




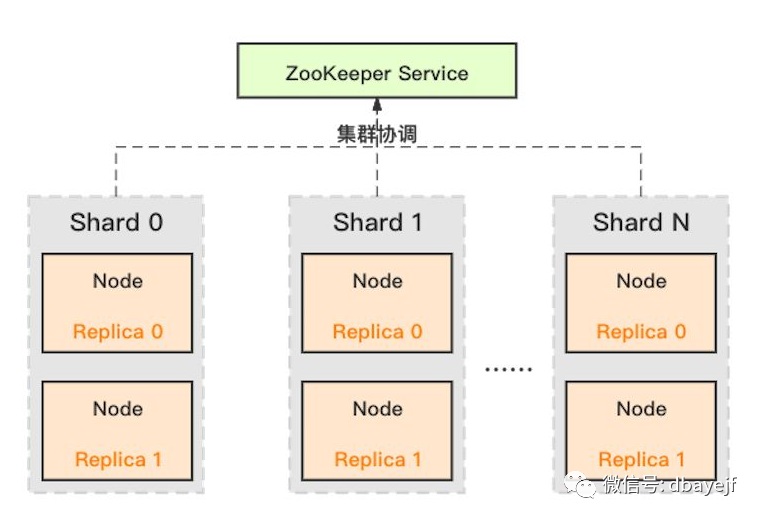
数据分片
横向扩展,把数据水平切分到不同服务器上
通过Distributed表引擎查询所有分片数据
数据副本
保障数据高可用
依赖Zookeeper,存放元数据
查询能力提升
表级别
只有 MergeTree 系列里的表可支持副本
ReplicatedMergeTree
ReplicatedSummingMergeTree
ReplicatedReplacingMergeTree
ReplicatedAggregatingMergeTree
ReplicatedCollapsingMergeTree
ReplicatedVersionedCollapsingMergeTree
ReplicatedGraphiteMergeTree
多分片2副本集群架构
2分片2副本配置文件示例
/etc/metrika.xml
ck01配置文件内容
<yandex>
<!--分片和副本相关配置-->
<clickhouse_remote_servers>
<replica_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ck01</host>
<port>9000</port>
<password>xxx</password>
</replica>
<replica>
<host>ck02</host>
<port>9000</port>
<password>xxx</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ck03</host>
<port>9000</port>
<password>xxx</password>
</replica>
<replica>
<host>ck04</host>
<port>9000</port>
<password>xxx</password>
</replica>
</shard>
</replica_cluster>
</clickhouse_remote_servers>
<!--zookeeper相关配置-->
<zookeeper-servers>
<node index="1">
<host>ck01</host>
<port>2181</port>
</node>
<node index="2">
<host>ck02</host>
<port>2181</port>
</node>
<node index="3">
<host>ck03</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!--宏变量-->
<macros>
<shard>01</shard>
<replica>ck01</replica>
</macros>
</yandex>
ck02配置文件区别
分片需要一致,replica不同
<macros>
<shard>01</shard>
<replica>ck02</replica>
</macros>
配置好后通过sql查询集群情况
select * from system.clusters c副本写入流程
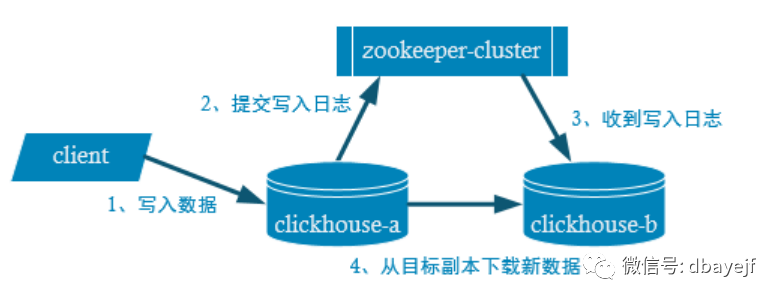
集群写入流程
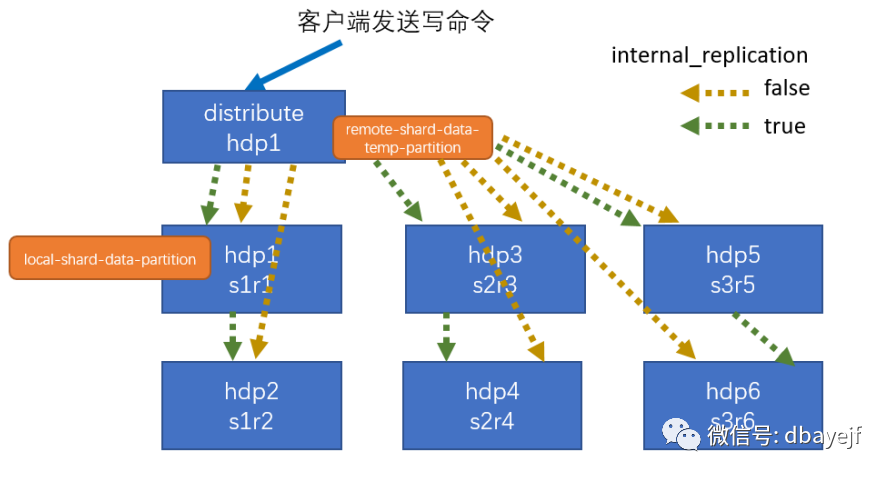
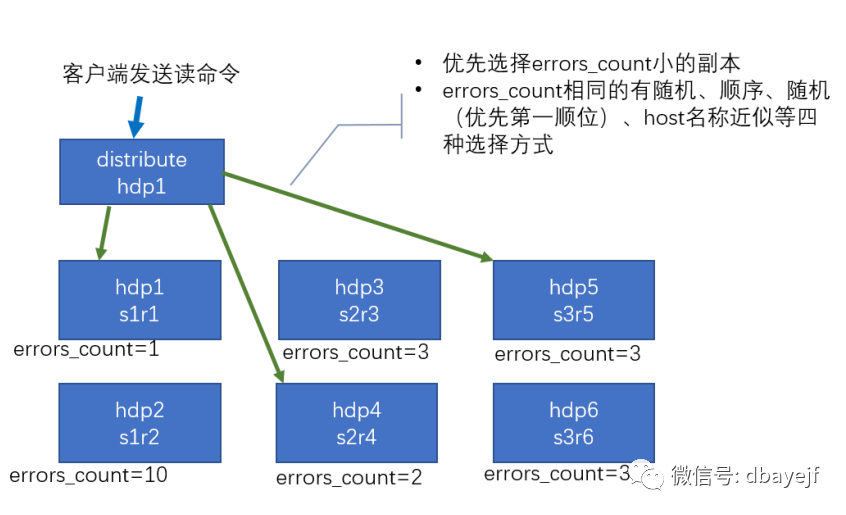
集群读取流程
复制表
创建示例:
drop table default.tb1_replica on cluster replica_cluster;
CREATE TABLE default.tb1_replica on cluster replica_cluster
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/default/tb1_replica', '{replica}')
-- PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);
参数说明:
ReplicatedMergeTree(zoo_path,replica)
zoo_path
— ZooKeeper 中该表的路径。replica
— ZooKeeper 中的该表的副本名称。
可以在zookeeper上看到创建的node节点
[zk: localhost:2181(CONNECTED) 28] ls clickhouse/tables/01/default/tb1_replica/replicas
[ck01, ck02]
插入数据,验证复制
向ck01插入数据
ck01 :) insert into default.tb1_replica values(now(),1,11);
INSERT INTO default.tb1_replica VALUES
Query id: 520facf4-e067-4d47-8a14-06b2b4f6a785
Ok.
1 rows in set. Elapsed: 0.076 sec.
在ck02上查询得到,说明数据通过复制表同步过来了
