




Greenplum 概述
Pivotal Greenplum 数据库软件是由顶级专家团队打造的高性能、无共享、大规模并行处理(massively parallel processing (MPP))的数据库软件产品,它包含大规模并行计算技术和数据库技术最新的研发成果:包括无共享/MPP,按列存储数据库,数据库内压缩,MapReduce,永不停机扩容,多级容错等等。在同等硬件条件下,比竞争对手的数据库产品处理速度能快出 10 倍以上。非常适用于海量数据处理,特别是时间要求高的数据分析、数据查询等场合。最重要
的是 Greenplum 数据库支持使用 X86 架构的开放硬件环境。该数据库软件被业界认可为扩展能力最大的分析型(OLAP)数据库软件。已有 1000 多家世界级重大客户采用该软件,例如:NYSE,NASDAQ,AIG,CIA,德意志银行,美国联邦储备委员会,支付宝,NTT-DoCoMo,T-Mobile,Skype,WalMart,中国联通,太平洋保险等,这些客户中大多数 Greenplum 数据仓库所管理的数据量都超过 100TB。每一天,全球有数亿级的用户在直接、间接用到 Greenplum 发明的数据库平台。
Pivotal Greenplum 海量并行数据库是采用 MPP 架构的高性能数据库,架构在开放式 X86 硬件集群上,提供了高效能、低成本、灵活扩展、高可靠易维护等功能特征;建议采用 Greenplum MPP 数据库作为客户的基础数据平台,充分应用 Greenplum 管理海量数据、大规模并行处理的优势,将为客户提高数据处理效率、数据管控能力的同时,降低系统总体 TCO,并且为将来的 IT 架构的灵活扩展提供技术支撑。
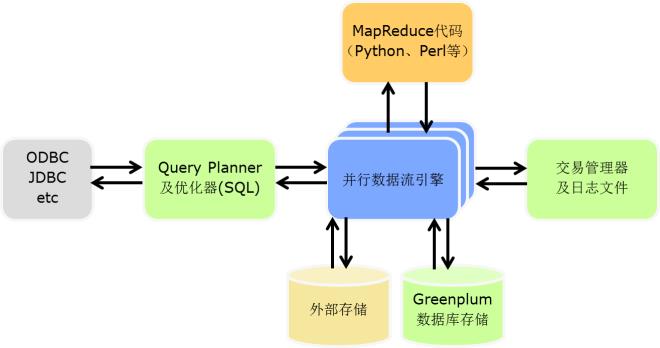
Greenplum MPP 数据库产品架构图如下:
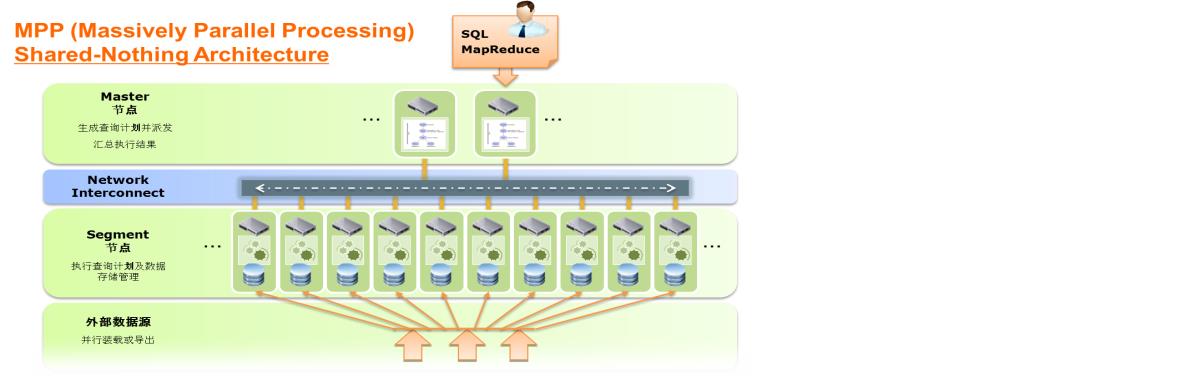
Greenplum高性能
Greenplum 数据库软件是为大规模数据和复杂查询功能所设计。Greenplum 高性能的特性主要应用在客户管理,数据仓库, BI,ODS,数据集市,数据挖掘,经营分析,网络分析,知识库管理,成本效益分析等项目。
Greenplum 因为采用了下列技术提供高性能计算:
