




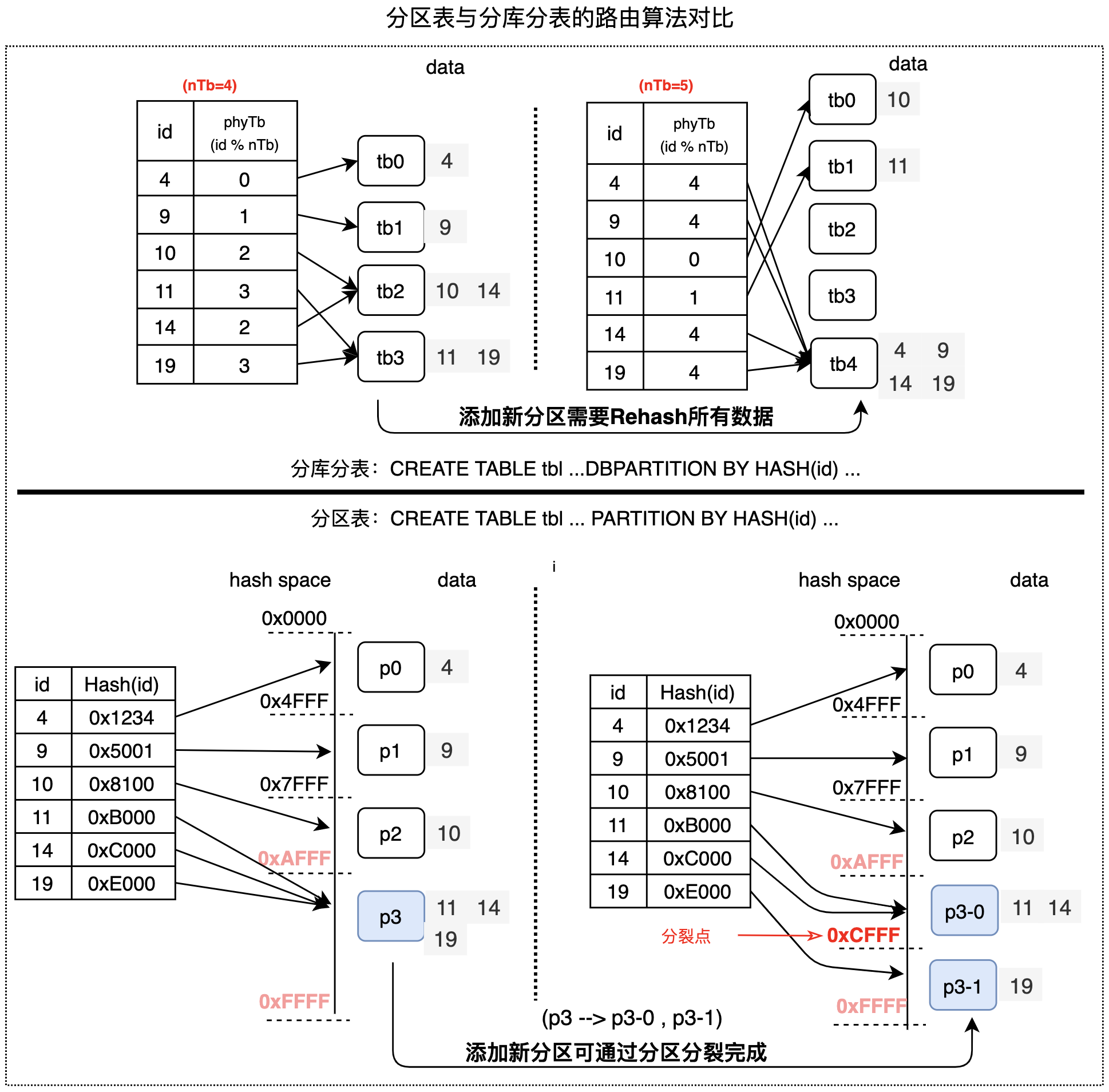
分区表与分库分表最重要的区别,是它们的分区会使用完全不同的路由算法。如下图所示:
- 分库分表的路由算法是HASH值按物理分表数目取模,如果要变更分区数目(例如分表数目由4个变成5个),所有数据都需要进行rehash,因此,DRDS模式的分库分表无法提供分区级的变更能力;
- 分区表的默认路由算法是基于range的一致性HASH算法,这种算法天然支持通过分裂、合并操作等变更分区,并且无须rehash所有数据,因此,AUTO模式的分区表具备分区级的变更能力。
功能对比
与DRDS模式数据库相比,AUTO模式数据库新增了自动分区、热点分裂、分区调度和TTL表等新特性,并在很多其它方面(如分区管理、拆分变更等)做了大量工作以优化分布式体验。
AUTO模式数据库与DRDS模式数据库主要功能对比:
| 功能项 | AUTO模式数据库 | DRDS模式数据库 | |
|---|---|---|---|
| 透明分布式 | 默认主键分区 | 支持。若建表时不指定分区定义,将自动按主键进行分区。 | 不支持。 |
| 默认全局二级索引 | 支持。索引不指定分区列时,将自动索引列分区。 | 不支持。 | |
| 负载均衡调度 | 支持。 | 不支持。 | |
| 热点散列能力 | 支持。 | 不支持。 | |
| 分区策略 | Hash分区 & Key分区 | 支持。采用一致性哈希的路由算法,并支持热点散列。 | 支持采用按分区数取模的路由算法,不支持热点散列。 |
| Range分区 & Range Columns分区 | 支持,支持热点散列。 | 不支持。 | |
| List分区 & List Columns分区 | 支持。 | 不支持。 | |
| 向量分区键(使用多个列作为分区键) | 支持。分区键支持按向量分区,例如PARTITION BY KEY(c1,c2,c3)。 | 不支持。 | |
| 分区键字符校验集 | 支持。 | 不支持。 | |
| 单表 & 广播表 | 支持。 | 支持。 | |
| 分区管理 | 创建、删除、修改分区 | 支持。 | 不支持。 |
