




最近知乎小说推文的项目很火,主要路径是:通过抖音为盐选专栏导流,赚取佣金。具体做法是在盐选专栏上选择要付费阅读的,申请关键字绑定,再把前两章文本配音,以自然风光,美食制作等解压视频为背景,制作成自己的视频,发布在抖音上,引导用户去知乎付费阅读,即可抽成,每单6元,每个月都需开通会员。看起来钱景不错,但是社恐,怕声音不好听,最关键的是懒,不想每次配音,那就用python来自动转换吧。
01 文本处理
从知乎中选取可以推广的小说节选,保存在txt中,格式统一用utf-8,文件名就用小说名称。
文本太长,肯定不想手动去划分,采用脚本每次分隔500字左右,以句号分隔,每篇文章做三段配音,配音名称也采用小说名称,多余文本暂时舍弃,后续如果想多分几段,改参数即可。
1、遍历文件夹下的txt 懒人当然不想一次次的打开脚本去跑,循环读取文件夹下准备好的小说片段。
def list_file(path, len):
dirs = os.listdir(path)
for file in dirs:
if os.path.splitext(file)[1] == '.txt':
full_file_path = os.path.join(path, file)
file_path = os.path.join(path, os.path.splitext(file)[0])
split_file(full_file_path,file_path, len)
# print(os.path.splitext(file))

2、分割文本 由于REST API 仅支持最多512字(1024字节)的音频合成,文本长度超过限制会报错,合成的文件格式为mp3。如果本文长度较长,需要采用多次请求的方式。通常正常语速,500字转成语音大概是1分40秒左右。
def split_file(path,file_name,len):
with open(path, 'r', encoding='utf-8', errors='ignore') as file:
file_str = file.read()
if file_str.__len__() <= 0: return
i = 0
while i < 3:
substr = file_str[0:len]
index = substr.rfind('。')
if index <= 0 : return
substr = file_str[0:index+ 1]
print(substr)
tts(substr,file_name + '_' + str(i))
print(file_name + '_' + str(i) + ' to voice success.')
file_str = file_str[(index + 1):]
i = i + 1
if(file_str.__len__() < len):
break
02 申请百度sdk
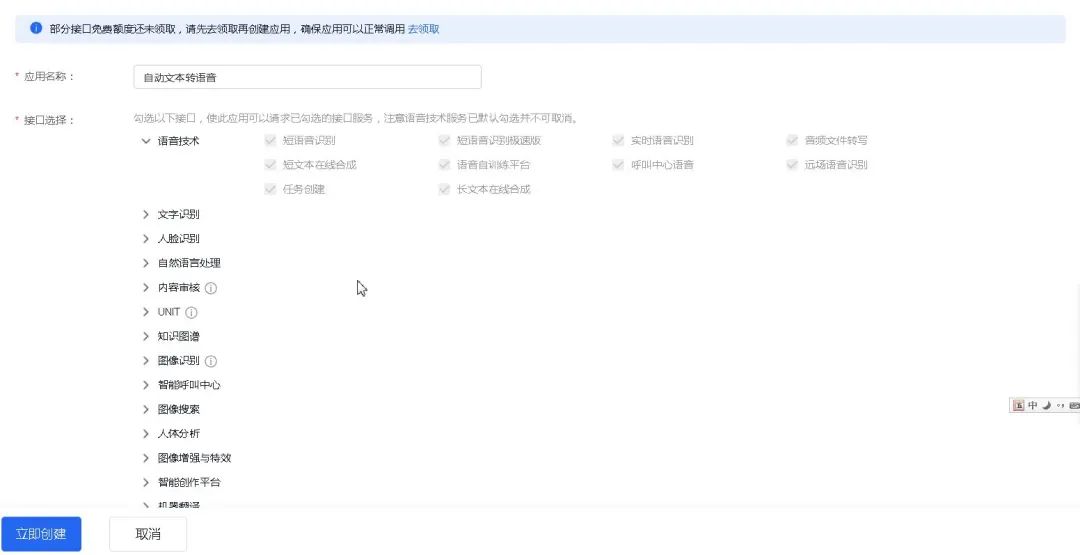
百度智能云使用前需要先实名认证,这部分提前准备好,我们从领取能力开始说明。
1、领取能力