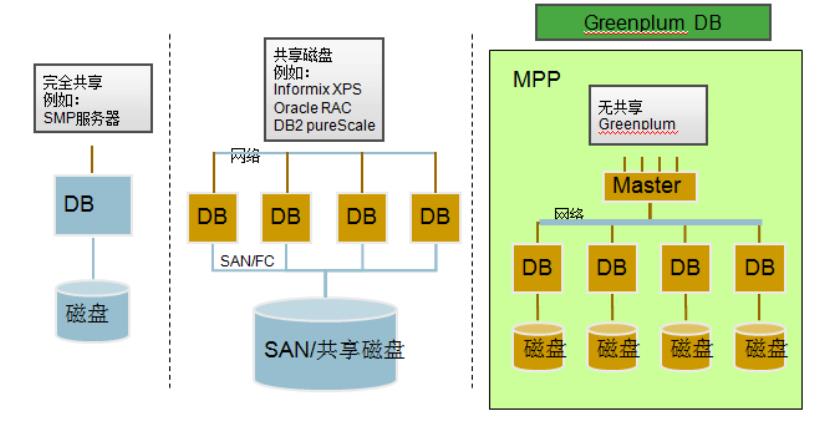
- 无共享/MPP 架构
数据分布在所有的并行节点上,每个节点只处理其中一部分数据,所有的节点同时进行并行处理,同时由于所有节点之间完全无共享,无 I/O 冲突,所以可以做到最优化的 I/O 处理。
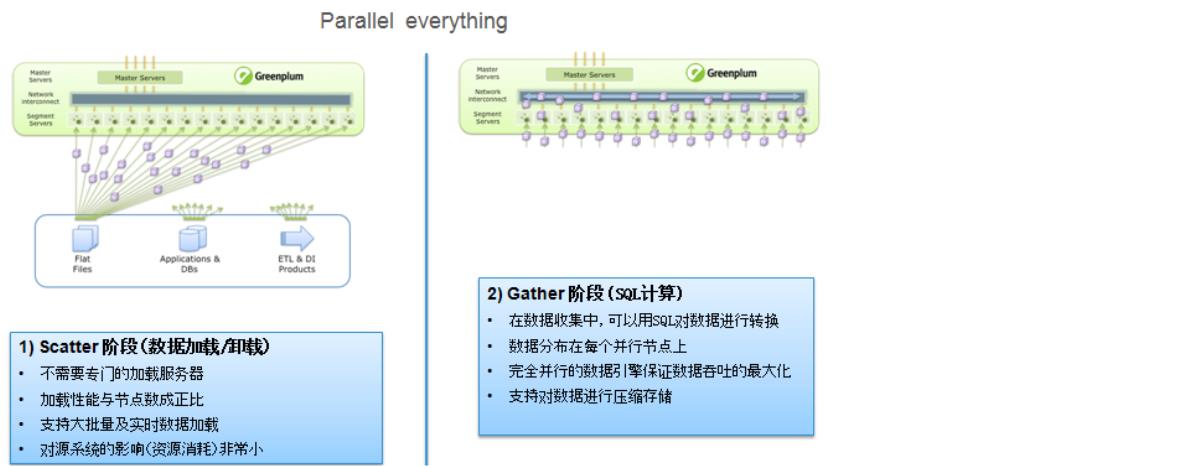
- Scatter/Gather 并行数据流技术:
Greenplum 采用独特的 Scatter/Gather 并行数据流技术,Scatter 阶段用于数据加载时,外部数据采用并行、直接方式“Scatter”到 Segment 节点,无需通过 Master 节点,因此达到极高的性能,且加载性能与 Segment 数成正比。例如,在实际项目中,Greenplum 16 个节点的集群,加载性能可以达到 16 TB/小时;
Greenplum 在数据查询时,采用 Gather 技术进行数据收集,每个节点并行处理各自的数据,通过完全的并行方式实现很高的 SQL 查询性能;
- 支持按行和按列的存储
在 OLAP 应用中,用户的查询都是基于特定的列来选择的。数据按列存储,可以明显提升数据读取速度,提升查询性能。
- 查询性能线性扩展
由于具有 MPP 无共享的本质特性,所以当增加 1 倍的节点的时候,相当于每个节点上的数据量降低为原来的一半,计算量也是原来的一半,性能自然能够提升 1 倍,从而实现查询性能的线性增长。
- 加载性能线性扩展
Greenplum 数据加载是直接和 Segment 通信加载数据。因此当增加 1 倍的节点的时候,相当于每个节点上的加载数据量降低为原来的一半,性能自然能够提升 1 倍,从而实现加载性能的线性增长。
Greenplum 高可用性
Greenplum 数据库软件自己包含多层次容错和冗余能力,这是云计算架构软件的一个重要特征。该功能保证整个数据仓库系统在遇到硬件、软件的故障的情况下,仍然自动继续运行,数据依旧完整。
高可用性体现在如下几个方面:
- 服务器HA:
– 每个sever允许两块盘失败
– 更换新盘后Raid5自动重建data
– 硬件组件冗余保护(Fan, PSU…)
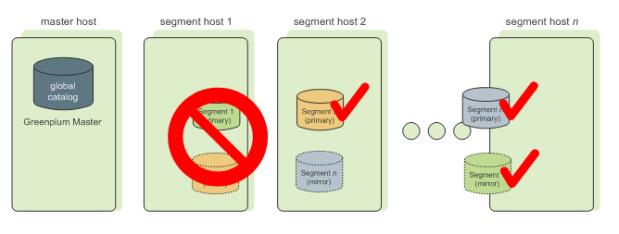
- GP数据库镜像节点保护:
– 每个节点的数据自动镜像到另一个节点中,节点互相备份
