exist
postgres_fdw深入
postgres_fdw性能优化
跟绝大多数fdw插件不同,postgres_fdw是PostgreSQL Global Development Group维护的官方插件,其源码包含contrib中。因为外部服务的功能、结构的不同,一些功能比如获得远程库的访问代价、某些场景下的聚合下推等在其他fdw中是难以实现的。但是在postgres_fdw中却可以做到,官方对 postgres_fdw做了非常多的优化,其功能已经非常强大。
SQL执行过程
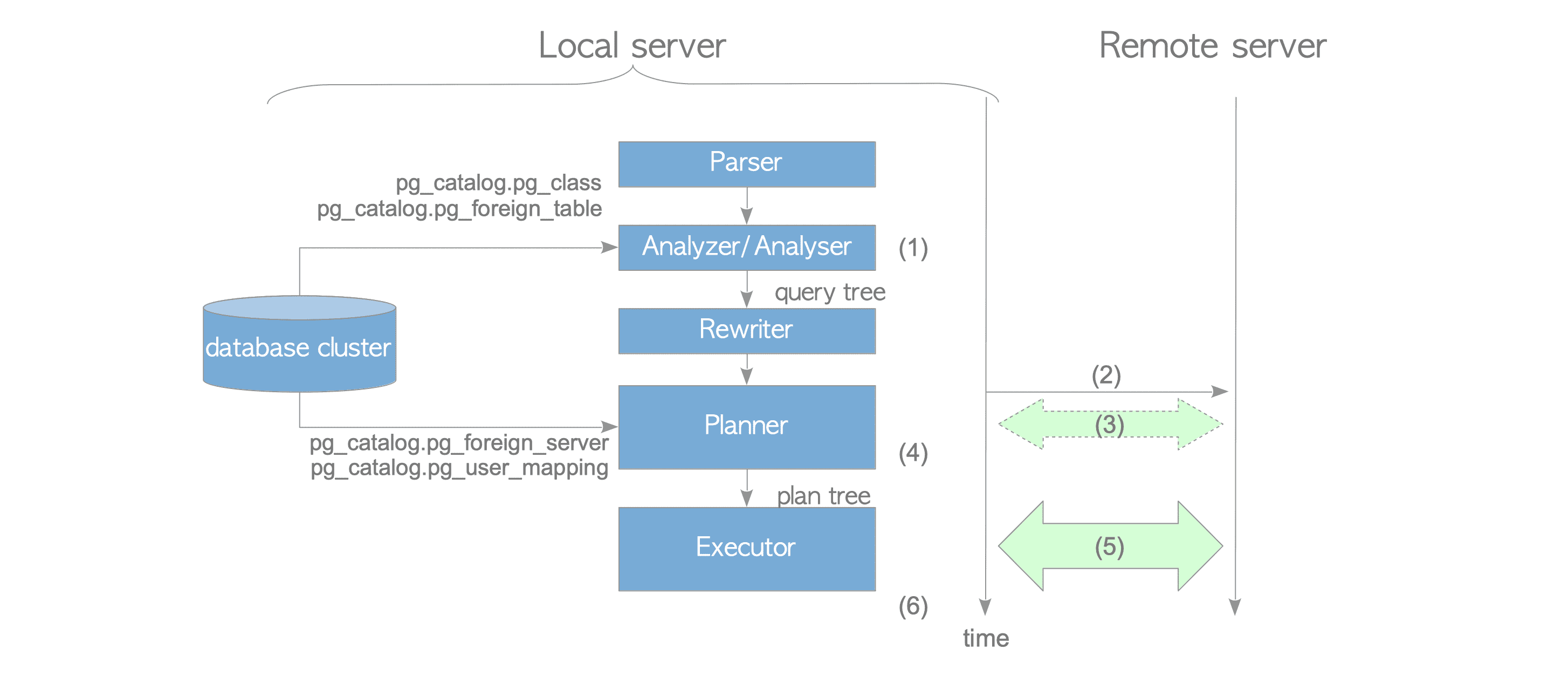
- 解析器通过外部表的定义生成查询树
- 计划器连接到外部服务foreign server
- 获得cost信息。如果use_remote_estimate是true时(默认),计划器会在远程库执行explain获得访问代价(第(3)步);如果是false,那么不会去执行explain(第(3)步)而是在本地进行计算。
- deparse生成远程库SQL文本。fdw直接通过发送SQL文本的方式访问远程库对象,计划器会生成远程库执行的sql文本。执行计划
Remote SQL部分可直接看见deparse生成的SQL文本:
=> explain (verbose) select a from bkb.tab1 where a=1;
QUERY PLAN
-----------------------------------------------------------------
Foreign Scan on bkb.tab1 (cost=100.00..146.86 rows=15 width=4)
Output: a
Remote SQL: SELECT a FROM public.tab1 WHERE ((a = 1))
- 发送SQL语句并接收数据。远程库接收到SQL后自行执行,并按fetch_size(默认100行)返回结果给本地库
代价估算
postgres_fdw可以将远程库的对象访问代价传递给本地库,以计算整个SQL的执行计划代价。然而仅仅返回远程库估算的代价是不够的,还需要考虑远程访问本身的成本。postgres_fdw提供了3个OPTIONS设置来调整外部表的代价估算:
use_remote_estimate:设置为true时,计划器会去远程库explain获得估算的代价,并加上fdw_startup_cost和fdw_tuple_cost的代价计算总的访问代价;如果为false(默认),planner在本地计算并加上fdw_startup_cost和fdw_tuple_cost计算出总的访问代价。本地的外部表统计信息可能与实际不一致。
fdw_startup_cost:外部表的启动代价,默认100。代表在外部服务上创建连接、解析、生成计划的代价
fdw_tuple_cost:扫描外部表每个tuple的额外代价,默认0.01。代表数据传输的代价,延时越高这个设置应该设置的越高。
默认设置下,外部表的startup cost为100:
=> explain select * from bkb.students;
QUERY PLAN
--------------------------------------------------------------------------
Foreign Scan on students (cost=100.00..119.03 rows=301 width=248)
聚合下推
聚合下推是将运算放在远程库执行,本地库直接获得远程库的执行结果。如果没有聚合下推,数据需要全部返回给本地库并由本地库进行计算,这会增加数据传输对SQL执行效率的影响,且会加大本地库的计算负担。
(环境中的bkb.*都是外部表,本地表都是public.*)
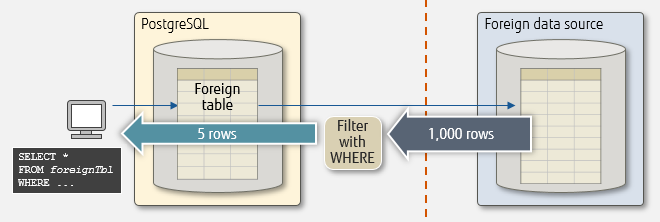
谓词下推
postgres_fdw支持where下推,下推后不需要返回全部数据到本地库
=> explain (verbose,costs off) select f1.a from bkb.tab1 f1 where f1.a=1;
QUERY PLAN