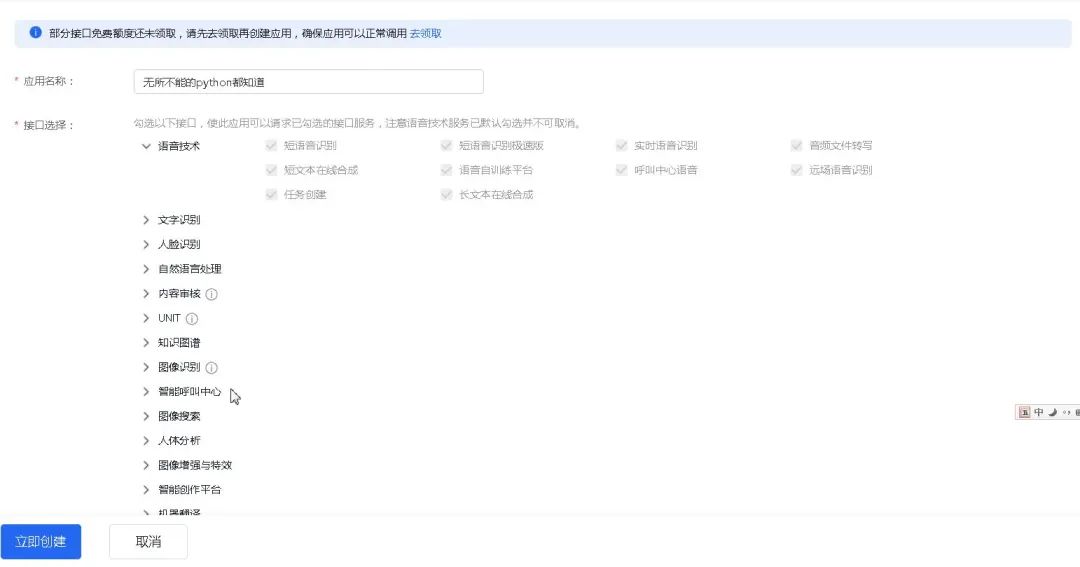
2、创建应用
创建应用,获取密钥,随便取个应用的名称,这里取个朴素的名字“无所不能的python都知道”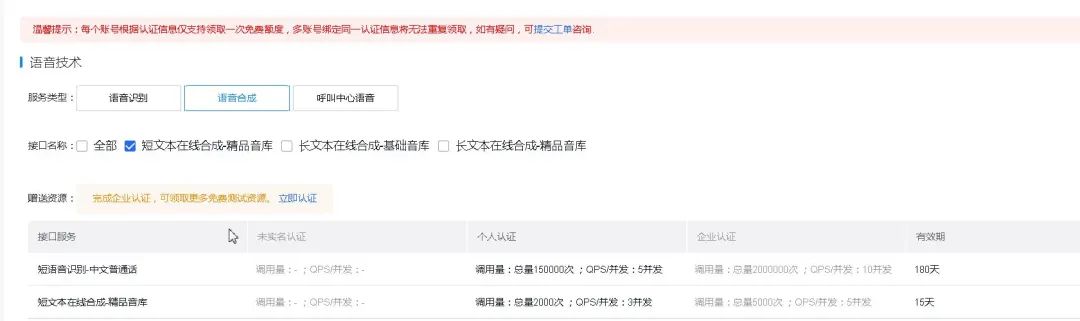
3、复制api_key、secret_key
# 填写网页上申请的appkey 如 API_KEY="g8eBUMSokVB1BHGmgxxxxxx"
API_KEY = '4E1BG9lTnlSeIf1NQFlrxxxx'
# 填写网页上申请的APP SECRET 如 SECRET_KEY="94dc99566550d87f8fa8ece112xxxxx"
SECRET_KEY = '544ca4657ba8002e3dea3ac2f5fxxxxx'
4、生成token 拿到钥匙后,就可以准备去撬门了。按照官方文档,调用百度认证接口,生成token。
""" TOKEN start """
TOKEN_URL = 'http://aip.baidubce.com/oauth/2.0/token'
SCOPE = 'audio_tts_post' # 有此scope表示有tts能力,没有请在网页里勾选
def fetch_token():
print("fetch token begin")
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not SCOPE in result['scope'].split(' '):
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s ; EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
""" TOKEN end """
03 生成配音文件
拿到token后,设置常用的配置,如语速,播音员,生成音频格式等,这些做为入参,请求百度TTS接口,将文件流写入本地文件中,通常采用mp3格式,一个音频200多k。
def tts(TEXT,file_name):
token = fetch_token()
tex = quote_plus(TEXT) # 此处TEXT需要两次urlencode
# print(tex)
params = {'tok': token, 'tex': tex, 'per': PER, 'spd': SPD, 'pit': PIT, 'vol': VOL, 'aue': AUE, 'cuid': CUID,
'lan': 'zh', 'ctp': 1} # lan ctp 固定参数
data = urlencode(params)
print('test on Web Browser' + TTS_URL + '?' + data)
req = Request(TTS_URL, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
headers = dict((name.lower(), value) for name, value in f.headers.items())