– Segment 节点故障时,自动启动备份实例,保证用户数据完成和服务不中断
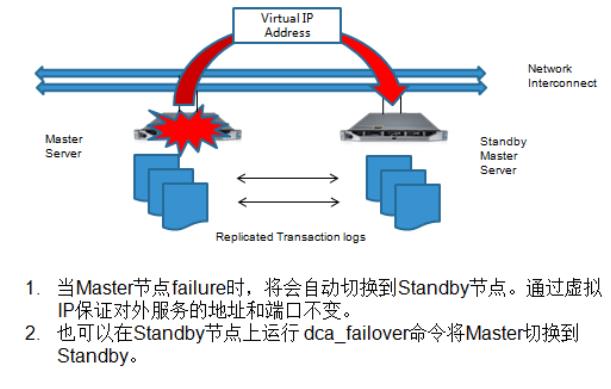
- Master 节点自动failover
– Master Server 和 standby master server 自动数据同步
– Master Server 失败时自动切换到 Standby
– 采用 Virtual IP 方式,对外服务地址不变
Greenplum更快的TP处理能力
在最新的第六代版本中,Greenplum结合了快速分析读取与改进的写入性能,可以帮助用户将各种分析和运营工作负载整合到一个环境中,例如点查询、数据科学探索、快速事件处理和长期运行的分析查询。相较于Greenplum 5,最新版本可以支持更大规模、更多并发任务的处理。将工作负载整合到一个数据库引擎之后,用户能够分析更多数据,并且避免在细分的数据库环境之间进行不必要的数据移动
- 内核升级,继承postgresql9.6新特性
1. 支持unnest() 数组函数,可以将数组转换成行的集合(PostgreSQL 8.4引入)
2. 支持用户自定义的I/O conversion casts. (PostgreSQL 8.4引入)
3. 支持列级别的权限(PostgreSQL 8.4引入)
4. 增加了pg_db_role_setting系统表,为特定数据库和角色组合的配置提供了支持(PostgreSQL 9.0引入)
5. pg_class系统表里的relkind列的值已改成与PostgreSQL 9.3的条目相同
6. 支持GIN索引方法(PostgreSQL 8.3引入)
7. 支持jsonb数据类型(PostgreSQL 9.4引入)
8. DELETE,INSERT和UPDATE语句支持WITH子句,即CTE (common table expression) (PostgreSQL 9.1引入)
对于WITH子句,RECURSIVE关键字还处于试验阶段
9. 列(column)级别支持指定排序规则和字符集的Collation(PostgreSQL 9.1引入)
- 更加快速的Zstandard压缩算发
Greenplum 6.0增加了数据库某些操作和AO表存储的zstd (Zstandard)压缩。
- 放宽分布列的规则