ck02 :) select * from tb1_replica;
SELECT *
FROM tb1_replica
Query id: b50f9cf8-cfb8-4dda-82ad-c7098bb53422
┌───────────EventDate─┬─CounterID─┬─UserID─┐
│ 2021-12-22 14:07:13 │ 1 │ 11 │
└─────────────────────┴───────────┴────────┘
1 rows in set. Elapsed: 0.003 sec.
删除复制表
注意:正常删除复制表时,zookeeper上的node节点也是删除,但是异步的,不是马上删除
drop table default.tb1_replica on cluster replica_cluster;删除复制表后马上创建会报错
DB::Exception: There was an error on [ck02:9000]: Code: 253, e.displayText() = DB::Exception: Replica clickhouse/tables/01/default/tb1_replica/replicas/ck02 already exists如果马上同时删除znode节点,需要加上sync
drop table default.tb1_replica on cluster replica_cluster sync;又或者删除表后,到zk上删除对应的node节点
分布式表
创建语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
参数说明:
cluster
- 服务为配置中的集群名database
- 远程数据库名table
- 远程数据表名sharding_key
- (可选) 分片keypolicy_name
- (可选) 规则名,它会被用作存储临时文件以便异步发送数据
示例:
基于复制表创建分布式表
CREATE TABLE default.tb1_all ON CLUSTER replica_cluster
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
)
ENGINE = Distributed(replica_cluster, default, tb1_replica,UserID);
生成测试数据
drop table generate_engine_table;
CREATE TABLE generate_engine_table
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = GenerateRandom(1, 5, 3);
向复制表插入数据并验证
insert into tb1_replica select * from generate_engine_table limit 1000000;小结
使用离线拷贝文件的方法来恢复或迁移复制表会有问题,报错如下
SQL 错误 [231]: ClickHouse exception, code: 231, host: 192.168.43.130, port: 8123; Code: 231, e.displayText() = DB::Exception: The local set of parts of table default.tb1_replica doesn't look like the set of parts in ZooKeeper: 1.00 thousand rows of 1.00 thousand total rows in filesystem are suspicious. There are 1 unexpected parts with 1000 rows (0 of them is not just-written with 0 rows), 0 missing parts (with 0 blocks). (version 21.3.4.25 (official build))复制表的副本,在zk上同一replicas目录下的节点才会互相同步
[zk: localhost:2181(CONNECTED) 6] ls clickhouse/tables/01/default/tb1_replica/replicas
[dn2, dn1]表default.tb1_replica在dn1和dn2上的复制表互为副本
示例配置中ck01和ck02是在同一分片中的不同副本,创建复制表时,两个副本数据一致。
如果在replica_cluster集群上创建的不是复制表时,并且之上有分布式视图的话,向视图插入数据,数据会分布到不同副本中。
使用复制表时,metrika.xml配置文件要注意shard分片需要一致,replica不同代表同一分片不同的副本
<macros>
<shard>01</shard>
<replica>ck02</replica>
</macros>在zk上路径
[zk: localhost:2181(CONNECTED) 5] ls /clickhouse/tables/01/default/tb1_replica/replicas
[ck01, ck02]