---------------------------------------------------------
Foreign Scan on bkb.tab1 f1
Output: a
Remote SQL: SELECT a FROM public.tab1 WHERE ((a = 1))
pg直接将整个语句发送给远程库执行,where在远程库进行过滤。
sort下推
postgres_fdw支持sort下推,同样可以发送sort给远程库执行。注意sort的默认模式。
=> explain (verbose,costs off) select f1.a from bkb.tab1 f1 order by 1 desc nulls first;
QUERY PLAN
---------------------------------------------------------------------
Foreign Scan on bkb.tab1 f1
Output: a
Remote SQL: SELECT a FROM public.tab1 ORDER BY a DESC NULLS FIRST
join下推
一些无法下推的join不能在远程库进行计算,比如本地表join外部表,只能直接把外部表的查询结果拿到本地进行join
=> explain (verbose,costs off) select f1.a,l2.a from bkb.tab1 f1,tab1 l2 where f1.a=l2.a;
QUERY PLAN
-----------------------------------------------------
Hash Join
Output: f1.a, l2.a
Hash Cond: (l2.a = f1.a)
-> Seq Scan on public.tab1 l2
Output: l2.a, l2.b
-> Hash
Output: f1.a
-> Foreign Scan on bkb.tab1 f1
Output: f1.a
Remote SQL: SELECT a FROM public.tab1
本地表join外部表时,外部表只能全部访问(没有其他where的情况下)返回给本地库,然后又本地库做join操作
两个表都是外部表时可以下推到远程库去执行join操作
=> explain (verbose,costs off) select f1.a,f1.b from bkb.tab1 f1 left join bkb.tab2 f2 on f1.a=f2.a;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Foreign Scan
Output: f1.a, f1.b
Relations: (bkb.tab1 f1) LEFT JOIN (bkb.tab2 f2)
Remote SQL: SELECT r1.a, r1.b FROM (public.tab1 r1 LEFT JOIN public.tab2 r2 ON (((r1.a = r2.a))))
Remote SQL直接将join发送给远程库去执行,本地库只需要等待返回结果。
聚合函数下推
支持聚合函数下推,聚合函数必须是IMMUTABLE的
=> explain (verbose,costs off) select b,count(*),avg(a) from bkb.tab1 group by b;
QUERY PLAN
----------------------------------------------------------------------------
GroupAggregate
Output: b, count(*), avg(a)
Group Key: tab1.b
-> Foreign Scan on bkb.tab1
Output: a, b
Remote SQL: SELECT a, b FROM public.tab1 ORDER BY b ASC NULLS LAST
某些场景并不支持,比如having语句只能在本地filter,Remote SQL没有传递having文本到远程库