在之前的版本,如果在建表的时候同时指定了分布列和唯一索引,则分布列必须和唯一索引列相同,或者是唯一索引列集的左前缀。Greenplum 6里取消了该限制,分布列可以是索引列的任何子集。
这个改变同时影响了Greenplum 6选择默认分布键的规则。如果gp_create_table_random_default_distribution是关闭的(默认值),并且建表时未指定DISTRIBUTED BY子句,Greenplum会根据如下规则选择分布键:
1. 如果使用了LIKE或INHERITS,则依照源表或父表的分布列
2. 如果指定了主键或唯一(UNIQUE)索引约束,选择键集合的最大子集作为分布列
3. 如果既未指定约束,也未使用LIKE或INHERITS,则选择第一个合适的列作为分布键(几何数据列和用户自定义数据列不能作为分布键)
- 新增复制表,提升数据访问效率
CREATE TABLE支持DISTRIBUTED REPLICATED分布策略。在该分布策略下,Greenplum会将表的所有数据分发到所有节点上。
- PL/pgSQL过程语言增强
PL/pgSQL在Greenplum 6.0里包括了如下新特性:
1. 为用户抛出的错误附加DETAIL和HINT文本。你还可以在用户返回的错误里指定SQLSTATE和SQLERRMSG(PostgreSQL 8.4引入)
2. RETURN QUERY EXECUTE语句,可以让一个查询动态执行(PostgreSQL 8.4引入)
3. 通过CASE语句来设置条件执行(PostgreSQL 8.4引入)
- 全局死锁检测
之前的Greenplum通过对表加写锁来避免执行UPDATE和DELETE时出现全局死锁。这个方法虽然避免了全局死锁,但是并发更新的性能很差。Greenplum 6里引入了全局死锁检测。该检测进程收集并分析集群中的锁等待信息,如果发现了死锁则杀死造成死锁的进程并报错。全局死锁检测仅仅放开了Heap表的并发限制。该特性默认是关闭的, 可以通过设置GUC参数打开。
Greenplum 灵活扩展
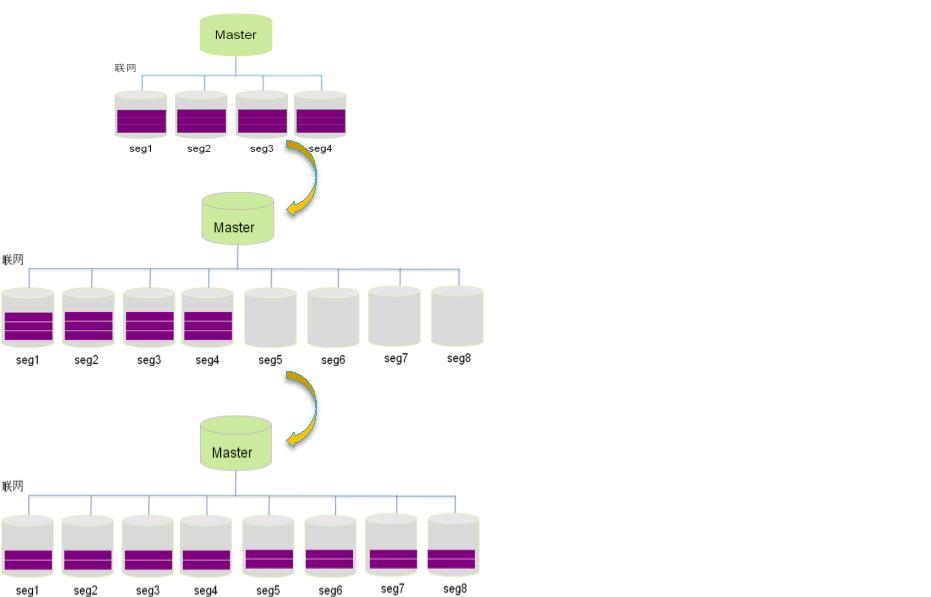