has_error = ('content-type' not in headers.keys() or headers['content-type'].find('audio/') < 0)
except URLError as err:
print('asr http response http code : ' + str(err.code))
result_str = err.read()
has_error = True
save_file = "error.txt" if has_error else file_name+'.' + FORMAT
with open(save_file, 'wb') as of:
of.write(result_str)
if has_error:
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print("tts api error:" + result_str)
print("result saved as :" + save_file)
04 常用配置
基础音库中选择发音人:也就是虚拟人物,表示不同音色。基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫
度丫丫比较嗲,甜甜的,适合言情,女生小说,度逍遥比较阳刚,严肃,适合历史,玄幻小说。
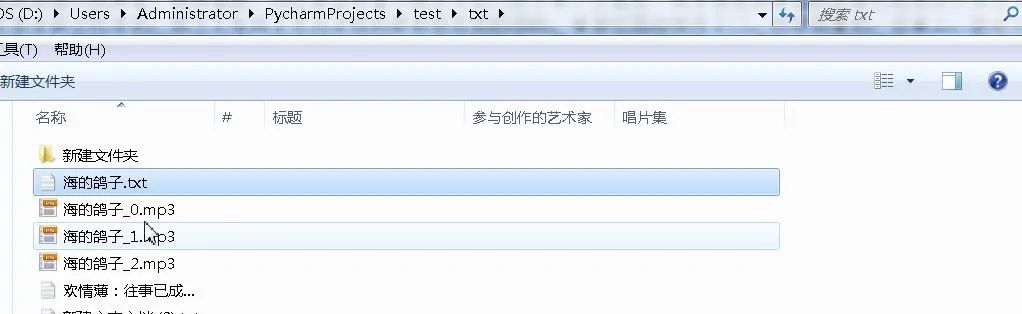
至此配音文件已经全部生成,后期合并到视频素材中即可。
# 发音人选择, 基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫,
# 精品音库:5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
PER = 4
# 语速,取值0-15,默认为5中语速
SPD = 5
# 音调,取值0-15,默认为5中语调
PIT = 5
# 音量,取值0-9,默认为5中音量
VOL = 5
# 下载的文件格式, 3:mp3(default) 4:pcm-16k 5:pcm-8k 6. wav
AUE = 3
FORMATS = {3: "mp3", 4: "pcm", 5: "pcm", 6: "wav"}
FORMAT = FORMATS[AUE]
CUID = "123456PYTHON"
TTS_URL = 'http://tsn.baidu.com/text2audio'
04 结论
小说文本也可以通过爬虫来做,但是素材采集类的决定了有没有人看,建议人工来做,小说推文的音频就准备好了,后面再自动化配上视频和字幕。灵性的事情人工做,呆板的事机器做。
PS:Python都知道技术交流群(技术交流、摸鱼、白嫖课程为主)又不定时开放了,感兴趣的朋友,可以在下方公号内回复:666,即可进入。
老规矩,道友们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!