=> explain (verbose,costs off) select b,count(*) from bkb.tab1 group by b having count(*)>=2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate
Output: b, count(*)
Group Key: tab1.b
Filter: (count(*) >= 2)
-> Foreign Scan on bkb.tab1
Output: a, b
Remote SQL: SELECT b FROM public.tab1 ORDER BY b ASC NULLS LAST
其他特性
远程执行相关OPTION设置
默认情况下,只有where中的内置运算符和函数能在远程服务执行。不是内置运算符的只能在远程库fetch数据到本地,然后在本地计算。如果内置运算符和函数能在远程执行,且运行结果和本地一致,性能会有提升。
extensions:由用户来指定哪些fdw extension可以用“远程计算”。只能在server层设置。
fetch_size:从远程库获取数据时,一次fetch的数据行数,默认为100。可以在server或table层设置。
更新设置
updatable:默认情况下postgres_fdw的外部表都是可以更新的。不过可以用updatable选项来设置。如果外部表本身就是不可更新的,可以在表级设置updatable为false,使其直接在本地报错。
truncatable:pg14开始postgres_fdw支持truncate外部表,并提供truncatable选项控制外部表是否可以truncate,该选项默认为true。
连接管理
在会话发起第一次外部表访问时,会建立与远程库的连接,只要本地会话没有断开,就会一直使用这个连接。如果使用多个user mapping则会为每个用户映射建立连接。
pg14开始keep_connections选项可以控制这个特性。keep_connections默认为on,表示会话后续可以重用这个连接;为off时事务结束边断开连接。
pg14开始 postgres_fdw_get_connections()可查看连接情况
事务管理
fdw的事务特性需要注意以下几点:
- 远程库按本地库发送的文本执行SQL
- 本地有SERIALIZABLE隔离级别时,远程也是SERIALIZABLE隔离级别,否则远程是REPEATABLE READ隔离级别
- 本地事务提交或回滚时,远程事务也提交或回滚
- fdw不支持2pc事务
因为不支持分布式2PC事务,可能导致事务部分提交。比如以下示例,远程库即使更新失败,本地库的update仍然可以完成。
=> select * from tab1;
a | b
---+-----
1 | abc
=> begin; --开启事务
BEGIN
=> update tab1 set b='123' ; --本地更新数据,成功
UPDATE 6
=> update bkb.tab1 set b='a' where c=1; --远程更新数据,失败
ERROR: 42703: column "c" does not exist
LINE 1: update bkb.tab1 set b='a' where c=1;
=> commit; --事务提交
COMMIT
=> select * from tab1;
a | b
---+-----
1 | 123
无分布式锁管理
fdw没有分布式锁管理,所以也没有分布式死锁检测机制。
如果在本地库产生死锁并且deadlock_timeout设置了一个值(默认1s),会话会产生报错
本地表死锁检测:
| session 1 | session 2 |
|---|---|
| => begin; BEGIN |
|
| => begin; BEGIN |
|
| => update tab2 set b=1; UPDATE 1 |
|
| => update tab1 set b=1; UPDATE 1 |
|
| => update tab1 set b=1; --等待 |
|
=> update tab2 set b=1;sql ERROR: 40P01: deadlock detected |