Greenplum 采用的无共享/MPP 架构并基于 x86 架构服务器,可通过扩展节点来线性增长集群的容量和处理性能,满足用户不同阶段的持续发展需求。与传统的 SMP 不同的是,Greenplum 可根据业务发展需要来对数据库进行灵活的扩张,例如刚开始时部署了 4 个节点就能满足当前业务需求,3 年后数据量和应用都增加了,可以增加节点将系统的容量和处理能力线性提高,另外,因为Greenplum 运行在开放 X86 服务器上,所以用户享受到低成本扩张的优势;Greenplum 的扩容操作是动态且在线的,系统扩容在 1 分钟内就可完成,系统扩容后,原有数据将自动在所有节点上重分布,重分布的过程可以由用户指定在每天系统空闲的时候进行,数据重分布中,系统服务不中断;
Greenplum 数据库集群扩容方式:
Greenplum 易用性
Greenplum 数据库对于使用和开发者的易用性体现在以下几个方面:
- SQL标准的普遍支持
Greenplum 数据库普遍支持 ANSI SQL 标准,包括对 SQL 92、SQL 99、SQL 2003 OLAP 等标准的支持,熟悉 DB2 或 Oralce 的开发人员很容易转为Greenplum 数据库开发,原有的 DB2 代码只需做部分少量修改就能迁移到Greenplum 数据库上运行。
- 并行处理由系统自动完成,无需人工干预
所有数据均匀分布到所有节点,每个节点都计算自己的部分数据,所以并行处理无需人工干预,系统自动完成。
- 无需复杂的调优需求,只需要加载数据和查询
– DBA 工作量极少,无需复杂的调优工作和维护工作。
- 客户端访问及第三方工具支持
– 完全支持数据库技术接口标准,例如: SQL, ODBC, JDBC, OLEDB、
LIBPQ、ECPG 等。同时,广泛地支持各个 BI 和 ETL 软件工具;
– 可利用 SQL、C、PERL、Python 等开发语言扩展数据库功能;
– PgadminIII 提供可视化的数据库操作和管理,psql 提供命令方式行的操作方式。
Greenplum 易维护性
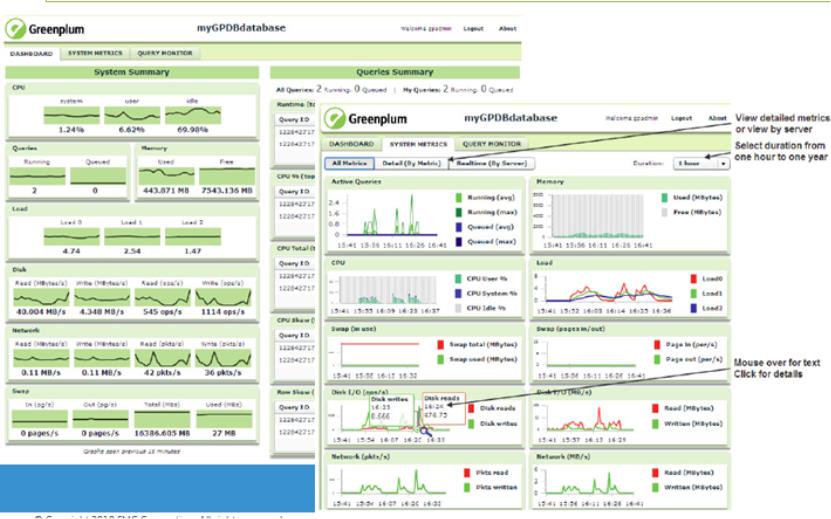
Greenplum 提供强互动的基于 Web 的性能监控工具,支持实时和历史
视图查询:
• 资源利用情况 ,CPU/内存/网络 IO/磁盘 IO
• SQL 运行内部情况
• 节点运行情况
• 系统整体健康情况
Greenplum 还支持以下方式的监控:
1) 邮件通知,将数据库异常事件发送给 DBA
