




OCR(optical character recognition)文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
下边以百度飞浆为平台,juptyter为呈现来演示如何在线开发一个简易的图片文字识别应用。可在该应用的基础上进行扩展、封装成各业务场景的识别应用,例如:身份证号码、发票、车牌号、等业务场景:
1、打开登录页面
http://nangs.vip:5555/login
2、输入密码
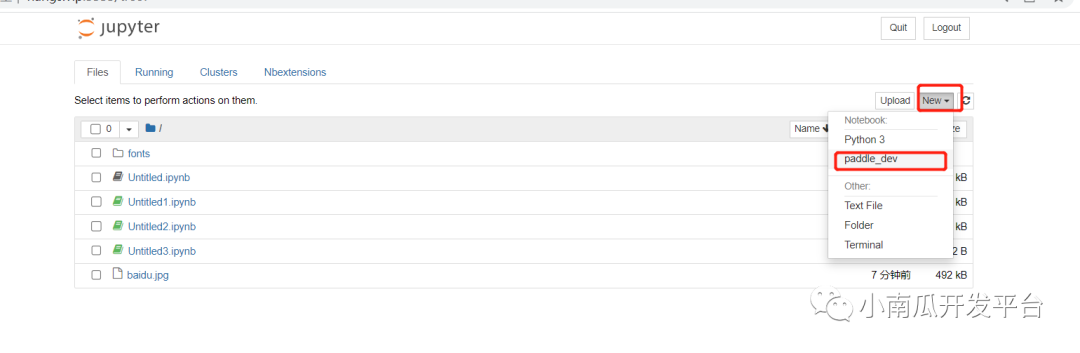
3、新建代码文件
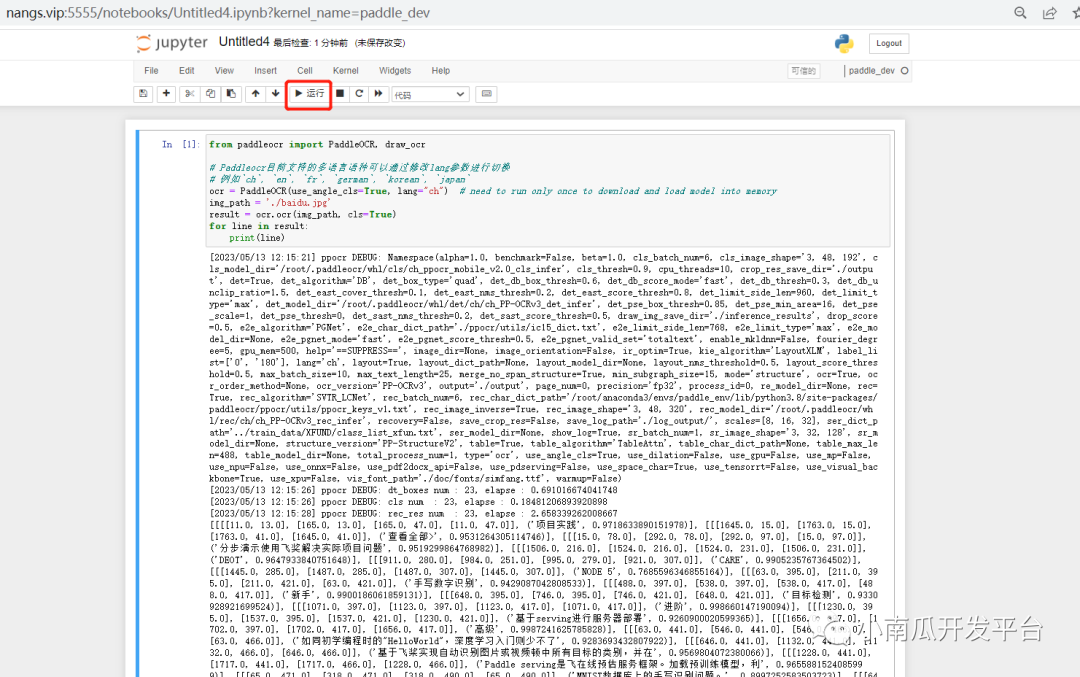
4、输入代码块
from paddleocr import PaddleOCR, draw_ocr# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memoryimg_path = './baidu.jpg'result = ocr.ocr(img_path, cls=True)for line in result:print(line)
5、点击运行按钮
点击运行后,输出运行的结果
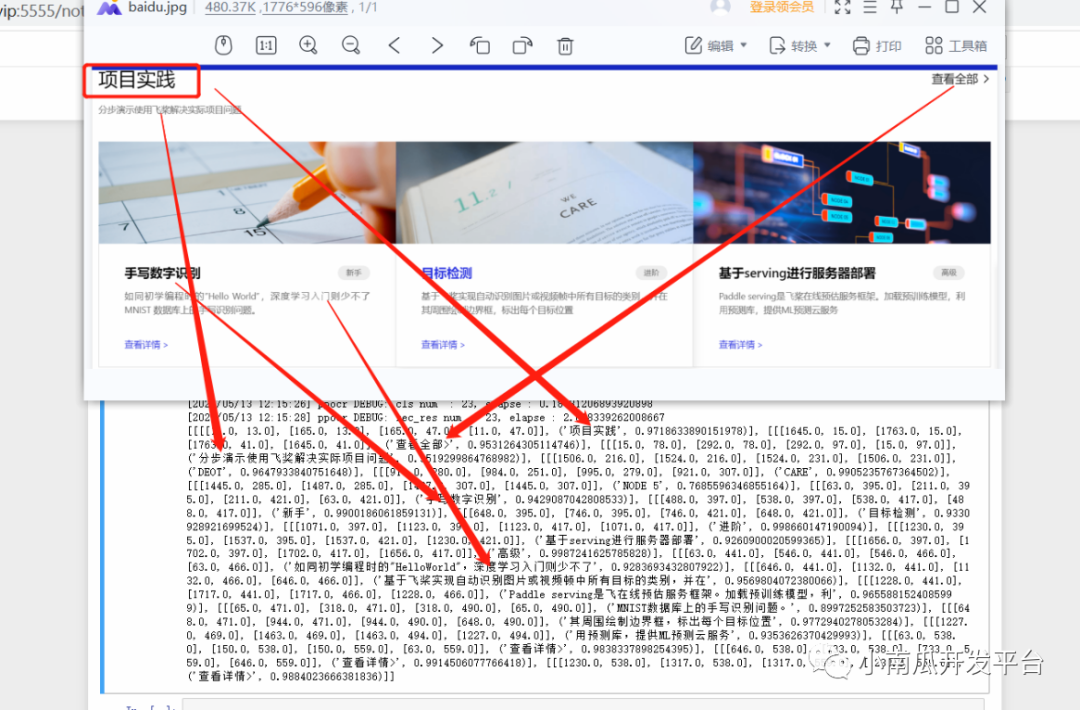
6、输出结果
对比识别结果与图片文字的效果
写在最后:
学习完本套课程,您将能单独完成OCR文字识别、人脸识别等人工智能技术。结合实际业务需求,可做出各类场景产品
文章转载自小南瓜开发平台,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