外部表不会检测死锁:
| session a | session b |
|---|---|
| => begin; BEGIN |
|
| => begin; BEGIN |
|
| => update bkb.tab2 set b=1; UPDATE 1 |
|
| => update tab1 set b=1; UPDATE 1 |
|
| => update tab1 set b=1; --等待 |
|
| => update bkb.tab2 set b=1; --等待 |
异步执行
pg14开始支持postgres_fdw异步执行。在执行计划中存在多个append节点时,可以并行执行,这样能提高多个外部表访问时的性能。
异步执行只能在有多个会话时才能产生,也就是说多个user mapping的情况下才会有异步执行。
async_capable选项控制异步执行特性,默认为false。另外enable_async_append参数也要打开,默认on。
这个特性十分重要,因为异步执行几乎是sharding所必要的特性。它可以实现在扫描每个sharding分片时并行的执行,既同时使用多个分片上的资源进行数据访问,提高sharding数据的访问效率。
并行提交
pg15开始支持postgres_fdw并行提交。远程事务随着本地事务提交而提交,在没有并行提交/回滚时,pg只能串行的提交/回滚各个远程的事务(子事务同样也是顺序提交)。当有很多外部事务关联本地事务时,所有外部事务顺序提交完这种模式效率较低。
此时可以使用并行提交特性,由parallel_commit和parallel_abort选项控制,分别代表并行提交事务和并行关闭事务,默认均为false。
并行提交对性能的提升参考这篇文章
postgres_fdw的版本历史
postgres_fdw非常强大,并且不断的在版本更新中提升。以下表格汇总了各个版本相关postgres_fdw的需要关注的功能提升:
| 版本 | release支持说明 |
|---|---|
| 9.3 | postgres_fdw发布 |
| 9.6 | 支持下推join,sort,update,delete; 支持fetch_size设置 |
| 10 | 可下推聚合函数到外部服务; 下推更多场景下的join |
| 11 | 可下推算子到分区表上; UPDATE/DELETE语句的join可以下推到外部服务 |
| 12 | 下推更多场景下的order by/limit子句; |
| 13 | 加强权限密码认证功能; pg_dump可导出外部表 |
| 14 | 当一个查询有多个外部表时,提供并行扫描能力,由async_capable控制; 支持批量插入; postgres_fdw_get_connections()查看当前外部连接情况; 支持truncate外部表 |
| 15 | 下推CASE表达式; 支持并行提交,由server选项parallel_commit控制 |
| 16 | postgres_fdw可以中断并行事务; 支持外部表analyze_sampling设置; 可通过batch_size选项控制COPY数据到外部表; 允许外部表truncate触发器 |
sharding的实现
基于FDW实现sharding
有许多分支基于PostgreSQL已经实现了sharding功能,比如XC/XL、Citus等等,但是PostgreSQL本身是单实例数据库,目前还没有原生支持sharding。并且虽然很多分支实现了sharding但也会造成其版本跟PostgreSQL社区版本存在lag。
由于SQL/MED本身是为了访问外部数据而定义的标准,所以postgres_fdw可以通过访问外部实例的方式实sharding功能。基于FDW实现sharding的方案目前来看是对代码改动最小的,并且很多分支也是基于这个方案来实现。
所以PostgreSQL原生支持sharding一直呼声很高,社区也考虑过用postgres_fdw实现sharding功能
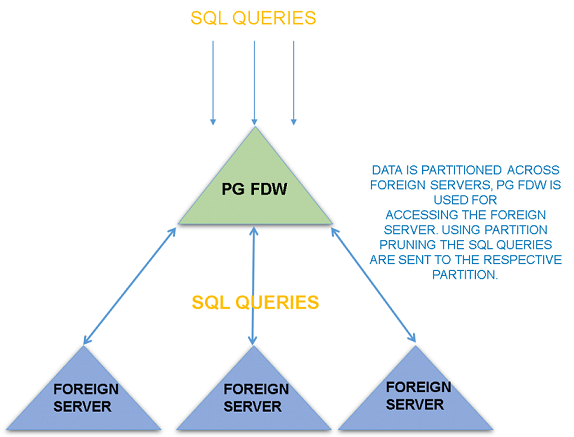
实现sharding的核心功能
一个能够使用的sharding,需要具备一些特性,以下列举几个sharding功能较为受关注的特性,其中一些功能已经在postgres_fdw实现,一些仍然to-do:
- 分区管理。SQL/MED拥有透明访问特点,如果sharding在分区表上实现,sharding以分区的方式附在分区表上,访问分区也是透明的,这样一来业务就完全不需要关注数据路由就可以在数据库层实现sharding。现在原生分区也可以加入外部表。
- 分区优化。把外部表当成分区可以使用分区表上的优化功能,比如分区裁剪、PARTITION WISE JOIN等功能可以极大的降低访问开销。
- 聚合下推。把数据全部采集到本地进行计算明显不是sharding的初衷,把计算放到各自的远程库分片上执行可以充分利用资源,所以DML、谓词下推、聚合函数下推等对于sharding来说很重要。
- 并行扫描。在没有并行扫描时,多个sharding只能顺序执行;有并行扫描后分片可以同时运行。该特性已在pg14实现
- 2PC事务。2PC事务可以保证分布式事务的原子性,如果没有2PC那么可能出现部分分片数据更新,部分分片更新失败的情况。该特性也比较重要,fdw目前还不支持2PC事务。
- 分片管理。外部表的分区不是自动添加的,只能手动完成创建和添加到分区表的操作。如果分区特别多,管理起来会很麻烦
- 全局事务。需要一些机制来保证全局事务一致性,比如全局时钟、全局快照管理等等
- 分布式锁。需要更强大的分布式锁机制
- 批量写入。DML/COPY等分发到分片的操作需要支持批量写入。
总结
- PostgreSQL的FDW功能由SQL/MED标准而来,用来访问外部数据,并且支持非常多类型的数据访问
- FDW有4个基本对象:foreign data wrapper,server,user mapping,foreign table
- postgres_fdw有很多功能提升和性能优化,可以将算子下推到远程库
- 基于postgres_fdw可以实现sharding功能,有些功能还有待完善
参考
https://www.interdb.jp/pg/pgsql04.html
https://www.postgresql.org/docs/13/postgres-fdw.html
https://www.postgresql.org/docs/current/file-fdw.html
https://wiki.postgresql.org/wiki/WIP_PostgreSQL_Sharding
https://www.percona.com/blog/postgres_fdw-enhancement-in-postgresql-14/
https://www.percona.com/blog/foreign-data-wrappers-postgresql-postgres_fdw/
https://www.percona.com/blog/parallel-commits-for-transactions-using-postgres_fdw-on-postgresql-15/
https://www.enterprisedb.com/blog/postgresql-aggregate-push-down-postgresfdw
https://www.postgresql.fastware.com/postgresql-insider-fdw-ove
https://momjian.us/main/writings/pgsql/sharding.pdf
https://www.slideserve.com/johnna/sql-med-and-more-powerpoint-ppt-presentation
https://dbaplus.cn/news-19-2090-1.html
https://www.highgo.ca/2019/08/08/horizontal-scalability-with-sharding-in-postgresql-where-it-is-going-part-3-of-3/
https://www.highgo.ca/2021/06/28/parallel-execution-of-postgres_fdw-scans-in-pg-14-important-step-forward-for-horizontal-scaling/