2) 支持 SNMP 协议,与第三方网管集成,将数据库运行情况发送到客户统一的监控平台。
Greenplum其他技术创新
- 混合的存储和执行(按列或按行)
Greenplum 发明支持混合按列或按行存储数据,每张表或表分区可以由管理员根据应用需要,分别指定存储和压缩方式。
基于这个功能,用户可以对任何表或表分区选择按行或按列存储数据和处理方式。这些是在建表或表分区的 DDL 语句中配置的,只需在建表或表分区时指定:
这个功能基于 Greenplum 的多态维数据存储技术。

- 负载管理(Workload Management)
具有系统资源管控能力,并且可控制给各个查询分配各自系统资源。允许管理员指派资源队列,从而管理数据仓库的队列进入执行情况。在运行的查询的优先级可以随时调整。
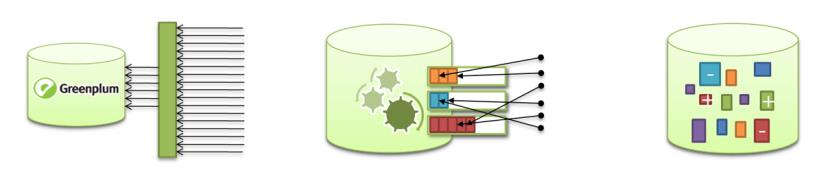
- 灵活的外部数据访问
数据仓库软件可在任意外部数据源上并行运行常规 SQL,不论外部数据源的位置,格式或存储介质。
- 库内数据压缩
利用业界领先的压缩技术,进一步提高性能,并极大地节省了数据存储空间。DBA 可以在同一张表采用不同的压缩算法,依赖于数据内容,最终可获得 4-20倍的空间节省,并且同时获得相应有效 I/O 性能提升。
- 多层次表分区能力
允许灵活地按照时间、范围、值域划分表分区。表分区由 DDL 设定,分区层级不限。数据仓库软件的查询优化器自动从查询执行计划中略去不涉及的表分区。
- 索引功能
Greenplum 支持各种数据库索引技术,包括 B-Tree,Bitmap 等等。按列存储、按行存储数据库表都支持索引。
- 原生 MapReduce 功能
MapReduce 由 Google 发明,已被证实为一个高扩展性的文本非结构化数据分析的技术。Greenplum 的并行数据库软件核心可原生运行 MapReduce 程序。
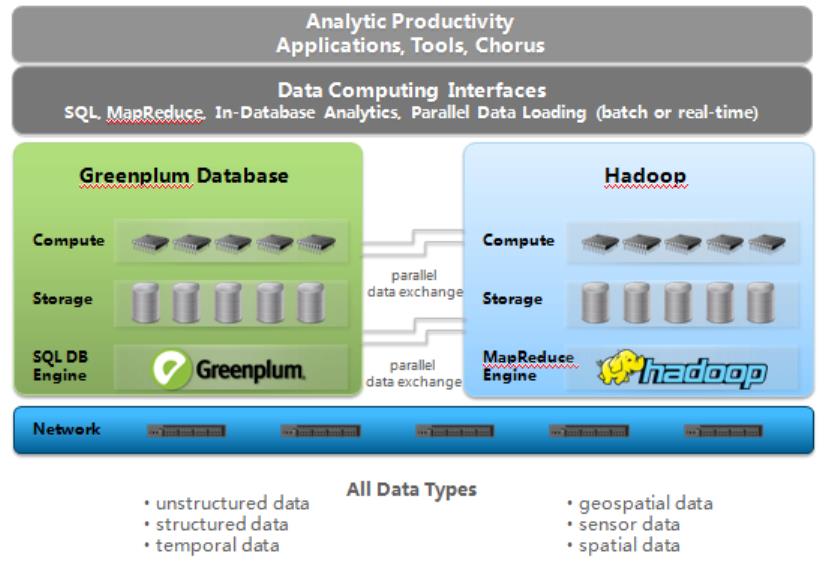
- 与 Hadoop 的集成
Greenplum 通过独有的 GPXF 协议与 Hadoop 无缝集成,GreenplumDatabase + Pivotal Hadoop 能够满足结构化数据和非结构化数据的处理和分析,Greenplum 的 SQL 引擎通过 GPXF 协议,以外部表的方式可直接对 Hadoop 数据进行查询分析,实现 RDBMS 的语法应用于 Hadoop HDFS数据,如 join,aggreate,sort……