| 分裂、合并分区 | 支持。 | 不支持。 | |
| 迁移分区 | 支持。 | 不支持。 | |
| 截断分区 | 支持。 | 不支持。 | |
| 分区透视 | 即将上线将支持自动分析热点分区。 | 不支持。 | |
| 拆分变更 | 调整表类型(单表、广播表与分区表互转) | 支持。 | 支持。 |
| 调整分区定义(包括分区数目、分区键类型、分区策略等) | 支持。 | 支持。 | |
| 弹性扩(缩)容 | 是否有停写阶段 | 否。 | 是(短暂的停写)。 |
| 是否允许其他DDL | 是。 | 否。 | |
| Locality | 静态隔离 | 支持,创建库、表和分区时指定物理存储资源。 | 支持,创建库、表时指定物理存储资源。 |
| 动态隔离 | 支持,动态调整库表所在的物理存储资源。 | 不支持。 | |
| 是否与扩缩容兼容 | 是。 | 否。 | |
| 分区裁剪 | 前缀分区裁剪 | 支持。 例如,按 | 不支持。 |
| 计算表达式常量折叠 | 支持。 例如,对含计算表达式的条件 | 不支持。分区键条件要求必须是常量(如pk = 123);如果分区键是计算表达式如pk = POW(2, 4),将执行全表扫描。 | |
| 分区路由大小写敏感及忽略行尾空格 | 支持。 支持通过指定分区键的字符校验集(Collation)来决定分区路由是否需要区分大小写以及是否需要忽略行尾空格。 | 不支持。分区列不支持使用Collation,Hash算法只支持大小写敏感,不支持忽略行尾空格。 | |
| JOIN计算下推 | 支持。 支持在分区的分裂、合并与迁移等操作期间,JOIN计算下推不受影响。 | 支持。 | |
| 分区选择 | 支持。 支持分区选择语法查询特定分区,例如 | 不支持。 | |
| TTL(分区的生命周期管理) | 支持。 | 不支持。 | |
| AUTO_INCREMENT | 支持。保证全局唯一性、单调递增和连续性。 | 支持。保证全局唯一性,不保证单调递增和连续性。 | |
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