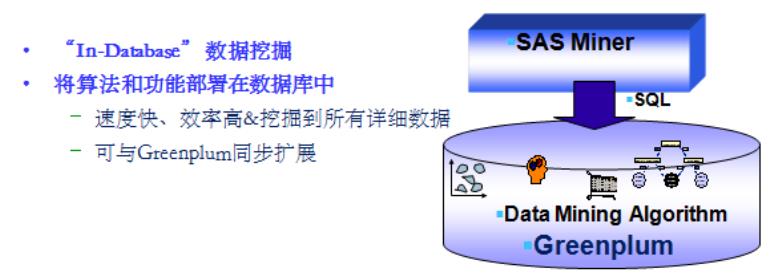
- “In-database” analytic
Greenplum 与 SAS、R、Madlib 数据挖掘工具集成,实现“In-database”数据分析和挖掘计算,数据无需搬动到库外就可进行快捷的挖掘分析,还可利用 MPP 并行计算大幅提高数据分析的性能,并且“In-database”分析性能在系统扩展时可以线性提高。
Greenplum 投入成本可控
本是可控的、架构稳定、扩充灵活。Pivotal Greenplum 数据集市系统采用开放式 X86 PC 服务器作为基础硬件平台,并且未来可基于开放式 X86 进行线性扩展,总体来看是数据集市投入成
系统的硬件扩展为线性扩展,例如增加一倍的硬件,就能提升接近一倍的性能,用户可根据业务的发展需要在未来进行系统扩展,系统的软件扩费要低于线性比例费用;(如从 3T 的许可升到 10T,小于原来 7T 的费用)。
Greenplum 与云计算融合
随着大数据、云计算技术的流行,数据库产品依托于云计算平台,构建数据即服务(DBaaS)逐渐成为趋势。DBaaS 可以为企业提供一个灵活的、可扩展的、按需服务的数据平台,根据工作负载弹性伸缩,动态满足各类用户需求,降低管理成本。对云计算的支持一直是 Greenplum 产品研发方向,针对私有云和公有云 Greenplum 都提供了支持。在私有云方面,目前Greenplum 支持各类虚拟化技术(如:VMWare、OpenStack 等),可以直接部署在企业内部的 IaaS 云平台之上,如:国泰航空使用Greenplum,基于 VMWare 的 IaaS 产品,构建数据仓库库集群,面向整个企业提供服务。未来 Greenplum 还将与 CloudFoundry紧密集成,提供对 PaaS 云平台的支持。在公有云方面,目前 Amazon AWS、阿里云等业界主要的公有云已经提供了 Greenplum 数据库服务。借助 Greenplum 对云计算技术的支持,客户无论选择私有云还是公有云,都可以构建云端的 Greenplum 数据库集群,一方面,在实现资源池化、弹性伸缩;另一方面,最大限度降低管理运维成本。
